Wirtualizacja QEMU/KVM (libvirt) na Debian Linux
Spis treści
Prawdopodobnie dla większości użytkowników linux'a, wirtualizacja kojarzy się w zasadzie z jednym
oprogramowaniem, tj. VirtualBox. Niby strona VBox'a podaje, że jest on na licencji GPL-2 ale
w Debianie nie ma go w głównym repozytorium (jest on obecny w sekcji contrib ). Problem z
VirtualBox'em jest taki, że wymaga on kompilatora Open Watcom, który już wolnym
oprogramowaniem nie jest. VBox też nie jest jedynym oprogramowaniem, które na linux można
wykorzystać w roli hiperwizora do obsługi maszyn wirtualnych. Jest o wiele lepsze rozwiązanie,
mianowicie QEMU, które jest w stanie zrobić użytek z maszyny wirtualnej kernela (Kernel Virtual
Machine, KVM) i realizować dokładnie to samo zadanie, które zwykł ogarniać VirtualBox.
Wirtualizacja na bazie QEMU/KVM jest w pełni OpenSource, co ucieszy pewnie fanów wolnego i
otwartego oprogramowania, choć zarządzanie maszynami wirtualnymi odbywa się za sprawą konsoli.
Oczywiście, osoby które korzystają z VirtualBox'a zdają sobie sprawę, że to narzędzie oferuje
graficzny menadżer maszyn wirtualnych (Virtual Machine Manager, VMM), który usprawnia i znacznie
ułatwia zarządzanie wirtualnymi maszynami. Jeśli GUI jest dla nas ważnym elementem środowiska pracy
i nie uśmiecha nam się konfigurować maszyn wirtualnych przy pomocy terminala, to jest i dobra
wiadomość dla takich osób, bo istnieje virt-manager , który jest dość rozbudowanym menadżerem
maszyn wirtualnych pozwalającym na ich tworzenie, konfigurowanie i zarządzanie nimi przy
wykorzystaniu graficznego interfejsu użytkownika. W tym artykule postaramy się skonfigurować
naszego Debiana w taki sposób, by przygotować go do pracy z maszynami wirtualnymi posługując się
qemu/libvirt/virt-manager .
Terminy związane z wirtualizacją
Szukając informacji na necie dotyczących QEMU/KVM nie sposób nie natknąć się na szereg dziwnych i trudnych słów związanych z różnymi technikami wirtualizacji. Poniżej zostały zebrane i opisane te częściej wykorzystywane sformułowania, a to z tego względu, że w sporej części te terminy są mylone, nierozróżniane lub stosowane zamiennie i ciężko jest się czasem połapać o czym ktoś pisze czy mówi.
Różnica między emulacją a wirtualizacją
Terminy emulacja i wirtualizacja są podobne, choć mają w stosunku do siebie kilka różnic. Emulacja polega na tym, że jeden system imituje inny system. Dla przykładu, jeśli jakiś kawałek oprogramowania działa w systemie ARM (np. Android) i nie działa jednocześnie na innym systemie, np. naszym domowym PC (x86), to możemy sprawić, że nasz domowy PC będzie emulował działanie systemu ARM, tak by ten kawałek oprogramowania uruchomił się również na systemie x86. Gdybyśmy w tej samej sytuacji chcieli skorzystać z wirtualizacji (zamiast emulacji), to musielibyśmy nasz system x86 podzielić na dwa wirtualne systemy: x86 i ARM. Każdy z tych wirtualnych systemów byłby niezależnym kontenerem oprogramowania mającym swój własny dostęp do programowych zasobów (CPU, RAM, dysk i sieć). Każdy z tych systemów można by też niezależnie uruchomić ponownie. Te wirtualne maszyny zachowywałyby się dokładnie tam samo jak prawdziwy sprzęt fizyczny, przez co aplikacje/systemy operacyjne uruchomione w ich obrębie nie byłby w stanie zauważyć jakiejkolwiek różnicy.
W przypadku emulacji, to oprogramowanie zastępuje sprzęt tworząc odpowiednie środowisko sprzętowe. Niestety taki zabieg sprawia, że spora część cykli procesora jest oddelegowana do obsługi procesu emulacji, przez co tylko część cykli procesora może być przeznaczona na przeprowadzanie faktycznych obliczeń. W ten sposób spada dość znacznie wydajność emulowanych aplikacji/OS. Emulacja jest bardzo przydatna przy projektowaniu oprogramowania na wiele systemów operacyjnych -- można to zrobić w obrębie jednej maszyny fizycznej, co znacznie ułatwia testowanie, ogranicza koszty i przyśpiesza cały proces.
W przypadku wirtualizacji, szybka maszyna fizyczna z dużą ilością pamięci RAM oraz wystarczającą ilością przestrzeni dyskowej może być podzielona na wiele mniejszych maszyn wirtualnych, z której każda ma własne zasoby sprzętowe. Każda z tych maszyn może zostać wdrożona jako osobny serwer hostujący jakieś usługi, np. serwer WWW czy email. W taki sposób te zasoby obliczeniowe, które szły na obsługę emulacji, są teraz dostępne i można je w pełni wykorzystać, co może pomóc w znacznym cięciu kosztów.
W emulowanych środowiskach istnieje potrzeba zastosowania programowego połączenia zapewniającego interakcję z fizycznym sprzętem. W przypadku wirtualizacji, ten dostęp do sprzętu odbywa się bezpośrednio. Mimo, że wirtualizacja jest na ogół szybszą opcją, to jest ona ograniczona przez oprogramowanie będące w stanie działać na podległym sprzęcie fizycznym.
Typy hiperwizorów
Rozróżnia się trzy typy hiperwizorów. Pierwszym z nich jest natywny hiperwizor, który jest aplikacją uruchomioną bezpośrednio na sprzęcie (bare metal), przykładowo Xen, VMWare ESX. Ten typ wymaga dedykowanych sterowników sprzętu dla hiperwizora. Drugim typem jest hostowany hiperwizor, który to jest uruchamiany w obrębie jakiegoś systemu operacyjnego, przykładowo VirtualBox, QEMU, KVM. Tutaj zarządzanie sterownikami leży po stronie systemu operacyjnego hosta. Trzecim typem hiperwizora jest sam system operacyjny, na którym mogą być uruchamiane różnego rodzaju kontenery, przykładowo chroot, LXC czy Docker.
Techniki wirtualizacji
W przypadku procesorów możemy mieć do czynienia z kilkoma technikami wirtualizacji, tj. z pełną wirtualizacją, parawirtualizacją oraz wirtualizacją wspomaganą sprzętowo. Poniżej jest prosta grafika (źródło) obrazująca różnice pomiędzy tymi technikami wirtualizacji procesora:
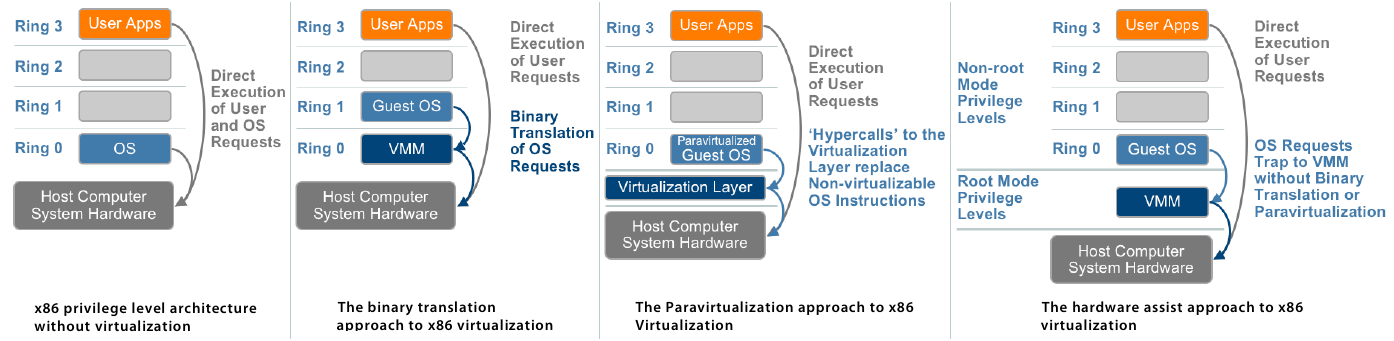
Kolejno od lewej: brak wirtualizacji, pełna wirtualizacja, parawirtualizacja i jako ostatnia wirtualizacja wspomagana sprzętowo.
Jeśli zaś chodzi o terminy wykorzystane w tej powyższej grafice, to:
OS-- system operacyjny (kernel) hosta.Guest OS-- system operacyjny gościa (maszyny wirtualnej).User Apps-- aplikacje przestrzeni/poziomu użytkownika.VMM-- Monitor/Menadżer Maszyn Wirtualnych (Virtual Machine Monitor/Manager), choć w powszechnym użyciu stosuje się częściej termin hiperwizor (Hypervisor).Virtualization Layer-- warstwa wirtualizacji hiperwizora.Ring 0-3-- pierścień ochrony. Im wyższy numer, tym aplikacja działająca w jego obrębie ma mniejsze uprawnienia. WRing 3działają procesy przestrzeni użytkownika, wRing 2iRing 1działają sterowniki urządzeń, wRing 0działa system operacyjny (kernel).Direct execution-- bezpośrednie wykonywanie zapytań aplikacji przestrzeni/poziomu użytkownika.Binary translation-- binarna translacja zapytań systemu operacyjnego.Hipercall-- wywołanie hiperwizora umożliwiające bezpośrednią komunikację systemu operacyjnego gościa z warstwą wirtualizacji hiperwizora. Hypercall dla hiperwizora jest w zasadzie tym samym co syscall (wywołanie systemowe) dla kernela.Non-root Mode Privilege Levels-- tryby nieadministracyjne poziomów uprzywilejowania (Ring 0-3).Root Mode Privilege Levels-- tryb administracyjny poziomów uprzywilejowania (Ring -1).
Pełna wirtualizacja
Pełną wirtualizację (full virtualization) można osiągnąć przez zastosowanie binarnej translacji zapytań systemu operacyjnego (binary translation of OS requests) w połączeniu z bezpośrednim wykonywaniem zapytań aplikacji przestrzeni/poziomu użytkownika (direct execution of user requests). W takim przypadku system operacyjny gościa jest w pełni oddzielony od sprzętu, na którym działa, przez warstwę wirtualizacji -- ma własny wirtualny BIOS, wirtualne urządzenia i zwirtualizowane zarządzanie pamięcią. System gościa nie jest świadomy faktu bycia wirtualizowanym i nie wymaga żadnych modyfikacji do poprawnego działania. Pełna wirtualizacja jest w zasadzie jedyną opcją, która nie wymaga pomocy od sprzętu lub systemu operacyjnego przy wirtualizacji instrukcji wrażliwych (zmieniających konfigurację zasobów OS) i uprzywilejowanych (powodujących przerwania i wywołania systemowe). Hiperwizor tłumaczy wszystkie instrukcje systemu operacyjnego (kernela) w locie i buforuje wyniki w cache dla przyszłego wykorzystania, podczas gdy instrukcje przestrzeni użytkownika nie są w żaden sposób zmieniane i są wykonywane z prędkością natywną. Pełna wirtualizacja oferuje najlepszą izolację i bezpieczeństwo maszyn wirtualnych. Dodatkowo, ten sam system gościa może bez problemu działać zarówno na maszynie wirtualnej jak i bezpośrednio na natywnym sprzęcie hosta.
Parawirtualizacja
Z parawirtualizacją (paravirtualization, OS Assisted Virtualization) mamy do czynienia wtedy, gdy system operacyjny gościa (maszyny wirtualnej) komunikuje się z hiperwizorem w celu poprawy wydajności. Parawirtualizacja wymaga modyfikacji jądra systemu operacyjnego w celu zastąpienia niemożliwych do zwirtualizowania instrukcji wywołaniami hiperwizora (hypercall). Hiperwizor zapewnia także interfejsy hiperwołań (hypercalls) dla innych krytycznych operacji jądra operacyjnego, takich jak zarządzanie pamięcią, obsługa przerwań i utrzymywanie czasu. W przypadku parawirtualizacji mamy mniejszy narzut (overhead) związany z samym zadaniem wirtualizacji niż przy pełnej wirtualizacji, choć zysk wydajnościowy w porównaniu do niej zależy w dużej mierze od obciążenia, któremu podda się system gościa. Przykładem parawirtualizacji jest projekt Xen, który wirtualizuje procesor i pamięć wykorzystując do tego zmodyfikowane jądro linux'a oraz wirtualizuje I/O przy użyciu niestandardowych sterowników urządzeń systemu operacyjnego gościa.
Wirtualizacja wspomagana sprzętowo
Wirtualizacja wspomagana sprzętowo umożliwia pełne odizolowanie maszyn wirtualnych i osiągana jest
przez implementowanie dodatkowych rozszerzeń bezpośrednio w procesorach. Procesory Intel dysponują
technologią VT-x, a procesory AMD mają AMD-V. Te technologie dodają nowe uprzywilejowane
instrukcje wirtualizacji dla hiperwizora, które pozwalają mu działać w nowym trybie
administracyjnym (root mode) poniżej Ring 0 (zwykle stosowany termin Ring -1 ). W taki sposób,
system operacyjny gościa jest w stanie wykonywać natywnie operacje przeznaczone dla Ring 0
(dostęp do sprzętu) bez wpływania w żaden sposób na inne systemy gościa czy też system operacyjny
hosta. W tej technice wirtualizacji wrażliwe i uprzywilejowane instrukcje są automatycznie
przechwytywane przez hiperwizor, przez co nie ma potrzeby stosowania już binarnej translacji czy
też parawirtualizacji.
Wirtualizacja pamięci RAM
Procesor nie jest jedynym elementem, który trzeba poddać wirtualizacji. Podobnie trzeba postąpić w przypadku pamięci RAM, wliczając w to dzielenie fizycznej pamięci operacyjnej oraz dynamiczny jej przydział maszynom wirtualnym. Wirtualizacja pamięci maszyny wirtualnej jest bardzo podobna do obsługi pamięci wirtualnej zapewnianej przez nowsze systemy operacyjne. Aplikacje widzą ciągłą przestrzeń adresową, która niekoniecznie jest powiązana z podstawową pamięcią fizyczną w systemie. System operacyjny zachowuje odwzorowania numerów stron wirtualnych na numery stron fizycznych przechowywanych w tablicach stron. Wszystkie nowoczesne procesory x86 zawierają jednostkę zarządzania pamięcią (Memory Management Unit, MMU) i bufor TLB (Translation Lookaside Buffer) w celu optymalizacji wydajności pamięci wirtualnej. Aby uruchomić wiele maszyn wirtualnych na jednym systemie hosta, wymagany jest dodatkowy poziom wirtualizacji pamięci. Innymi słowy, by być w stanie obsłużyć system gościa należy zwirtualizować MMU. System gościa nadal kontroluje mapowanie adresów wirtualnych do pamięci gościa, ale system gościa nie może mieć bezpośredniego dostępu do rzeczywistej pamięci operacyjnej maszyny hosta. Hiperwizor jest odpowiedzialny za mapowanie pamięci fizycznej gościa na rzeczywistą pamięć maszyny hosta i wykorzystuje cieniste tablice stron (shadow page tables) by to mapowanie przyśpieszyć. Hiperwizor wykorzystuje sprzętowy TLB do mapowania pamięci wirtualnej bezpośrednio do pamięci maszyny hosta aby uniknąć dwóch poziomów translacji przy każdym dostępie. Gdy system gościa zmienia mapowanie pamięci, hiperwizor aktualizuje cieniste tablice stron aby umożliwić bezpośrednie wyszukiwanie.
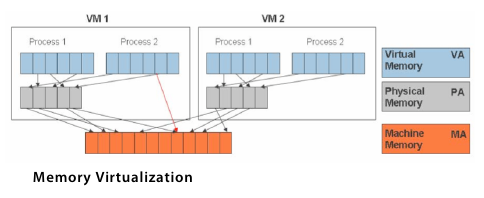
Wirtualizacja urządzeń oraz operacji I/O
Poza wirtualizacją procesora i pamięci wymagana jest także wirtualizacja urządzeń oraz operacji wejścia/wyjścia (I/O). Ten proces obejmuje zarządzanie zapytaniami I/O między urządzeniami wirtualnymi a współdzielonym sprzętem fizycznym. Programowa wirtualizacja I/O daje wiele możliwości i znacznie upraszcza zarządzanie urządzeniami. Dla przykładu, wirtualne interfejsy sieciowe i przełączniki tworzą wirtualne sieci pomiędzy maszynami wirtualnymi, przez co nie korzystają z fizycznych interfejsów sieciowych i nie obciążają w żaden sposób sieci hosta. Kluczem do efektywnej wirtualizacji I/O jest zachowanie zalet wirtualizacji przy jednoczesnym ograniczeniu dodatkowego wykorzystania procesora do minimum. Hiperwizor wirtualizuje sprzęt fizyczny i przedstawia każdej maszynie wirtualnej ustandaryzowany zestaw urządzeń wirtualnych. Te urządzenia wirtualne efektywnie emulują dobrze znany sprzęt i tłumaczą zapytania maszyny wirtualnej na zapytania do urządzeń hosta.
Co to jest KVM, QEMU i libvirt
KVM (Kernel-based Virtual Machine), to otwartoźródłowa technologia wirtualizacji wbudowana
bezpośrednio w kernel linux'a, pozwalająca maszynie hosta na uruchomienie wielu izolowanych
środowisk wirtualnych szerzej znanych jako maszyny wirtualne lub systemy gościa. KVM w zasadzie
zapewnia linux'owi możliwości hiperwizora, co oznacza, że szereg jego komponentów, takich jak
zarządzanie pamięcią, planista/dyspozytor (scheduler), stos sieciowy, itp. są dostarczane jako
część kernela linux. Maszyny wirtualne są w ten sposób zwykłymi procesami w systemie hosta mającymi
dedykowany wirtualny sprzęt, taki jak np. adaptery sieciowe. KVM jest dostarczany w formie modułu
kvm.ko będącym rdzeniem infrastruktury wirtualizacji oraz modułów specyficznych dla rodzaju
procesora, tj. kvm-intel.ko dla procesorów Intel, oraz kvm-amd.ko dla procesorów AMD.
QEMU to Quick Emulator jest to w zasadzie emulator maszyn i zarazem wirtualizator (hostowany hiperwizor). Gdy QEMU jest wykorzystywany w roli emulatora, to jest on w stanie uruchomić pojedyncze aplikacje (albo też i całe systemy operacyjne) przeznaczone na konkretne maszyny (np. ARM), na innych maszynach, np. na nasz domowy PC. Jeśli zaś QEMU jest wykorzystywany w roli hiperwizora, to jest on w stanie wykonywać kod gościa (maszyny wirtualnej) bezpośrednio na procesorze hosta, co przyśpiesza znacząco wydajność maszyny wirtualnej, która mocno zbliżona jest do tej natywnej, tak jakby system maszyny wirtualnej działał bezpośrednio na maszynie hosta. QEMU w roli hiperwizora jest w stanie robić użytek z technologi wirtualizacji oferowanej przez kernel linux'a i w ten sposób kod binarny maszyny wirtualnej może być wykonywany bez emulacji CPU i problemów z nią związanymi (słaba wydajność). Maszyna wirtualna może zostać uruchomiona przy pomocy wiersza poleceń qemu, gdzie można też określić wszystkie niezbędne opcje konfiguracyjne dla QEMU.
Libvirt z kolei jest interfejsem, który tłumaczy konfigurację zapisaną w plikach XML na wywołania
qemu . Libvirt dostarcza także demona, który jest w stanie skonfigurować procesy potomne qemu w
taki sposób, by nie potrzebowały one uprawnień administratora root. By uruchomić maszynę wirtualną,
libvirt jest wykorzystywany do zestawienia procesu qemu dla każdej takiej maszyny osobno.
Czy mój komputer/procesor/linux wspiera wirtualizację
Zanim przejdziemy do głównej części tego artykułu jaką jest konfiguracja maszyn wirtualnych pod
linux, trzeba sobie zadać pytanie czy nasz komputer (a w zasadzie jego procesor) posiada wsparcie
dla sprzętowej wirtualizacji. Ten krok sprowadza się w zasadzie do przejrzenia pliku
/proc/cpuinfo w poszukiwaniu określonej flagi. Jeśli mamy procesor Intel, to szukamy za vmx
(Virtual Machine Extensions), a jeśli AMD, to za svm (Secure Virtual Machine). Poniżej są
informacje na temat procesora Intel i5-3320M (a konkretnie jednego z jego rdzeni), który figuruje w
moim ThinkPad T430:
# cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 58
model name : Intel(R) Core(TM) i5-3320M CPU @ 2.60GHz
stepping : 9
microcode : 0x21
cpu MHz : 1375.278
cache size : 3072 KB
physical id : 0
siblings : 4
core id : 0
cpu cores : 2
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36
clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx rdtscp lm constant_
tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf
pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid
sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_
lm cpuid_fault epb pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept
vpid fsgsbase smep erms xsaveopt dtherm ida arat pln pts md_clear flush_l1d
vmx flags : vnmi preemption_timer invvpid ept_x_only flexpriority tsc_offset vtpr mtf
vapic ept vpid unrestricted_guest
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs itlb_
multihit srbds
bogomips : 5188.31
clflush size : 64
cache_alignment : 64
address sizes : 36 bits physical, 48 bits virtual
power management:
Jak widać, flaga vmx jest obecna, zatem ten procesor ma wsparcie dla sprzętowej wirtualizacji.
Można także posłużyć się narzędziem lscpu :
# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 36 bits physical, 48 bits virtual
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 2
Core(s) per socket: 2
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 58
Model name: Intel(R) Core(TM) i5-3320M CPU @ 2.60GHz
Stepping: 9
CPU MHz: 2416.594
CPU max MHz: 3300.0000
CPU min MHz: 1200.0000
BogoMIPS: 5188.07
Virtualization: VT-x
L1d cache: 64 KiB
L1i cache: 64 KiB
L2 cache: 512 KiB
L3 cache: 3 MiB
NUMA node0 CPU(s): 0-3
Vulnerability Itlb multihit: KVM: Mitigation: Split huge pages
Vulnerability L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT vulnerable
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Full generic retpoline, IBPB conditional, IBRS_FW,
STIBP conditional, RSB filling
Vulnerability Srbds: Vulnerable: No microcode
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat
pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx
rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl
xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor
ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid sse4_1 sse4_2
x2apic popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm
cpuid_fault epb pti ssbd ibrs ibpb stibp tpr_shadow vnmi
flexpriority ept vpid fsgsbase smep erms xsaveopt dtherm ida arat
pln pts md_clear flush_l1d
Jak widać wyżej, na pozycji Virtualization: mamy VT-x , który to odpowiada, za wirtualizację w
procesorach Intel.
Warto dodać w tym miejscu, że istnieje także narzędzie kvm-ok (dostępne w Debianie w pakiecie
cpu-checker ), które jest w stanie zweryfikować wsparcie naszej maszyny dla wirtualizacji i po
części też nakierować nas na prawidłowy trop w przypadku ewentualnych problemów:
# kvm-ok
INFO: /dev/kvm exists
KVM acceleration can be used
Ustawienia BIOS/EFI/UEFI
Praktycznie wszystkie nowsze procesory (produkowane od ponad dekady) posiadają w standardzie
wsparcie dla sprzętowej wirtualizacji. Jeśli jednak w pliku /proc/cpuinfo nie znajdziemy
interesującej nas flagi, to jest niemal pewne, że wirtualizacja została wyłączona na poziomie
EFI/UEFI lub BIOS (w zależności, które z nich posiadamy). W takim przypadku trzeba wejść w
ustawienia BIOS/EFI/UEFI i włączyć stosowne opcje. Poniżej jest przykład z mojego ThinkPad'a T430:
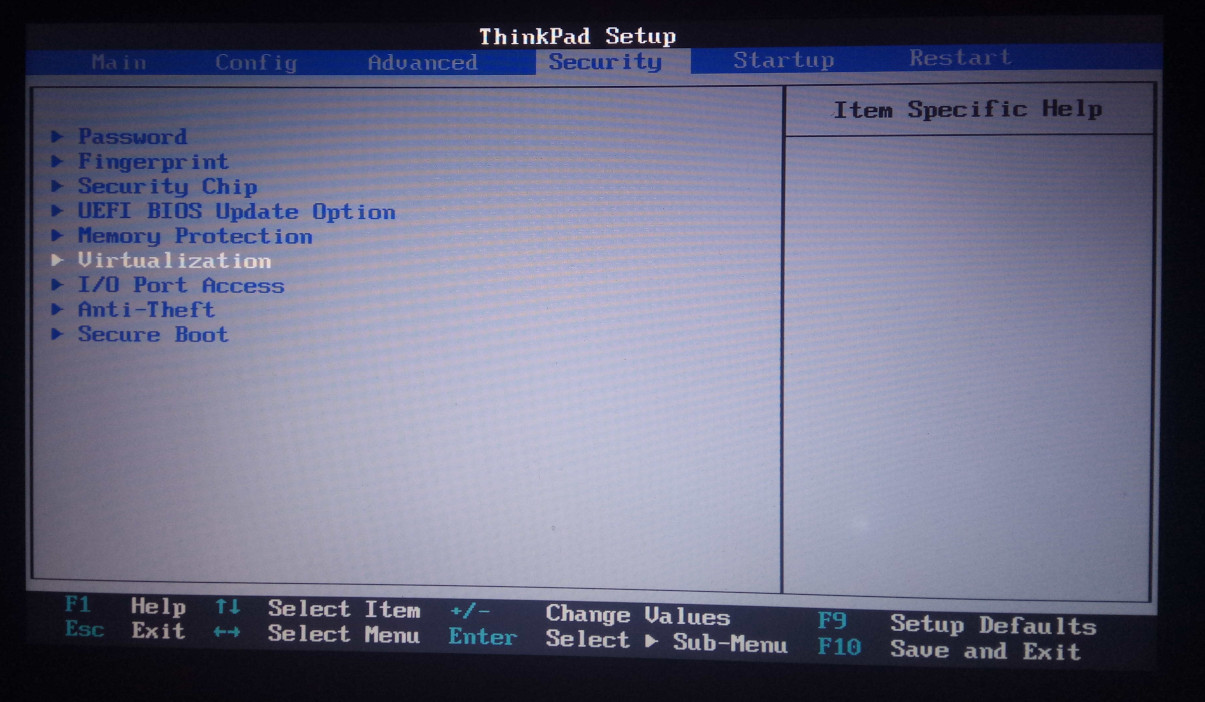
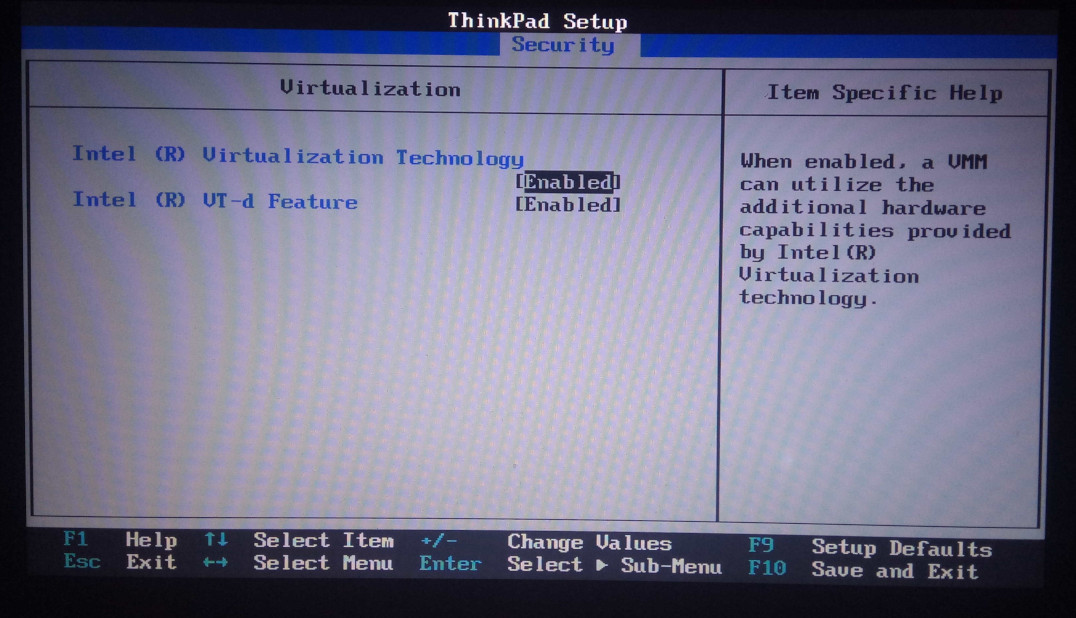
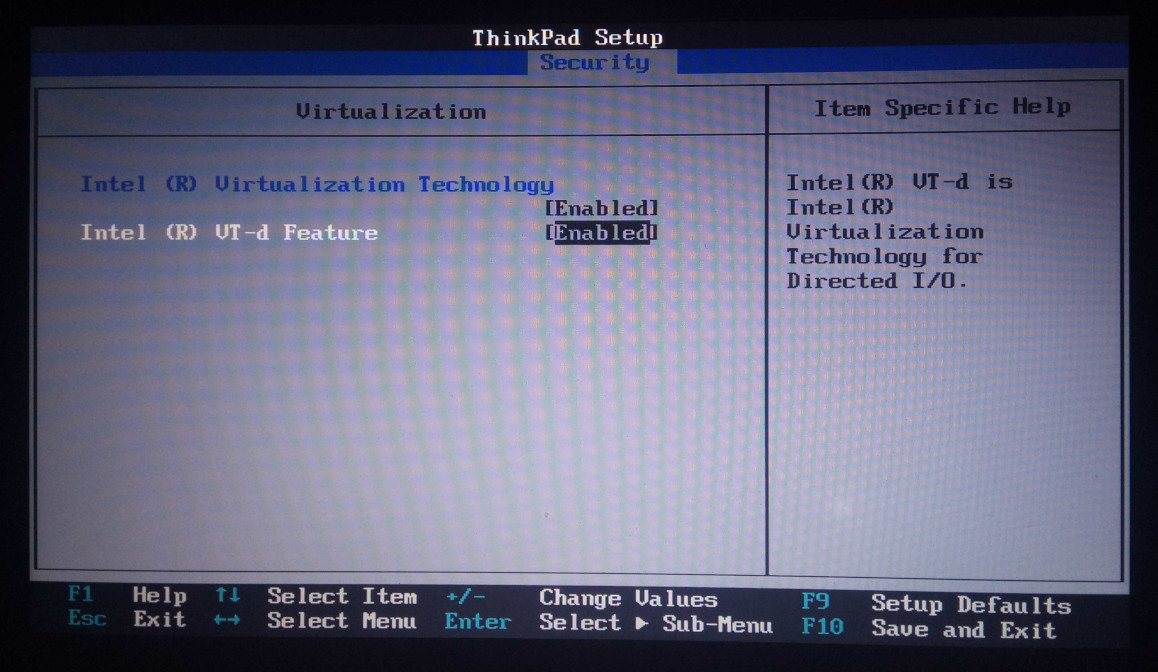
Oczywiście nazwy opcji mogą się nieco różnić ale raczej nie powinniśmy mieć problemów z ustaleniem, które opcje w BIOS/EFI/UEFI odpowiadają za włączenie wirtualizacji.
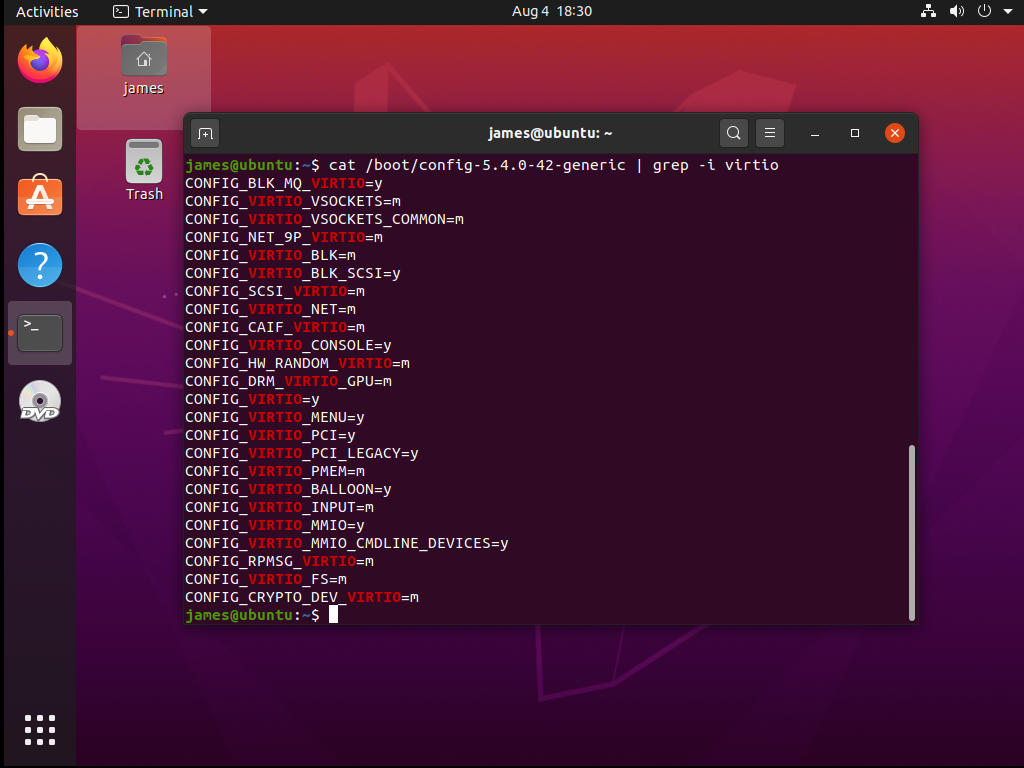
Konfiguracja kernela linux pod QEMU/KVM
Standardowy kernel dystrybucji Debian zawiera praktycznie wszystkie niezbędne opcje, które muszą
być włączone w konfiguracji jądra by wsparcie dla wirtualizacji było zapewnione. Nie trzeba zatem
nic dodatkowo ustawiać. Ja jednak od dłuższego czasu buduję kernel dla swojego laptopa
samodzielnie i do tej pory nie korzystałem na tym sprzęcie z dobrodziejstw jakie zapewniają
maszyny wirtualne. Dlatego też wszystkie opcje kernela dotyczące mechanizmu wirtualizacji (z
CONFIG_VIRTUALIZATION na czele) były wyłączone. Jeśli nasz kernel nie posiada wsparcia dla
wirtualizacji i chcielibyśmy mu je dorobić, to musimy włączyć w nim te poniższe opcje:
CONFIG_VIRTUALIZATION
CONFIG_KVM
W zależności od posiadanego procesora (Intel/AMD), trzeba wybrać moduł dla KVM. Jeśli mamy procesor Intela, to dodatkowo zaznaczamy:
CONFIG_KVM_INTEL
Jeśli zaś mamy procesor AMD, to włączamy:
CONFIG_KVM_AMD
Możemy również włączyć obie te opcje ale taki stan rzeczy będzie powodował problemy w przypadku, gdy wkompilujemy te moduły bezpośrednio w jądro. Jeśli faktycznie potrzebujemy obu tych opcji (co raczej nie powinno mieć miejsca w przypadku budowania kernela dla konkretnej maszyny), to lepiej jest pozostawić je w formie modułów.
Poniższe parametry są opcjonalne ale mogą znacznie poprawić wydajność sieci maszyn wirtualnych:
CONFIG_VHOST=y
CONFIG_VHOST_MENU=y
CONFIG_VHOST_NET=y
Upewnijmy się też, że mamy zaznaczone te poniższe opcje, tak by nie było problemu z tworzeniem wirtualnych interfejsów mostka oraz interfejsów sieciowych maszyn wirtualnych:
CONFIG_NETDEVICES
CONFIG_NET_CORE
CONFIG_TUN
CONFIG_BRIDGE
Kernel 64-bit vs. 32-bit
Jeśli chodzi o wirtualizację, to powinniśmy korzystać z 64-bitowego kernela linux. Nie jest to co prawda wymagane ale jeśli chcemy mieć możliwość przydzielić maszynie wirtualnej więcej niż 2 GiB pamięci RAM, to nie damy rady tego uczynić jeśli na maszynie hosta mamy kernel 32-bit.
Warto tutaj zaznaczyć, że mając na maszynie hosta kernel 64-bitowy, w dalszym ciągu możemy tworzyć 32-bitowe maszyny wirtualne. W drugą stronę to nie zadziała, czyli mając 32-bitowy kernel na hoście jesteśmy ograniczeni jedynie do 32-bitowych maszyn wirtualnych.
Konfiguracja HugePages pod QEMU/KVM
Konfiguracja HugePages na potrzeby maszyn wirtualnych QEMU/KVM została opisana w osobnym artykule.
Potrzebne oprogramowanie
Możemy przejść do instalacji potrzebnego oprogramowania, które umożliwi nam tworzenie i zarządzanie maszynami wirtualnymi na naszym linux'ie. Poniżej znajduje się lista pakietów, które trzeba zainstalować w systemie:
# aptitude install \
qemu-system-x86 qemu-system-gui qemu-utils qemu-system-modules-spice \
libvirt-daemon libvirt-daemon-system virt-manager \
bridge-utils dnsmasq-base iptables \
gir1.2-spiceclientgtk-3.0
Pakiety qemu-system-x86 oraz qemu-kvm
W wielu miejscach na necie można się spotkać z instalacją w systemie pakietu qemu-kvm . Niemniej
jednak, obecnie w Debianie (Sid) instalacja tego pakietu kończy się poniższym komunikatem:
# aptitude install qemu-kvm
The following NEW packages will be installed:
qemu-kvm
0 packages upgraded, 1 newly installed, 0 to remove and 29 not upgraded.
Need to get 76.4 kB of archives. After unpacking 114 kB will be used.
The following packages have unmet dependencies:
qemu-system-x86 : Breaks: qemu-kvm but 1:5.0-8 is to be installed
The following actions will resolve these dependencies:
Keep the following packages at their current version:
1) qemu-kvm [Not Installed]
Accept this solution? [Y/n/q/?]
Winny jest tutaj pakiet qemu-system-x86 , który to z kolei ma w swoich zależnościach:
Breaks: qemu-kvm
Replaces: qemu-kvm
Provides: qemu-kvm, qemu-system-i386, qemu-system-x86-64
I to właśnie qemu-system-x86 powinien być instalowany w miejsce qemu-kvm .
Pakiet qemu-system-gui
Pakiet qemu-system-gui dostarcza z kolei lokalny graficzny interfejs użytkownika (GTK) oraz
bakendy audio dla pełnej emulacji systemu (pakiety qemu-system-* , m.in. qemu-system-x86 ,
który będzie wykorzystywany w tym artykule).
Pakiet qemu-utils
W pakiecie qemu-utils znajduje się m.in. narzędzie qemu-img , które umożliwia operowanie na
obrazach maszyn wirtualnych, wliczając w to zmianę ich rozmiaru czy kompresję danych, tak by te
obrazy nie zajmowały niepotrzebnie zbyt dużo miejsca na dysku. Jeśli mamy zamiar operować na
obrazach maszyn wirtualnych, to dobrze jest ten pakiet również sobie zainstalować.
Pakiety libvirt-daemon oraz libvirt-daemon-system
Pakiet libvirt-daemon dostarcza demona libvirtd zarządzającego mechanizmami wirtualizacji
(QEMU, KVM, XEN, OpenVZ, LXC, oraz VirtualBox). Z kolei w pakiecie libvirt-daemon-system znajduje
się konfiguracja dla demona libvirtd . Dodatkowo, pakiet libvirt-daemon-system pociąga w
zależnościach również libvirt-daemon-system-systemd lub libvirt-daemon-system-sysv . W tym
przypadku, jako że używany jest systemd, to libvirt-daemon-system-systemd zostanie zainstalowany.
Ten pakiet zawiera jedynie zależności, które umożliwiają libvirt współpracowanie z systemd.
Pakiet virt-manager
W pakiecie virt-manager znajduje się aplikacja (w stadium eksperymentalnym) umożliwiająca
graficzne zarządzanie maszynami wirtualnymi. W zasadzie każdy aspekt pracy związany z
tworzeniem i zarządzaniem maszynami wirtualnymi (albo też ich ogromną część) można ogarnąć przy
pomocy aplikacji virt-manager . Z tych ciekawszych rzeczy można jeszcze wspomnieć, że
virt-manager posiada wbudowany klient SPICE/VNC.
Pakiety bridge-utils, dnsmasq-base i iptables
By nieco ułatwić konfigurację sieci, libvirt ma zdefiniowaną NAT'owską sieć 192.168.122.1/24 i
wszystkie maszyny wirtualne domyślnie do tej sieci będą przypisane. By połączenie było realizowane
za pomocą NAT, potrzebny będzie wirtualny interfejs mostka, którym to libvirt będzie zarządzał.
Potrzebne są zatem stosowne narzędzia dostępne w pakiecie bridge-utils . Każda maszyna wirtualna
otrzyma swój adres IP za pomocą protokołu DHCP, i do tego celu potrzebny będzie nam serwer DHCP, w
roli którego wystąpi dnsmasq dostępny w Debianie w pakiecie dnsmasq-base . By komunikacja
maszyn wirtualnych ze światem zewnętrznym przez sieci była możliwa, potrzebny będzie filtr pakietów
iptables oraz odpowiednia jego konfiguracja.
Trzeba tutaj zaznaczyć, że ta domyślna sieć dla maszyn wirtualnych nie jest domyślnie włączona i nie jest obligatoryjne instalowanie któregokolwiek z tych trzech pakietów. Jeśli jednak chcielibyśmy korzystać z tych predefiniowanych ustawień sieci, to te pakiety trzeba doinstalować.
Kolejna sprawa, to sam filtr pakietów. Debian oraz inne dystrybucje linux'a przeszły jakiś czas
temu z iptables na nftables . Jeśli wykorzystujemy narzędzie nft do konfiguracji zapory
sieciowej, to ta domyślna konfiguracja sieci nie będzie kompatybilna i trzeba będzie ręcznie
skonfigurować reguły, by sieć w maszynach wirtualnych działała jak należy (o tym później).
Pakiet gir1.2-spiceclientgtk-3.0
W przypadku, gdy podczas startu maszyny wirtualnej zobaczymy na ekranie komunikat Error connecting to graphical console: Error opening Spice console, SpiceClientGtk missing. , co wygląda mniej
więcej tak:
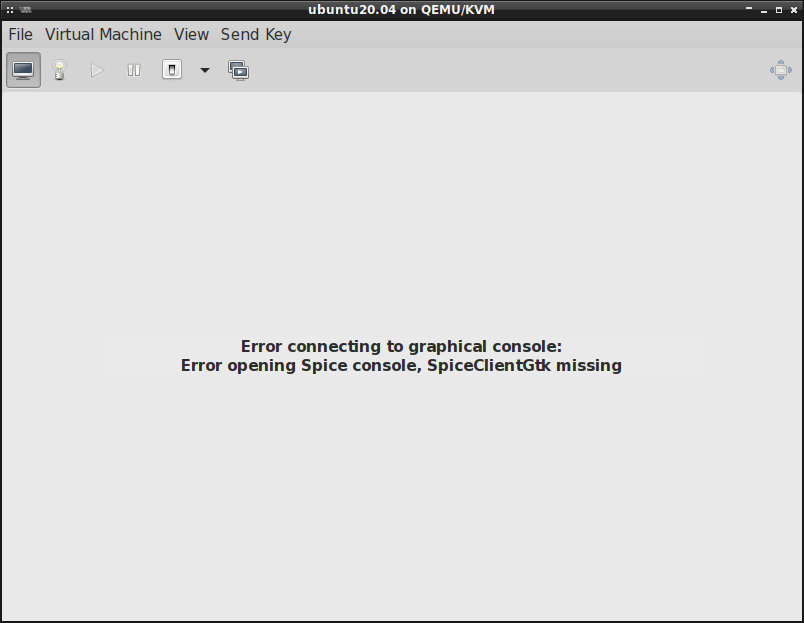
Oznacza to, że brakuje w systemie pakietu gir1.2-spiceclientgtk-3.0 .
Co co ciekawe, ja u siebie miałem zainstalowany pakiety spice-client-gtk , który ma w
zależnościach gir1.2-spiceclientgtk-3.0 , a mimo to, ten powyższy błąd ciągle występował. Problem
ustał dopiero po odinstalowaniu pakietu spice-client-gtk i bezpośrednim zainstalowaniu
gir1.2-spiceclientgtk-3.0 . To tak na wypadek, gdyby ktoś miał podobny problem z uruchamianiem
maszyn wirtualnych.
Pakiet qemu-system-modules-spice
Po postawieniu świeżego systemu, chcąc uruchomić jedną z moich maszyn wirtualnych okazało się, że taka akcja kończy się poniższym komunikatem:
Error starting domain: unsupported configuration: domain configuration does not support video model 'qxl'
Traceback (most recent call last):
File "/usr/share/virt-manager/virtManager/asyncjob.py", line 72, in cb_wrapper
callback(asyncjob, *args, **kwargs)
File "/usr/share/virt-manager/virtManager/asyncjob.py", line 108, in tmpcb
callback(*args, **kwargs)
File "/usr/share/virt-manager/virtManager/object/libvirtobject.py", line 57, in newfn
ret = fn(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/share/virt-manager/virtManager/object/domain.py", line 1402, in startup
self._backend.create()
File "/usr/lib/python3/dist-packages/libvirt.py", line 1373, in create
raise libvirtError('virDomainCreate() failed')
libvirt.libvirtError: unsupported configuration: domain configuration does not support video model 'qxl'
Zainstalowanie pakietu qemu-system-modules-spice niweluje ten problem.
Grupy w linux a operowanie na maszynach wirtualnych
Po zainstalowaniu potrzebnego oprogramowania, w linux'ie powinny pojawić się dodatkowe grupy, tj.
kvm , libvirt oraz libvirt-qemu . W wielu tutorialach poświęconych QEMU/KVM pojawiają się
sugestie by dodać zwykłego użytkownika do każdej z tych trzech grup. Wygląda jednak na to, że nie
jest to konieczne i do tego jeszcze może nieco zagrażać bezpieczeństwu systemu.
Jeżeli nie dodamy zwykłego użytkownika do żadnej z wyżej wymienionych grup, to np. przy
uruchamianiu virt-manager (przy łączeniu się z demonem libvirtd ) będziemy ciągle pytani o
hasło administratora:
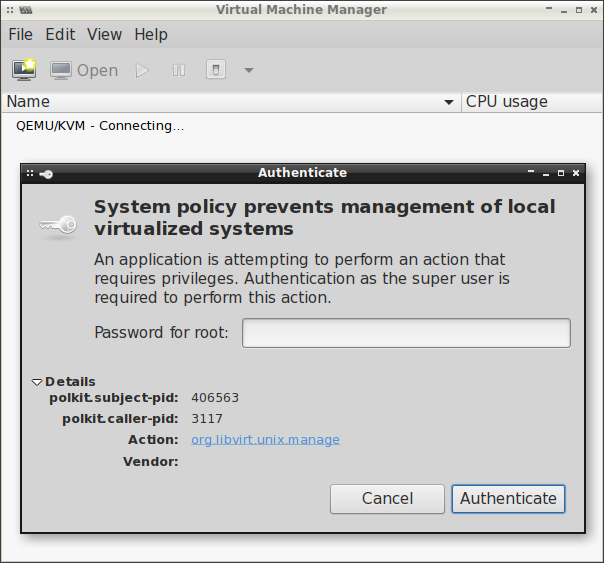
Grupa libvirt
By nie być pytanym o hasło za każdym razem jak będziemy uruchamiać virt-manager czy korzystać z
narzędzia virsh (przykładowo virsh -c qemu:///system 'list --all' ), to musimy dodać zwykłego
użytkownika do grupy libvirt :
# adduser morfik libvirt
Wymaga tego polityka policykit, która jest określona w pliku
/usr/share/polkit-1/rules.d/60-libvirt.rules :
# cat /usr/share/polkit-1/rules.d/60-libvirt.rules
// Allow any user in the 'libvirt' group to connect to system libvirtd
// without entering a password.
polkit.addRule(function(action, subject) {
if (action.id == "org.libvirt.unix.manage" &&
subject.isInGroup("libvirt")) {
return polkit.Result.YES;
}
});
Grupa libvirt-qemu
Jeśli zaś chodzi o grupę libvirt-qemu , to systemowe procesy QEMU/KVM są uruchomione jako
użytkownik/grupa libvirt-qemu (można ten aspekt dostosować w pliku /etc/libvirt/qemu.conf ),
przez co szereg plików w katalogu /var/lib/libvirt/ posiada użytkownika/grupę libvirt-qemu :
# tree -fpugs /var/lib/libvirt/
/var/lib/libvirt
├── [drwx--x--x root root 4096] /var/lib/libvirt/boot
├── [drwxr-xr-x root root 4096] /var/lib/libvirt/dnsmasq
│ ├── [-rw-r--r-- root root 0] /var/lib/libvirt/dnsmasq/default.addnhosts
│ ├── [-rw------- root root 598] /var/lib/libvirt/dnsmasq/default.conf
│ ├── [-rw-r--r-- root root 0] /var/lib/libvirt/dnsmasq/default.hostsfile
│ ├── [-rw-r--r-- root root 87] /var/lib/libvirt/dnsmasq/virbr0.macs
│ └── [-rw-r--r-- root root 211] /var/lib/libvirt/dnsmasq/virbr0.status
├── [drwx--x--x root root 4096] /var/lib/libvirt/images
│ └── [-rw-r--r-- libvirt-qemu libvirt-qemu 4337762304] /var/lib/libvirt/images/ubuntu20.04-small.qcow2
├── [drwxr-x--- libvirt-qemu libvirt-qemu 4096] /var/lib/libvirt/qemu
│ ├── [drwxr-x--- libvirt-qemu libvirt-qemu 4096] /var/lib/libvirt/qemu/channel
│ │ └── [drwxr-x--- libvirt-qemu libvirt-qemu 4096] /var/lib/libvirt/qemu/channel/target
│ │ └── [drwxr-x--- libvirt-qemu libvirt-qemu 4096] /var/lib/libvirt/qemu/channel/target/domain-19-ubuntu20.04
│ │ └── [srwxrwxr-x libvirt-qemu libvirt-qemu 0] /var/lib/libvirt/qemu/channel/target/domain-19-ubuntu20.04/org.qemu.guest_agent.0
│ ├── [drwxr-xr-x libvirt-qemu libvirt-qemu 4096] /var/lib/libvirt/qemu/checkpoint
│ ├── [drwxr-x--- libvirt-qemu libvirt-qemu 4096] /var/lib/libvirt/qemu/domain-19-ubuntu20.04
│ │ ├── [-rw------- libvirt-qemu libvirt-qemu 32] /var/lib/libvirt/qemu/domain-19-ubuntu20.04/master-key.aes
│ │ └── [srwxrwxr-x root root 0] /var/lib/libvirt/qemu/domain-19-ubuntu20.04/monitor.sock
│ ├── [drwxr-xr-x libvirt-qemu libvirt-qemu 4096] /var/lib/libvirt/qemu/dump
│ ├── [drwxr-xr-x libvirt-qemu libvirt-qemu 4096] /var/lib/libvirt/qemu/nvram
│ ├── [drwxr-xr-x libvirt-qemu libvirt-qemu 4096] /var/lib/libvirt/qemu/ram
│ ├── [drwxr-xr-x libvirt-qemu libvirt-qemu 4096] /var/lib/libvirt/qemu/save
│ └── [drwxr-xr-x libvirt-qemu libvirt-qemu 4096] /var/lib/libvirt/qemu/snapshot
└── [drwx------ root root 4096] /var/lib/libvirt/sanlock
15 directories, 9 files
W katalogu /var/lib/libvirt/ są przechowywane obrazy maszyn wirtualnych, jak i również informacje
o uruchomionych i aktualnie działających w systemie hosta maszynach wirtualnych. Zwykły użytkownik
niekoniecznie powinien mieć swobodny dostęp do tych plików i standardowo go nie posiada i lepiej by
tak zostało. Dlatego też lepiej nie dodawać zwykłego użytkownika do grupy libvirt-qemu .
Grupa kvm
Z kolei grupa kvm potrafi zapewnić zwykłym użytkownikom dostęp do urządzenia /dev/kvm , które
jest niezbędne do uruchamiania maszyn wirtualnych na bazie KVM. UDEV nadaje stosowne uprawnienia
urządzeniu /dev/kvm za pośrednictwem pliku /lib/udev/rules.d/50-udev-default.rules , który to
ma określoną tę poniższą regułę:
KERNEL=="kvm", GROUP="kvm", MODE="0660", OPTIONS+="static_node=kvm"
Zatem dodanie użytkownika do grupy kvm sprawi, że będzie miał on dostęp (zapis/odczyt) do tego
urządzenia. Niemniej jednak, w systemach mających na pokładzie systemd jest dostępny również plik
/lib/udev/rules.d/70-uaccess.rules , który zawiera tę poniższą linijkę:
SUBSYSTEM=="misc", KERNEL=="kvm", TAG+="uaccess"
Ma ona dodany tag uaccess , który to jest używany przez logind do dynamicznego nadawania praw
dostępu do określonych urządzeń lokalnym użytkownikom via ACL (Access Control List). Ta powyższa
linijka dotyczy urządzenia /dev/kvm , przez co nie ma potrzeby ręcznego dodawania użytkownika do
grupy kvm . Możemy się o tym przekonać wydając poniższe polecenia:
$ egrep kvm /etc/group
kvm:x:136:
$ getfacl /dev/kvm
getfacl: Removing leading '/' from absolute path names
# file: dev/kvm
# owner: root
# group: kvm
user::rw-
user:morfik:rw-
group::rw-
mask::rw-
other::---
Zatem użytkownik morfik nie jest dodany do grupy kvm ale ma uprawnienia zapisu i odczytu
urządzenia /dev/kvm .
Trzeba tutaj wyraźnie zaznaczyć, że dostęp do urządzenia /dev/kvm jest przyznany jedynie w
przypadku, gdy sesja jest lokalna i do tego aktywna. Ten fakt możemy zweryfikować w poniższy sposób:
$ loginctl list-sessions
SESSION UID USER SEAT TTY
1 1000 morfik seat0 tty4
1 sessions listed.
$ loginctl show-session 1
...
Remote=no
Active=yes
...
Jeśli któryś z tych dwóch warunków nie zostanie spełniony, np. przejdziemy do konsoli TTY1 via
CTRL+ALT+F1, to nasza sesja graficzna stanie się nieaktywna i dostęp do urządzenia /dev/kvm
zostanie odebrany. Możemy się o tym przekonać logując się na TTY1 na innego użytkownika niż ten
zalogowany w sesji graficznej (np. root) i ponownie wydając poniższe polecenie:
# getfacl /dev/kvm
getfacl: Removing leading '/' from absolute path names
# file: dev/kvm
# owner: root
# group: kvm
user::rw-
group::rw-
mask::rw-
other::---
Nie ma już tutaj linijki z user:morfik:rw- , która była wcześniej. Oczywiście jak tylko powrócimy
do sesji graficznej, to te uprawnienia automatycznie zostaną ponownie nadane.
Nadanie uprawnień zwykłemu użytkownikowi by mógł wejść w interakcję z urządzeniem /dev/kvm
niezbędne jest jedynie w przypadku, gdy chcemy bezpośrednio korzystać z KVM. W tym artykule jednak
wykorzystywany będzie głównie virt-manager , który to robi użytek z libvirt . W takim przypadku
proces qemu-system-x86_64 jest uruchomiony jako użytkownik libvirt-qemu , którego to grupą
główną jest kvm :
$ cat /etc/group | grep kvm
kvm:x:136:
$ cat /etc/passwd | grep 136
libvirt-qemu:x:64055:136:Libvirt Qemu,,,:/var/lib/libvirt:/usr/sbin/nologin
Dlatego też proces qemu-system-x86_64 będzie miał zawsze dostęp do urządzenia /dev/kvm , przez
co my w zasadzie nie musimy dodawać swojego użytkownika do grupy kvm , o ile oczywiście
zamierzamy korzystać (bezpośrednio lub pośrednio) z libvirt lub korzystamy z systemd.
Tworzenie maszyn wirtualnych QEMU/KVM
Przyszła już chyba najwyższa pora by wziąć się za same maszyny wirtualne. Niemniej jednak,
przydałoby się pierw jakąś utworzyć. Do tego celu potrzebny nam będzie w zasadzie kawałek nośnika
instalacyjnego -- tego samego, który zwykliśmy wykorzystywać do instalacji linux'a na regularnym
desktopie czy laptopie. W tym przypadku został wykorzystany obraz Ubuntu 20.04. Po pobraniu
stosownego pliku, odpalamy virt-manager i łączymy się z qemu:///system (domyślnie jest
utworzony):
 |
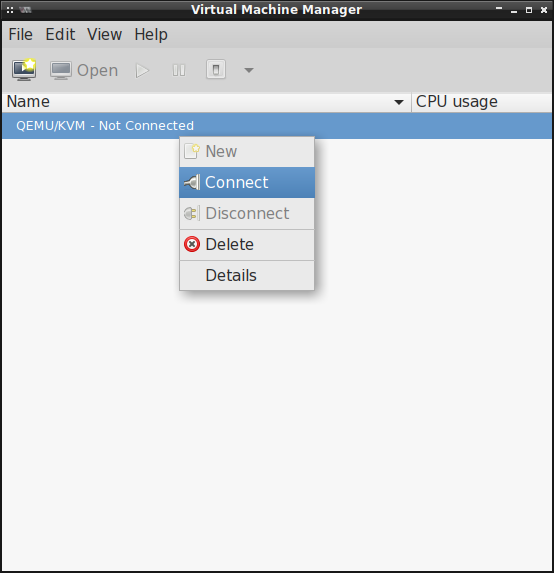 |
Następnie klikając w ikonkę monitora tworzymy maszynę wirtualną:
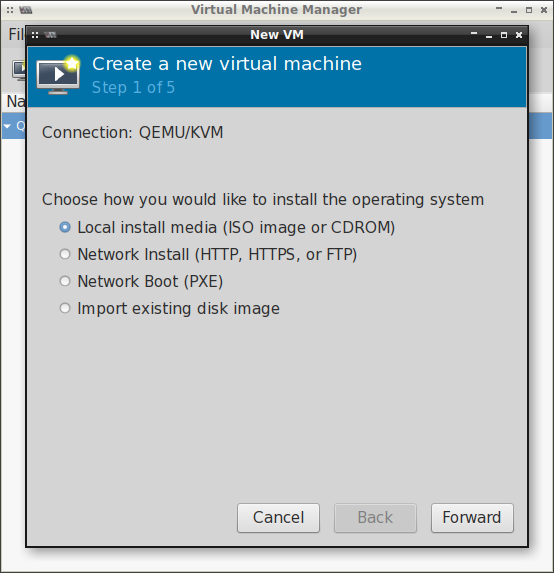
Wybieramy lokalne medium instalacyjne, tj. ten obraz ISO, który pobraliśmy wcześniej:
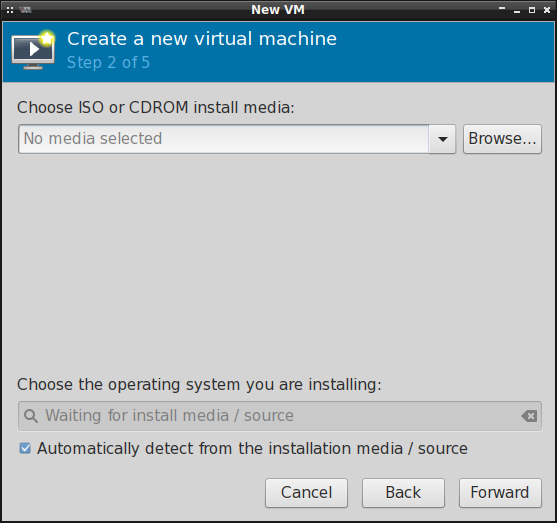
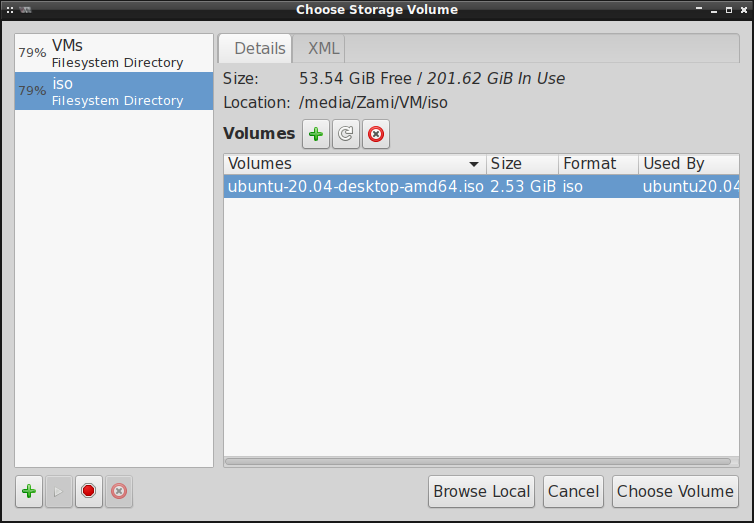
Jeśli wskazaliśmy jeden z tych bardziej popularnych obrazów ISO, to virt-manager powinien
rozpoznać z jakim obrazem ma do czynienia:
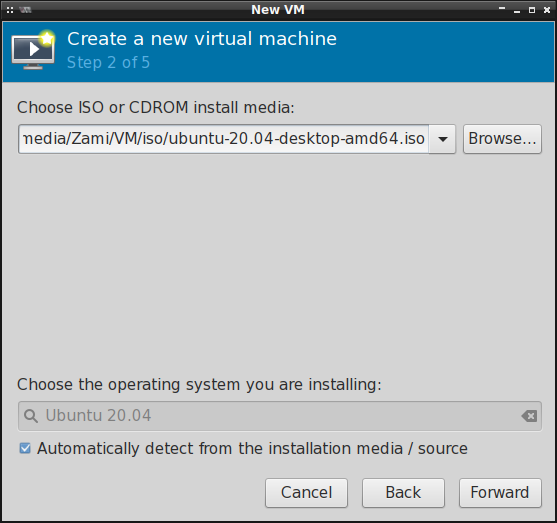
Wstępnie też konfigurujemy przydział pamięci operacyjnej RAM oraz rdzeni procesora:
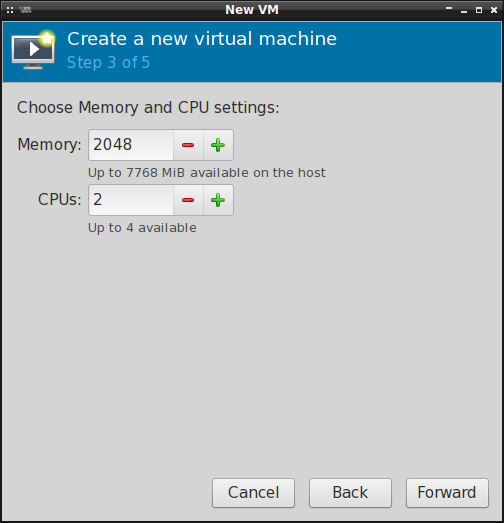
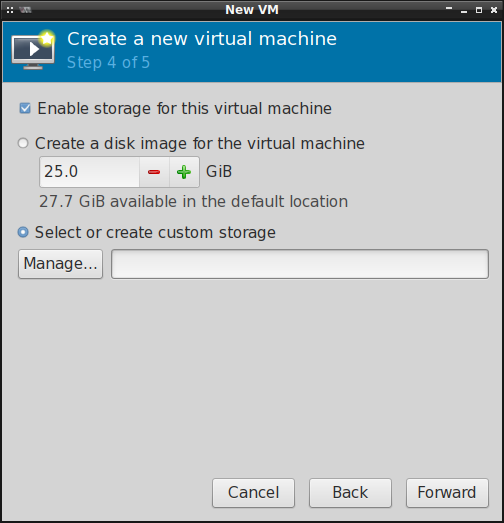
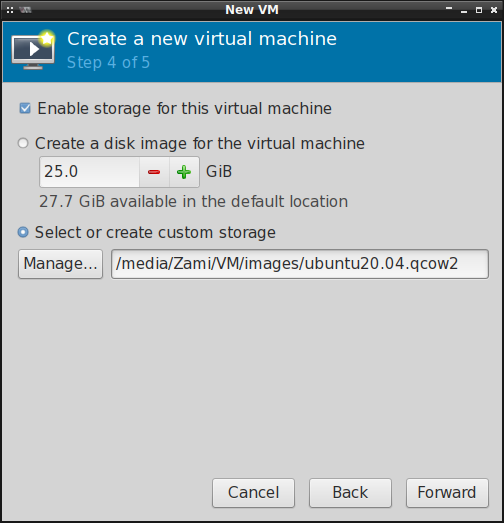
Następnie wybieramy format obrazu maszyny wirtualnej oraz ilość przestrzeni dyskowej, którą będzie
ta maszyna mogła wykorzystać. Jeśli nie chcemy tworzyć obrazów maszyn wirtualnych na partycji
systemowej w katalogu /var/lib/libvirt/images/ , to musimy zdefiniować lokalizację ręcznie:
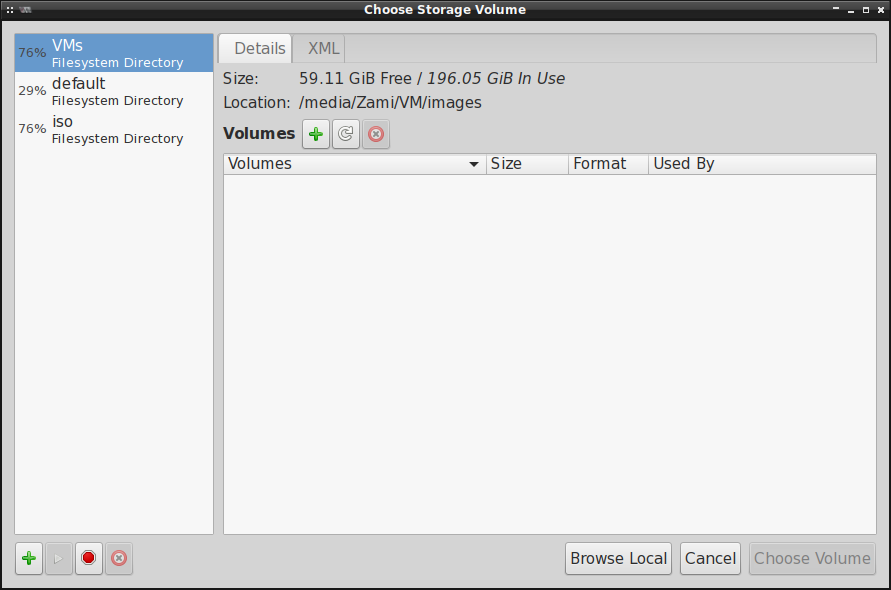
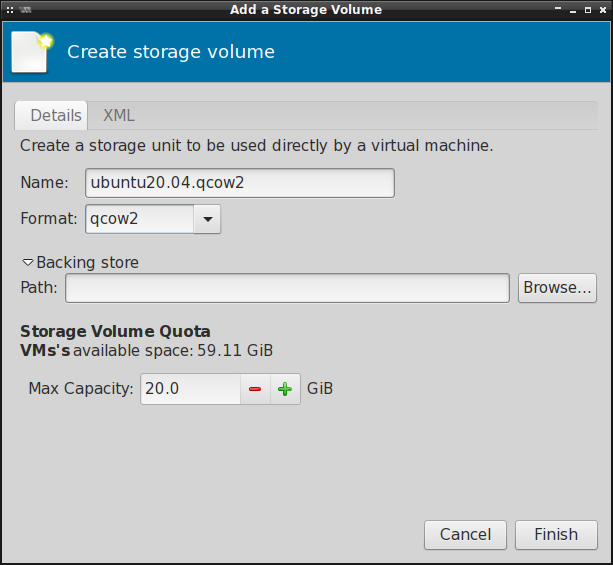
Klikamy teraz w ten zielony plusik obok Volumes , dodajemy nowy obraz w formacie .qcow2 i
określamy jego rozmiar:
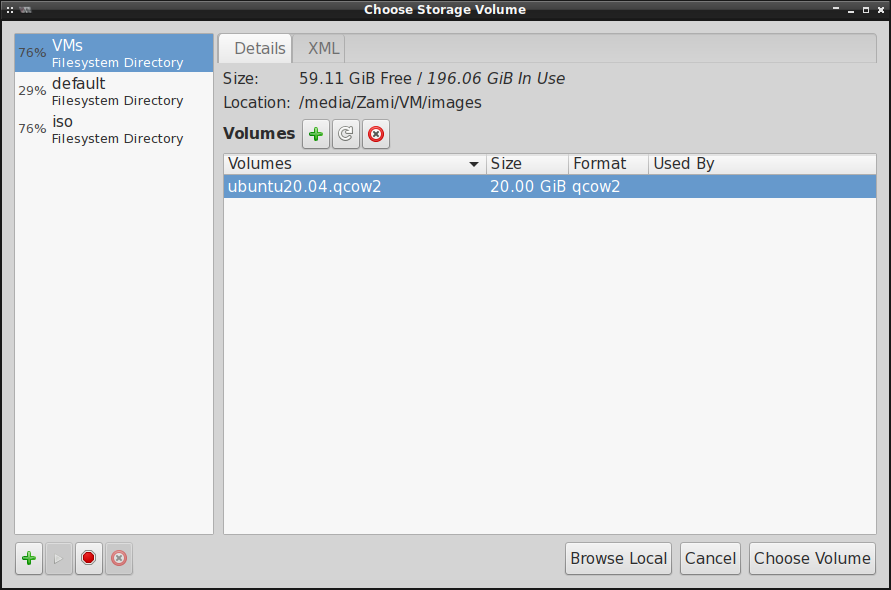
Następnie wybieramy tak utworzony obraz maszyny wirtualnej:
Pozostał nam ostatni krok, tj. nazwanie maszyny wirtualnej i przypisanie jej do konkretnej sieci.
Standardowe ustawienia sieci powinny wystarczyć chyba, że korzystamy z nftables . W takim
przypadku trzeba będzie nieco przerobić domyślną sieć lub utworzyć nową "otwartą":
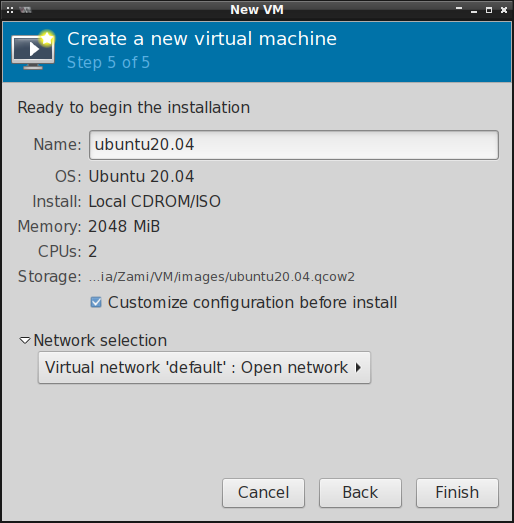
Warto też zaznaczyć opcję Customize configuration before install , co pozwoli nam skonfigurować
wstępnie maszynę wirtualną zanim rozpocznie się proces instalacji systemu operacyjnego.
Instalacja systemu operacyjnego maszyny wirtualnej
Po wstępnym skonfigurowaniu parametrów maszyny wirtualnej możemy w końcu już puścić instalację
systemu operacyjnego, który w tej maszynie będzie działał. Zapisujemy zatem wszystkie ustawienia
(jeśli jeszcze tego nie zrobiliśmy) i wciskamy przycisk Begin Installation . Chwilę po jego
przyciśnięciu, powinniśmy zobaczyć znajome okienko instalacji Ubuntu:
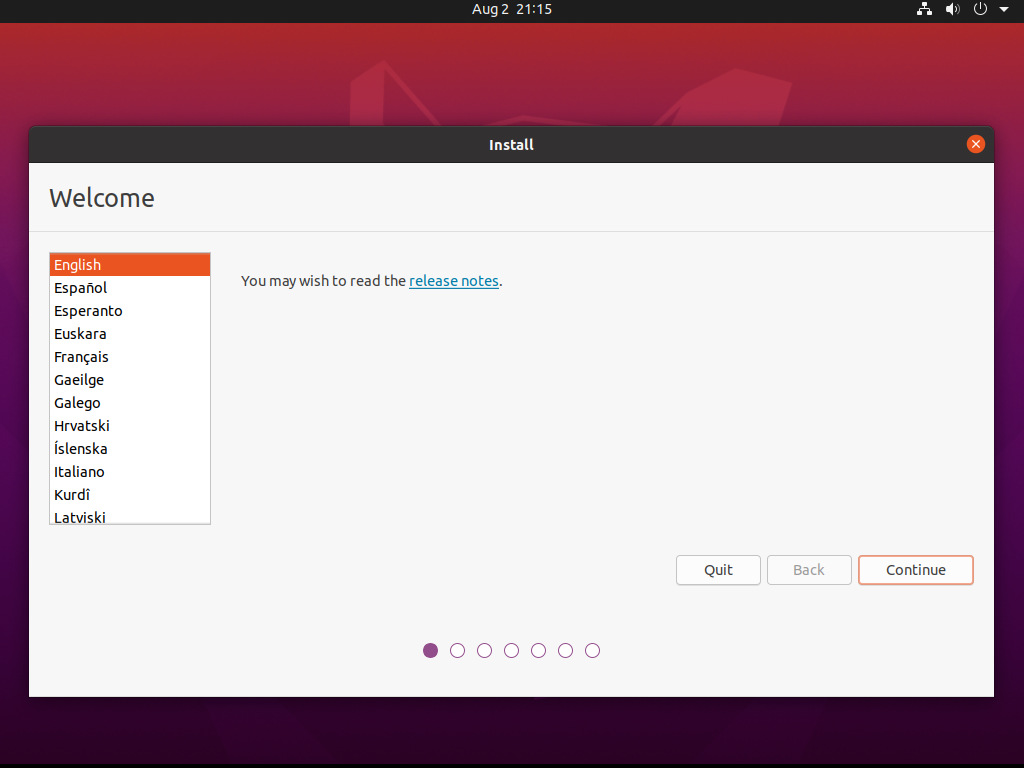
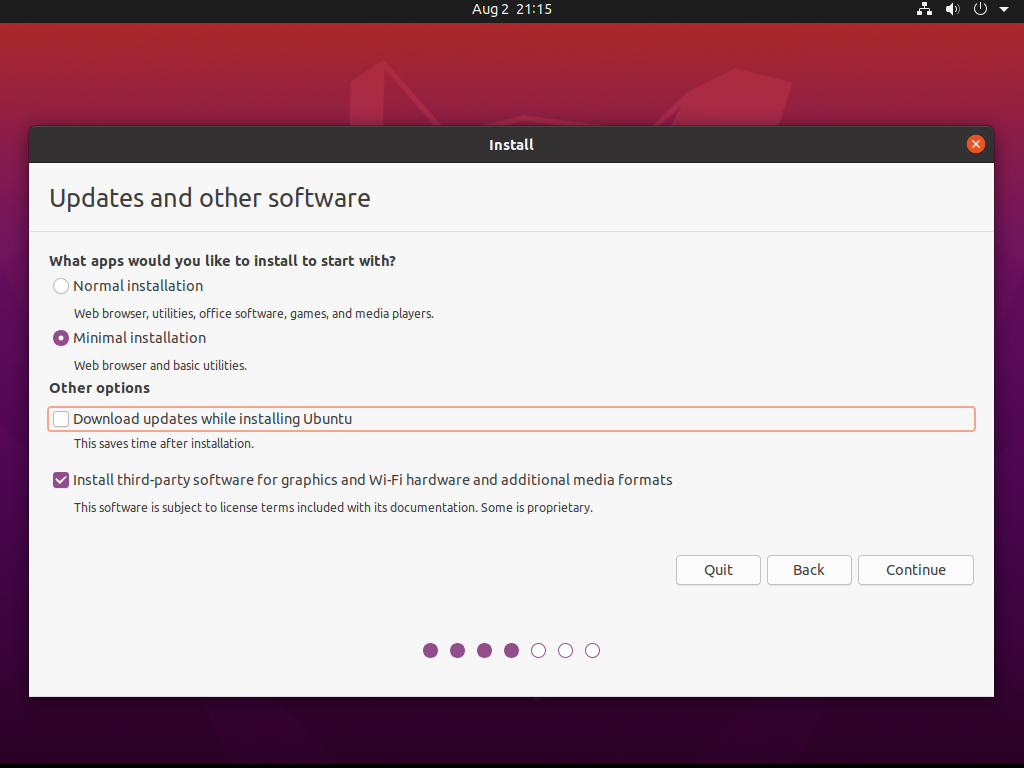
Możemy wybrać minimalną instalację w celu zaoszczędzenia miejsca w obrazie maszyny wirtualnej:
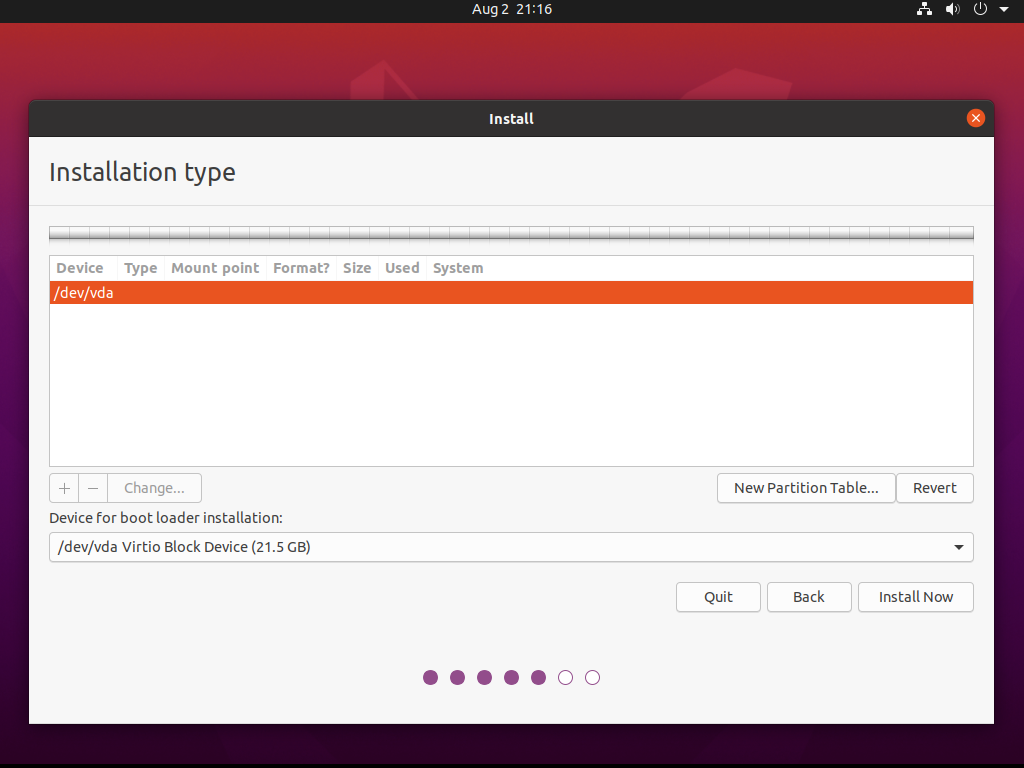
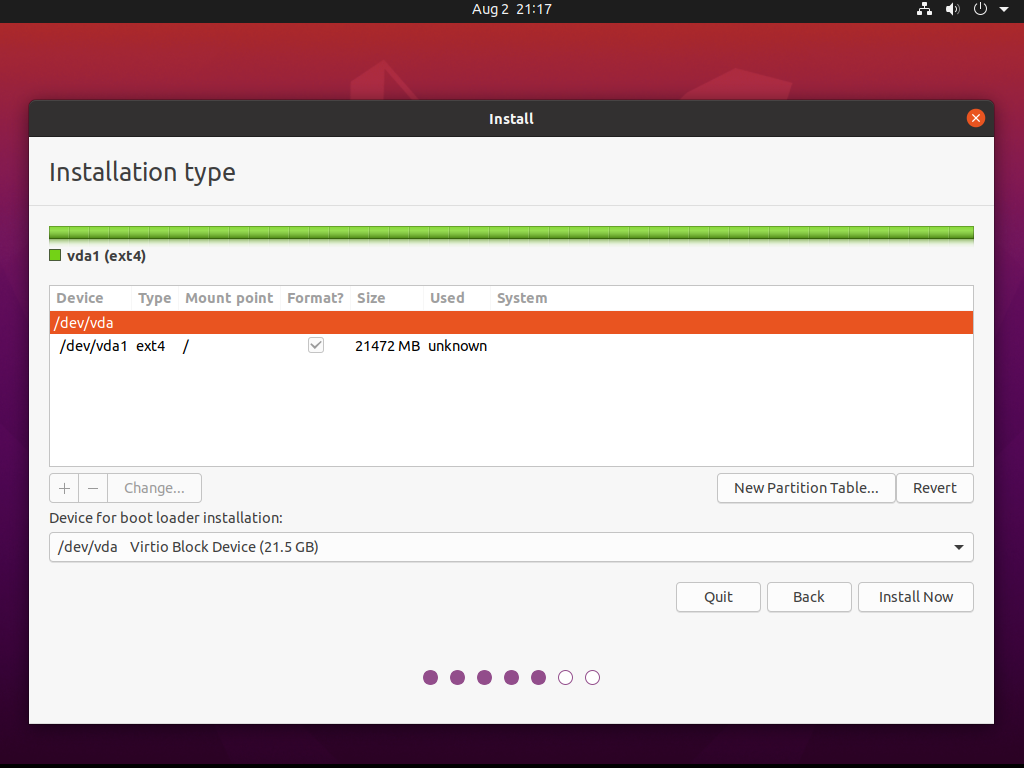
Tworzymy też tablicę partycji oraz jedną partycję EXT4 z punktem montowania / :
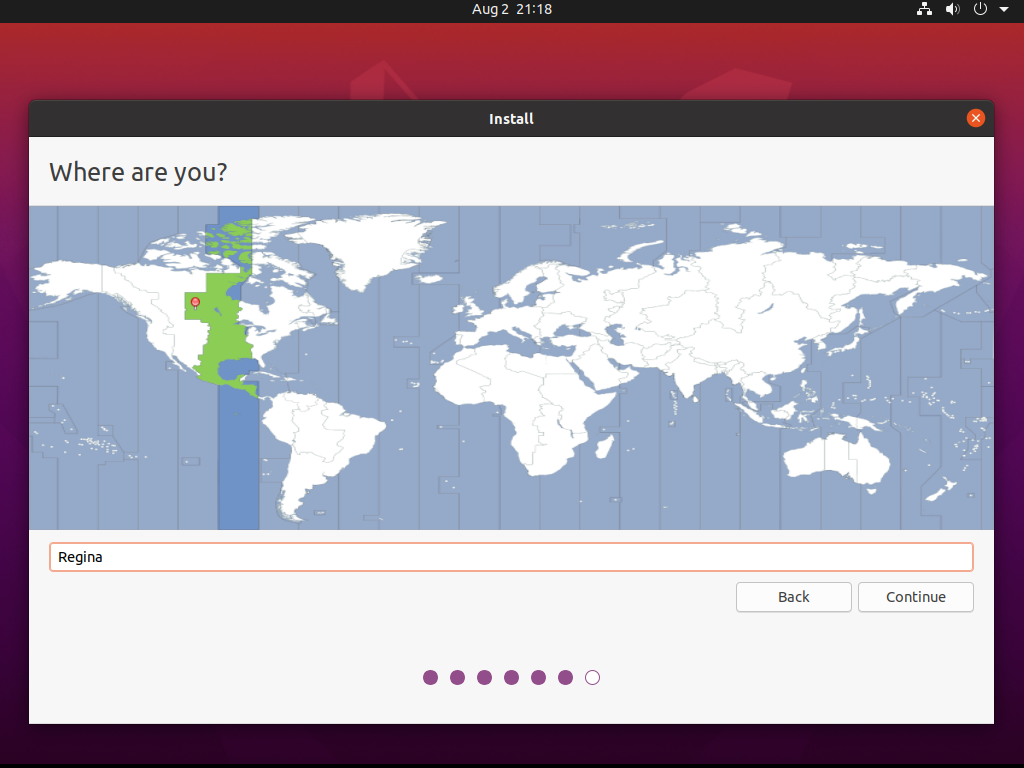
Jeśli chcemy poprawić trochę prywatność operacji, które zamierzamy przeprowadzać w maszynie wirtualnej, to możemy też wybrać inną strefę czasową:
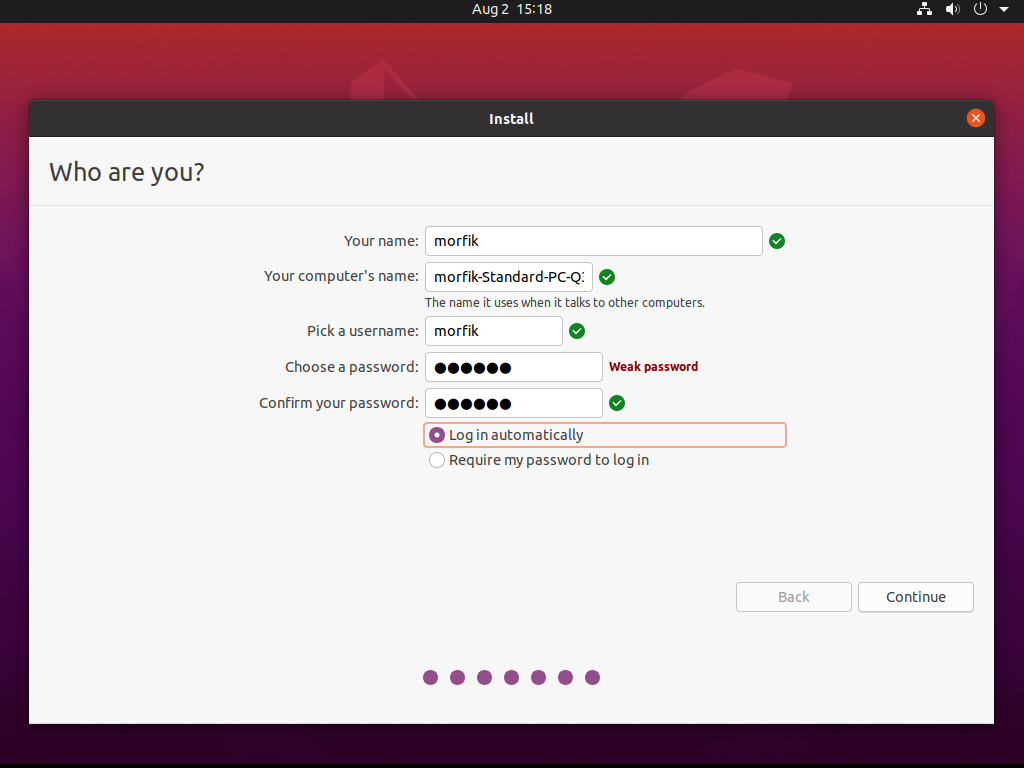
Ustawiamy dane logowania do systemu oraz włączamy automatyczne logowanie:
No i czekamy, aż system się zainstaluje:
Gdy ten proces dobiegnie końca, restartujemy maszynę wirtualną i odpalamy ją z wirtualnego dysku:
Po chwili powinien nam się załadować zainstalowany system:
Konfiguracja maszyn wirtualnych QEMU/KVM
Sporą część konfiguracji maszyny wirtualnej przeprowadziliśmy już na wstępnym etapie stawiania systemu operacyjnego. Niemniej jednak, jest kilka kwestii, które możemy jeszcze dodatkowo ustawić.
Maszyny wirtualne można konfigurować przy pomocy GUI (via virt-manager ) ale można też ręcznie
edytować plik konfiguracyjny XML za sprawą polecenia virsh. Ta druga opcja daje nam nieco większe
możliwości, bo nie wszystkie opcje da radę ustawić via virt-manager .
Zmienne LIBVIRT_DEBUG oraz LIBVIRT_LOG_OUTPUTS
Jeśli kiedykolwiek napotkamy błędy przy wydawaniu poleceń virsh , to zawsze możemy przełączyć
libvirt w tryb debugowania przy pomocy zmiennej LIBVIRT_DEBUG . Jako, że log uzyskany w ten
sposób może być dość spory, to dobrze jest także automatycznie zapisać go w pliku i do tego celu
można skorzystać ze zmiennej LIBVIRT_LOG_OUTPUTS :
$ export LIBVIRT_DEBUG=1
$ export LIBVIRT_LOG_OUTPUTS="1:file:virsh.log"
Zmienna LIBVIRT_DEFAULT_URI
Jeśli nie chce nam się ciągle używać konta administratora systemu root do zarządzania maszynami
wirtualnymi (w tym edycji plików XML), to możemy sobie wyeksportować zmienną LIBVIRT_DEFAULT_URI ,
przykładowo:
$ export LIBVIRT_DEFAULT_URI='qemu:///system'
W taki sposób nie będziemy musieli korzystać z konta root lub też ciągle podawać parametru
--connect qemu:///system w poleceniu virsh wydawanych jako zwykły użytkownik. Uprości nam to
znacznie korzystanie z narzędzia virsh , przykładowo:
$ virsh list --all
Id Name State
------------------------------------
- ubuntu20.04 shut off
zamiast:
$ virsh --connect qemu:///system list --all
Id Name State
------------------------------------
- ubuntu20.04 shut off
Jak edytować XML maszyn wirtualnych
Konfiguracja maszyn wirtualnych jest przechowywana w katalogu /etc/libvirt/qemu/ . Jeśli jednak,
podejrzymy przykładowy plik, to zobaczymy w nim poniższą informację:
# head /etc/libvirt/qemu/ubuntu20.04.xml
<!--
WARNING: THIS IS AN AUTO-GENERATED FILE. CHANGES TO IT ARE LIKELY TO BE
OVERWRITTEN AND LOST. Changes to this xml configuration should be made using:
virsh edit ubuntu20.04
or other application using the libvirt API.
-->
Nie powinniśmy zatem ręcznie edytować tych plików, tylko korzystać z virsh edit , podając w
argumencie nazwę/domenę maszyny wirtualnej, w tym przypadku ubuntu20.04 :
# virsh edit ubuntu20.04
Jeśli nie wiemy jak się nazywa nasza maszyna wirtualna to zawsze możemy skorzystać z
automatycznego uzupełniania polecenia via klawisz TAB .
Kolejność nośników rozruchu systemu
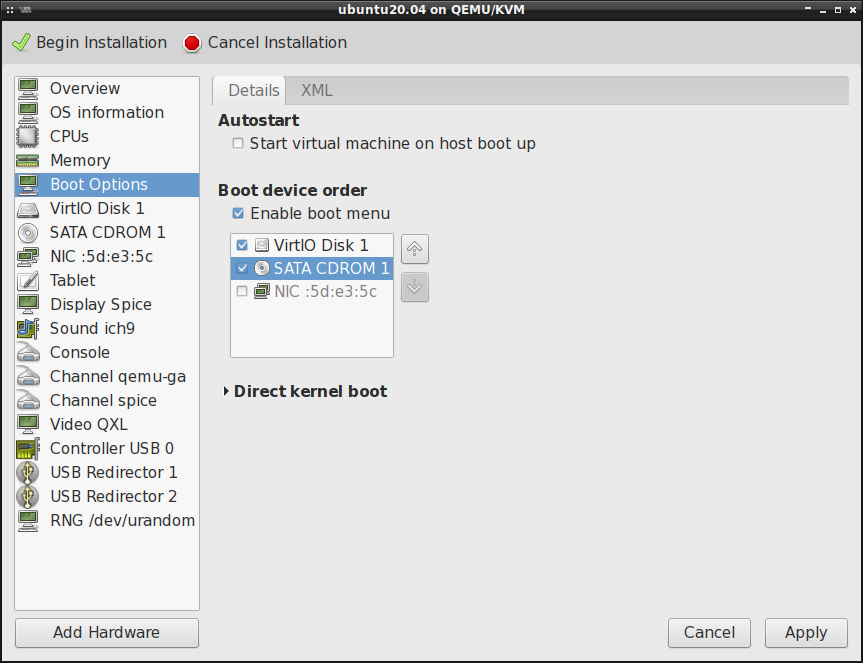
W przypadku problemów z uruchomieniem systemu z medium instalacyjnego, trzeba skonfigurować sobie kolejność nośników rozruchu włączając przy tym wirtualny cd-rom. Ten krok zwykle nie jest potrzebny przy pierwszym uruchomieniu maszyny wirtualnej (podczas procesu instalacji systemu operacyjnego).
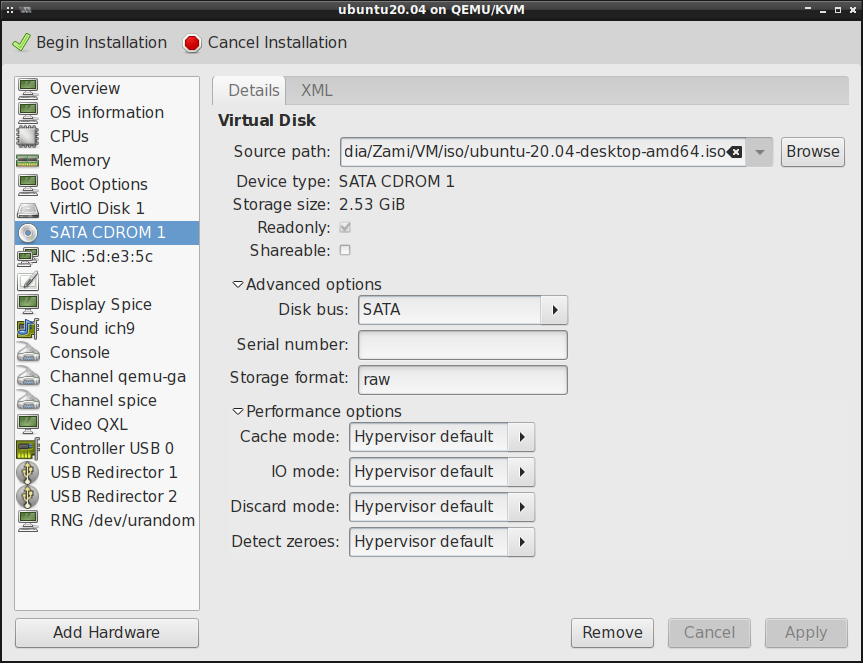
Protokół SPICE/VNC
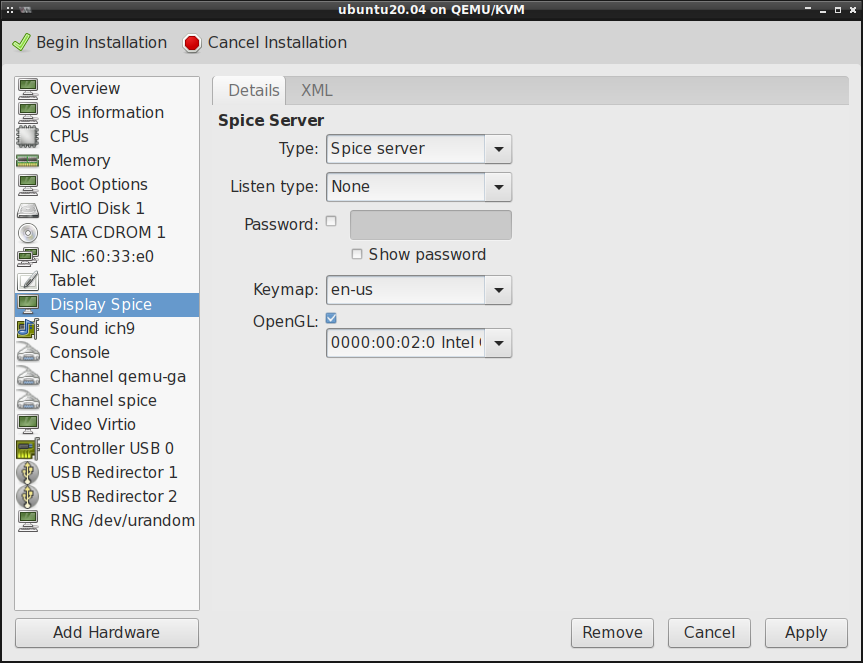
Jeśli chcemy mieć pogląd graficzny tego co się dzieje w maszynie wirtualnej to musimy skonfigurować sobie urządzenie monitora. Domyślnie jest skonfigurowany monitor na bazie protokołu SPICE (Simple Protocol for Independent Computing Environments). Jest też dostępny protokół VNC (Virtual Network Computing), choć w moim przypadku występują z nim jakieś dziwne problemy, tj. brak precyzyjnego ustawienia myszy. Dlatego też będę korzystał z serwera SPICE. Dla poprawy wydajności, dobrze jest włączyć wsparcie dla OpenGL:
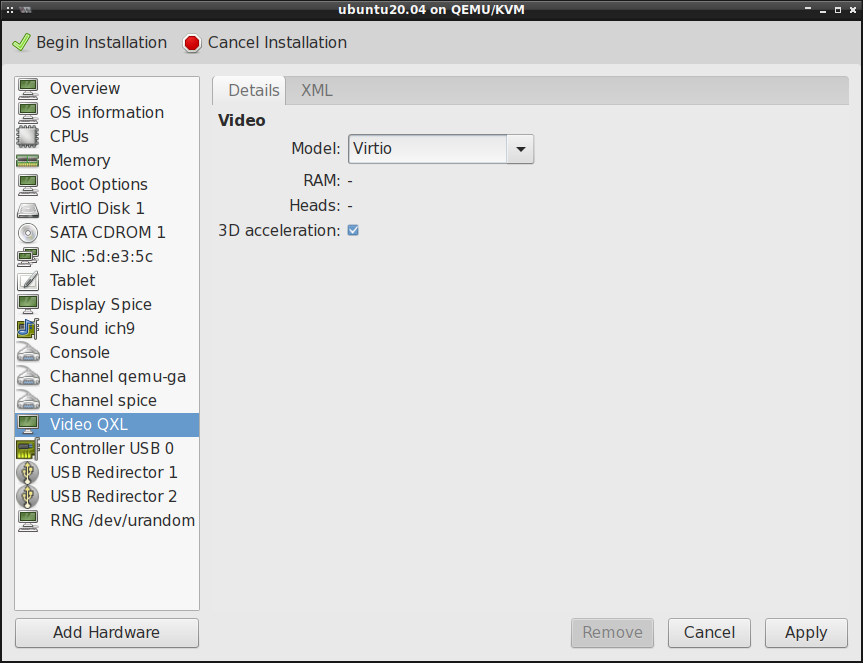
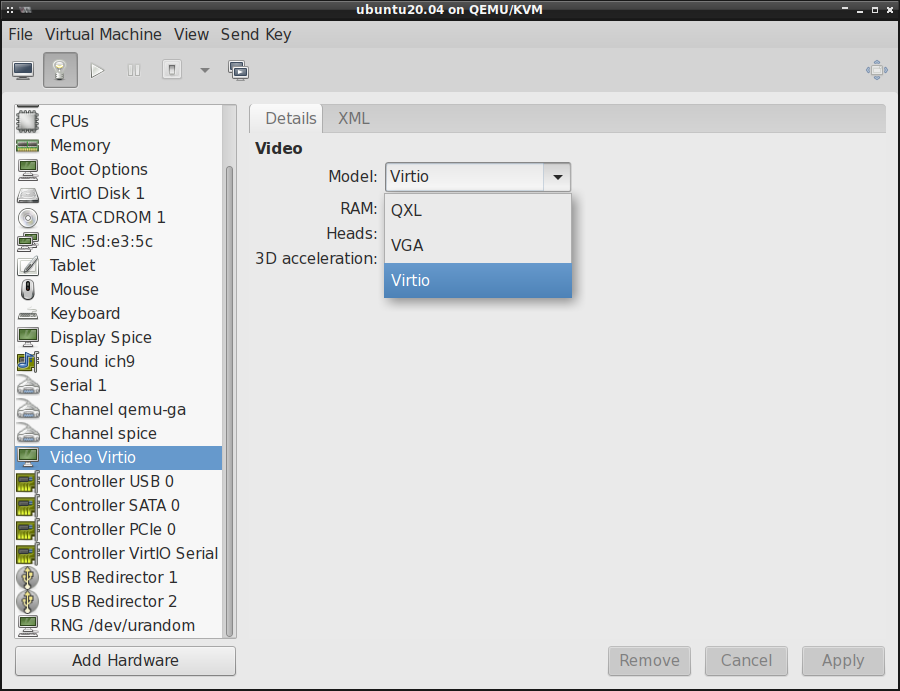
oraz zmienić model video z QXL na Virtio , a także włączyć akcelerację 3D :
Zdalny dostęp do maszyny wirtualnej (remote-viewer)
Do maszyn wirtualnych można także uzyskać dostęp spoza maszyny hosta. Do tego celu potrzebne jest
jednak dodatkowe oprogramowanie, które można znaleźć w pakiecie virt-viewer . Mamy tutaj m.in.
narzędzie remote-viewer . Przy jego pomocy możemy łączyć się ze zdalnymi maszynami wirtualnymi
przy pomocy różnych protokołów.
By się podłączyć przy pomocy remote-viewer do maszyny wirtualnej, trzeba podać protokół ( vnc
lub spice ), adres IP oraz port. Domyślnie do maszyn wirtualnych uruchamianych przez
virt-manager można dostać się jedynie z adresu pętli zwrotnej ( 127.0.0.1:5900 ). Zatem by się
testowo podłączyć do maszyny wirtualnej, wpisujemy w terminal jedno z tych poniższych poleceń:
$ remote-viewer spice://127.0.0.1:5900
$ remote-viewer vnc://127.0.0.1:5900
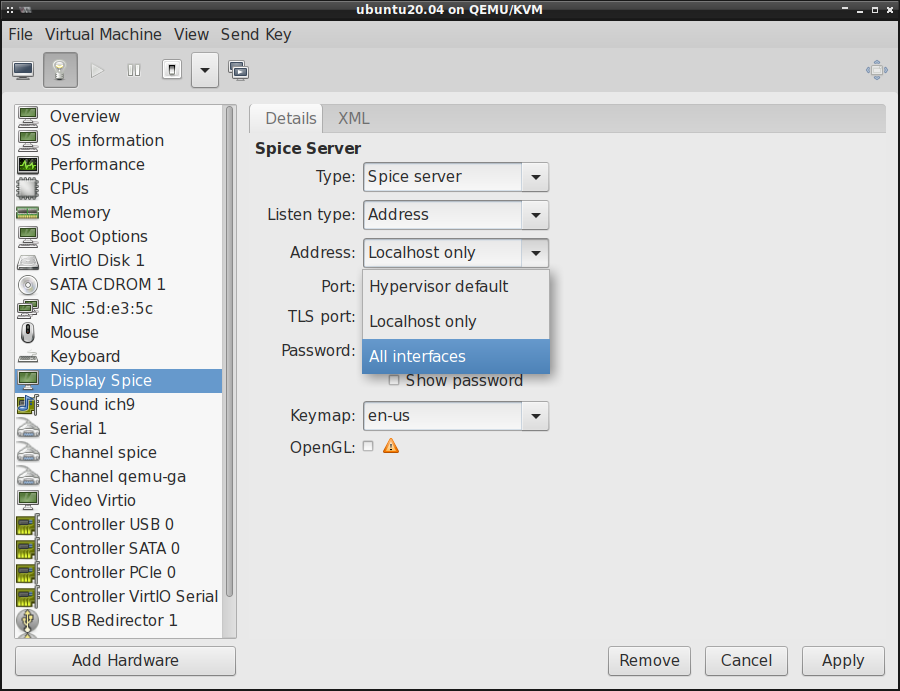
Jeśli chcielibyśmy zezwolić na dostęp do maszyny wirtualnej spoza naszego komputera, np. z sieci
lokalnej, to trzeba zmienić w konfiguracji maszyny wirtualnej Address z Localhost only na All Interfaces :
Trzeba się jednak liczyć z faktem, że zdalne połączenia mogą zostać podsłuchane. Dlatego też dobrze jest sobie wdrożyć szyfrowany SPICE.
Warto w tym miejscu dodać, że remote-viewer może zostać wykorzystany do poglądu lokalnego przy
wykorzystaniu soketów unix. Trzeba tylko w konfiguracji maszyny wirtualnej (w pliku XML, bo
virt-manager na to nie pozwala póki co) przerobić zwrotkę graphics , tak by wygląda mniej więcej
jak ta poniższa:
<graphics type='spice' keymap='en-us'>
<listen type='socket'/>
<gl enable='yes' rendernode='/dev/dri/by-path/pci-0000:00:02.0-render'/>
</graphics>
Sprawdźmy jeszcze jak wygląda konfiguracja po uruchomieniu maszyny wirtualnej:
# virsh dumpxml --domain ubuntu20.04
...
<graphics type='spice' keymap='en-us'>
<listen type='socket' socket='/var/lib/libvirt/qemu/domain-10-ubuntu20.04/spice.sock'/>
<gl enable='yes' rendernode='/dev/dri/by-path/pci-0000:00:02.0-render'/>
</graphics>
Jako, że wcześniej nie określiliśmy parametru socket= , to został on określony domyślnie.
By się teraz podłączyć do maszyny wirtualnej przy pomocy remote-viewer , korzystamy z poniższego
polecenia:
$ remote-viewer spice+unix:///var/lib/libvirt/qemu/domain-10-ubuntu20.04/spice.sock
Klient SPICE/VNC (virt-viewer)
Narzędzie virt-manager ma wbudowany w siebie klient SPICE/VNC i w zasadzie możemy z niego
korzystać by operować na maszynach wirtualnych w trybie graficznym. Jeśli jednak chcielibyśmy
skorzystać z dedykowanego klienta, to w pakiecie virt-viewer jest dostępne narzędzie
virt-viewer , które to jest prostym klientem SPICE/VNC umożliwiającym podejrzenie maszyny
wirtualnej w trybie graficznym. Ten klient nie zezwala w zasadzie na nic innego jak tylko
wyświetlenie zawartości graficznej konsoli i konfiguracji paru opcji, które z tym wyświetlaniem
obrazu są związane. Nie da rady przy pomocy virt-viewer zarządzać maszynami wirtualnymi czy też
zmieniać ich konfiguracji. W zasadzie jest to taka lokalna wersja remote-viewer .
Agent SPICE
Agent SPICE jest dedykowaną usługą działająca w systemie maszyny wirtualnej. Czasami jednak
stosowny pakiet nie zostanie zainstalowany podczas wgrywania systemu operacyjnego gościa. Dlatego
też jeśli brakuje nam pakietu spice-vdagent , to trzeba go będzie ręcznie doinstalować wewnątrz
maszyny wirtualnej:
# apt-get install spice-vdagent
Ten pakiet zawiera usługę spice-vdagentd.service dla systemd, która po instalacji powinna
automatycznie wystartować. Niemniej jednak, restart maszyny wirtualnej w moim przypadku był
wymagany, by ta usługa zaczęła działać poprawnie.
Dodatkowo, Agent SPICE wymaga szeregowego urządzenia PCI ze sterownikiem VirtIO, oraz dedykowanego
urządzenia znakowego spicevmc . Obie te rzeczy trzeba dodać w konfiguracji maszyny wirtualnej, bo
w przeciwnym przypadku Agent SPICE nie będzie nam działał. Odpalamy zatem virt-manager i dodajemy
w nim te dwa poniższe urządzenia (oczywiście jeśli ich jeszcze na liście urządzeń nie mamy).
Controler VirtIO Serial:
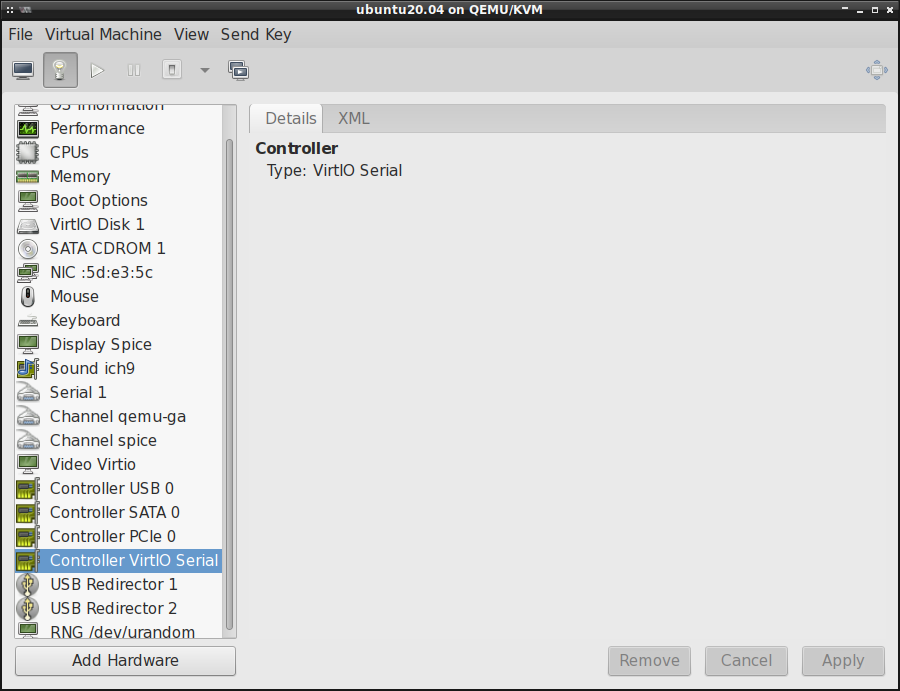
Channel SPICE Agent:
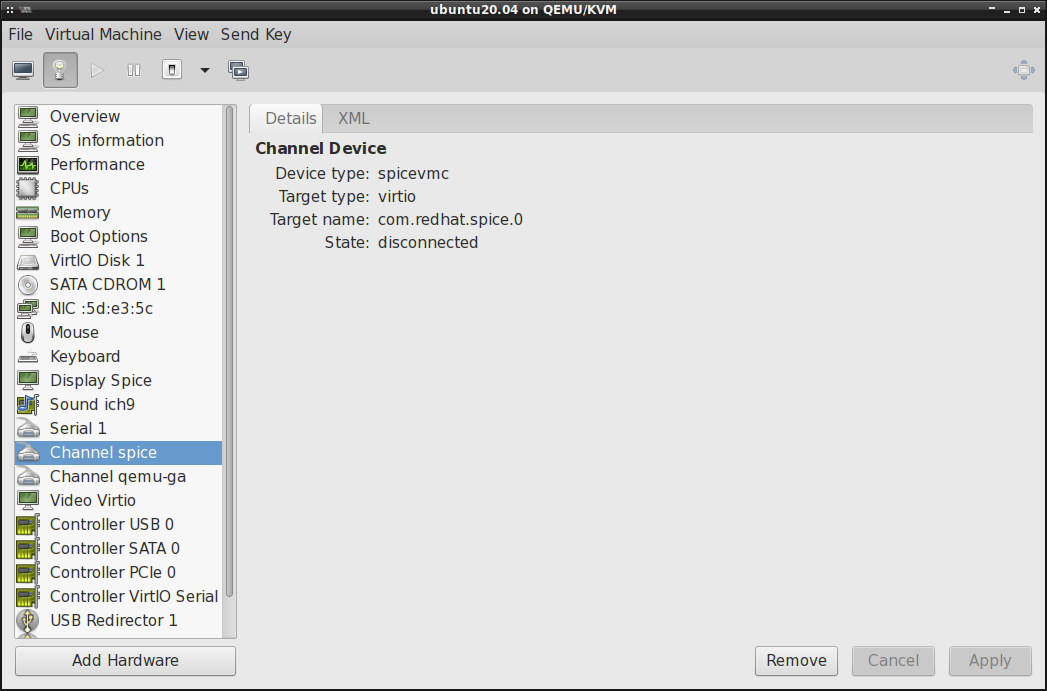
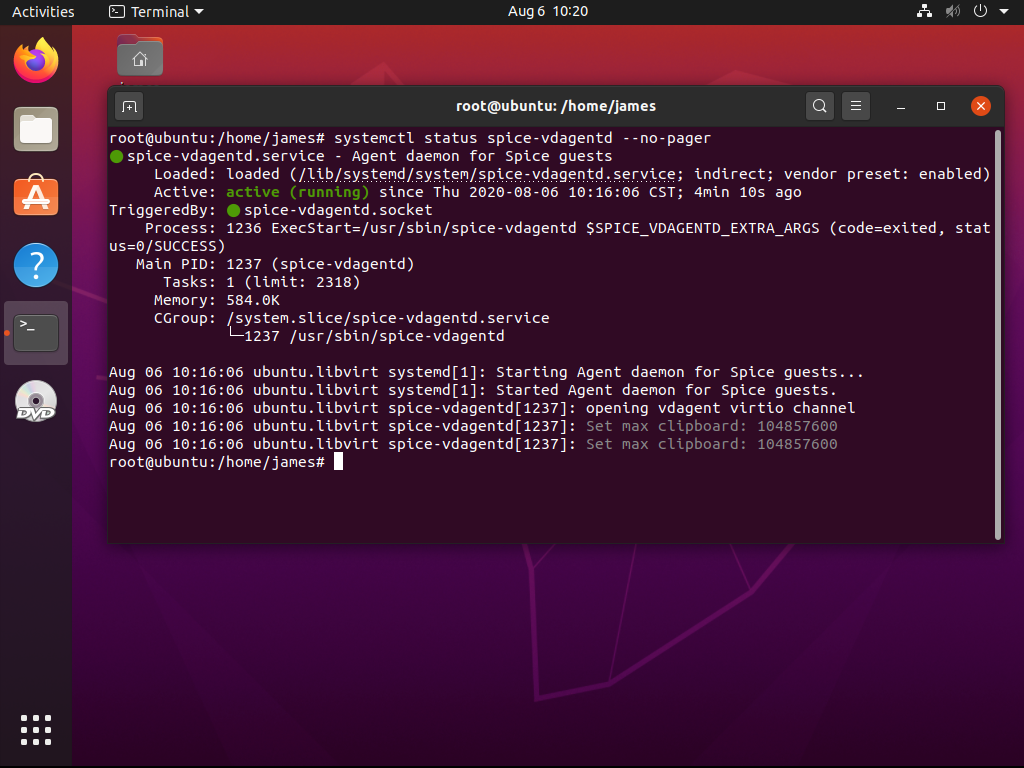
Co ciekawe, nawet po poprawnym skonfigurowaniu tego Agenta SPICE, State widoczny wyżej zawsze
wskazuje na disconnected . Niemniej jednak, sam Agent SPICE działa bez problemu:
Dzielenie schowka hosta z maszyną wirtualną
Po zainstalowaniu systemu operacyjnego gościa (dla odmiany to był Debian), chciałem skopiować parę poleceń do terminala (tego w systemie maszyny wirtualnej), tak by nie musieć ręcznie wpisywać komend do wykonania. Okazało się, że zarówno maszyna wirtualna jak i maszyna hosta mają osobne schowki, przez co nie da rady skopiować zawartości schowka maszyny hosta i przesłać jej do maszyny wirtualnej (podobnie też w drugą stronę). Zainstalowanie i poprawne skonfigurowanie Agenta SPICE rozwiązało ten problem.
Przesyłanie plików za sprawą przeciągnij i upuść (drag and drop)
Po włączeniu Agenta SPICE, będziemy także w stanie przesłać pliki z maszyny hosta do maszyny
wirtualnej za pomocą przeciągnięcia pliku i puszczenia go w oknie maszyny wirtualnej. Wszystkie
pliki upuszczone w oknie maszyny wirtualnej zostaną automatycznie umieszczone w katalogu
~/Downloads/ . Ten mechanizm "przeciągnij i upuść" nie działa jednak w drugą stronę, tj. nie da
rady wyciągnąć pliku z okna maszyny wirtualnej i umieścić go na maszynie hosta, przynajmniej mi się
nie udało tego zrobić.
Poprawa wydajności myszy
Co ciekawe, zanim się zainstalowało pakiet spice-vdagent , to by móc opuścić okno maszyny
wirtualnej (wyjść myszą poza obszar jej monitora), trzeba było wcisnąć lewy CTRL+ALT. Do tego sama
mysz w obrębie okna maszyny wirtualnej miała dość spore opóźnienia podczas przemieszczania jej i
nie dało się nią komfortowo operować. Jak tylko się doinstalowało pakiet spice-vdagent i ponownie
uruchomiło maszynę wirtualną, to wszystkie te problemy zniknęły w zasadzie od razu.
Rozdzielczość ekranu maszyny wirtualnej
Ubuntu uruchomiony wewnątrz maszyny wirtualnej ma rozdzielczość ekranu 1024x768 . Jakby nie
patrzeć jest to trochę mała rozdziałka ale bez problemu możemy ją zwiększyć zmieniając odpowiednio
ustawienia systemowe, dokładnie w taki sam sposób jakbyśmy to robili w systemie hosta:
Warto tutaj dodać, że jeśli chcielibyśmy ustawić niestandardową rozdzielczość, to zawsze możemy zmienić rozmiar okna i wpisać w terminalu na maszynie wirtualnej to poniższe polecenie:
$ xrandr --output Virtual-1 --auto
Dynamiczna zmiana rozdzielczości ekranu
Przeglądarki maszyn wirtualnych są w stanie wyświetlać graficzną konsolę systemów gościa w określonej rozdzielczości. Po zainstalowaniu Agenta SPICE, powinniśmy mieć także możliwość dynamicznej zmiany rozdzielczości ekranu maszyny wirtualnej w zależności od aktualnych wymiarów jej okna. Bez dynamicznej zmiany rozdzielczości, gdy monitor maszyny hosta jest za mały, to w oknie maszyny wirtualnej pojawią się paski przewijania. Jedyną opcją, by się tych pasków pozbyć jest zmiana rozdzielczości w ustawieniach systemu gościa lub zmiana wymiarów samego okna. Mając Agenta SPICE, te ustawienia rozdzielczości ekranu maszyny wirtualnej są dynamicznie aplikowane w zależności od wymiarów jej okna. W ten sposób system jest w stanie dostosować rozdzielczość za nas, a my nie musimy przy tym nic zmieniać czy to na maszynie hosta, czy też w systemie gościa.
Przypisanie maszyn wirtualnych do konkretnych CPU
Z informacji zawartych tutaj wynika iż można dość znacznie poprawić wydajność maszyn wirtualnych przypisując im konkretne rdzenie CPU maszyny hosta. W jaki sposób? Rozchodzi się tutaj o technologię HT (Hyper-Threading), za której to sprawą w systemie mamy do dyspozycji dwa razy więcej rdzeni niż faktycznie jest ich dostępnych w procesorze. Dla przykładu, mój laptop ma 2 fizyczne rdzenie + 2 rdzenie HT, razem w systemie można zobaczyć 4 CPU. Problem z rdzeniami HT w procesorach jest taki, że one nigdy nie mają takiej samej wydajności w stosunku do normalnego rdzenia procesora (zwykle <30%). Możemy zatem poprawić wydajność maszyny wirtualnej przypisując jej procesy do fizycznych rdzeni procesora, zamiast do rdzeni HT.
Jeśli mamy problem z oceną, które rdzenie są fizyczne, a które HT, to możemy wspomóc się
narzędziami lscpu oraz cpuid :
# lscpu --all --extended
CPU NODE SOCKET CORE L1d:L1i:L2:L3 ONLINE MAXMHZ MINMHZ
0 0 0 0 0:0:0:0 yes 3300.0000 1200.0000
1 0 0 0 0:0:0:0 yes 3300.0000 1200.0000
2 0 0 1 1:1:1:0 yes 3300.0000 1200.0000
3 0 0 1 1:1:1:0 yes 3300.0000 1200.0000
Zatem mamy dwa fizyczne rdzenie oznaczone numerkami 0 i 1 (w kolumnie CORE ). CPU0 i CPU1 siedzą
na pierwszym rdzeniu, zaś CPU2 i CPU3 na drugim. I jak można się spodziewać, CPU0 i CPU1 dzielą
cache L1 i L2 między sobą, podobnie jak CPU2 i CPU3 mają wspólny cache. Zaś cache L3 jest wspólny
dla wszystkich CPU.
Z kolei z cpuid możemy wyciągnąć poniższe informacje:
# cpuid | egrep "^CPU|PKG_ID"
CPU 0:
(APIC synth): PKG_ID=0 CORE_ID=0 SMT_ID=0
CPU 1:
(APIC synth): PKG_ID=0 CORE_ID=0 SMT_ID=1
CPU 2:
(APIC synth): PKG_ID=0 CORE_ID=1 SMT_ID=0
CPU 3:
(APIC synth): PKG_ID=0 CORE_ID=1 SMT_ID=1
Zatem w tym CPU normalne rdzenie mają numerki 0 i 2, a rdzenie HT mają 1 i 3. Możemy ten fakt
zweryfikować podglądając pliki w katalogu /sys/ :
# cat /sys/devices/system/cpu/cpu0/topology/thread_siblings_list
0-1
# cat /sys/devices/system/cpu/cpu1/topology/thread_siblings_list
0-1
# cat /sys/devices/system/cpu/cpu2/topology/thread_siblings_list
2-3
# cat /sys/devices/system/cpu/cpu3/topology/thread_siblings_list
2-3
W przypadku dwóch pierwszych poleceń, mimo iż ścieżka cpu* jest inna, to mamy wynik 0-1 ,
podobnie w przypadku dwóch ostatnich poleceń, gdzie zostało zwrócone 2-3 . Pierwsza liczba zawsze
wskazuje na rdzeń fizyczny, a druga rdzeń HT.
Jeśli maszynie wirtualnej dalibyśmy przydział 2 dowolnych rdzeni procesora z 4 dostępnych, to procesy maszyny wirtualnej będą alokowane na wolnych CPU, w tym na rdzeniach HT. Jeśli zaś im przypiszemy konkretne fizyczne rdzenie, to te procesy nie będą mogły migrować sobie pomiędzy rdzeniami fizycznymi a rdzeniami HT, nawet jeśli te rdzenie HT będą w stanie IDLE (nieużywane). Jeśli się zdecydujemy na wybór fizycznych rdzeni, to niestety kosztem trafień w cache, choć wydajność i tak powinna dość znacznie wzrosnąć.
By ustawić przydział CPU na sztywno, edytujemy konfigurację maszyny wirtualnej (via virsh edit ubuntu20.04 ) i dodajemy do niej poniższy kod zaraz pod <vcpu></vcpu> :
<cputune>
<vcpupin vcpu='0' cpuset='0'/>
<vcpupin vcpu='1' cpuset='2'/>
</cputune>
Tej maszynie wirtualnej zostały oddelegowane dwa rdzenie, stąd vcpu o numerkach 0 i 1 (nadajemy
tutaj kolejne numerki, w zależności od tego ile tych rdzeni chcemy dać do dyspozycji maszynie
wirtualnej). Jeśli zaś chodzi o parametr cpuset , to określamy tutaj przydział rdzeni fizycznego
CPU hosta. Do dyspozycji są numerki 0, 1, 2 i 3. Dlatego też pierwszemu wirtualnemu rdzeniowi
maszyny wirtualnej został przypisany pierwszy (0) fizyczny rdzeń, a drugiemu wirtualnemu rdzeniowi
trzeci (2) fizyczny rdzeń CPU. W ten sposób maszyna wirtualna będzie operować jedynie na fizycznych
rdzeniach, a nie na rdzeniach HT, co powinniśmy natychmiast odczuć, choćby podczas rozruchu systemu
gościa.
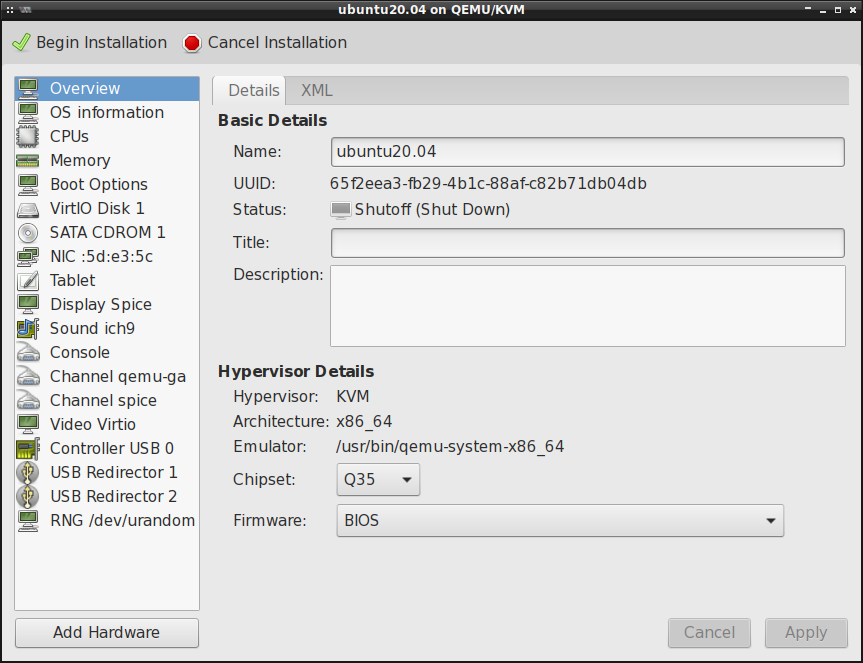
BIOS vs. EFI/UEFI
Standardowa instalacja systemu w maszynach wirtualnych zakłada wykorzystanie czipsetu Q35 z konfiguracją BIOS:
Istnieje jednak możliwość skonfigurowania maszyny wirtualnej w taki sposób, by robiła użytek z EFI/UEFI, a nawet można w niej włączyć Secure Boot:
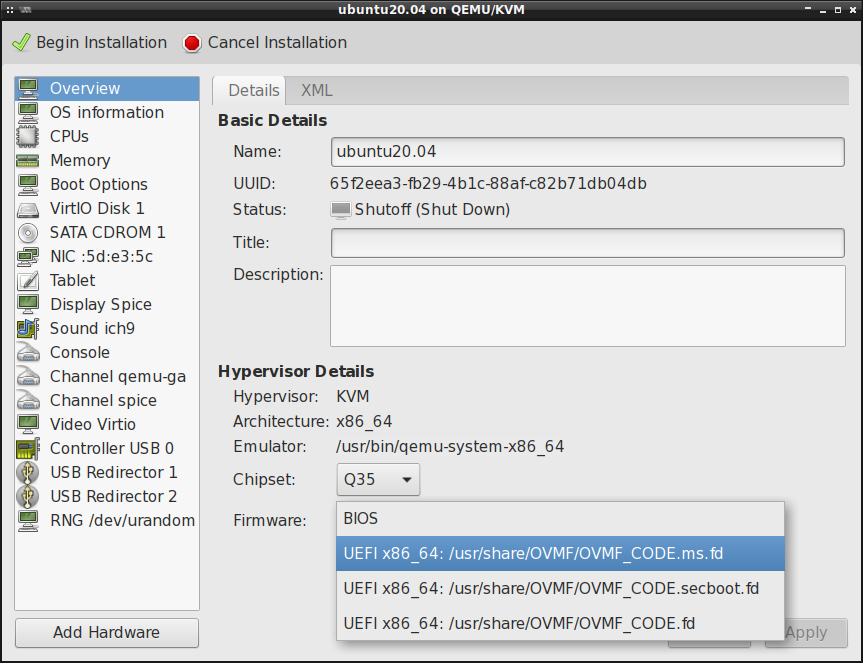
By te dodatkowe opcje od EFI/UEFI się pojawiły, to musimy zainstalować w systemie hosta
pakiet ovmf :
# aptitude install ovmf
Trzeba jednak liczyć się z faktem, że ustawienia w tej zakładce nie będą mogłoby być zmienione, gdy rozpoczniemy tworzenie maszyny wirtualnej. Dlatego też trzeba się zastanowić jaki czipset chcemy wykorzystać oraz czy potrzebny jest nam EFI/UEFI z lub bez Secure Boot.
QEMU Guest Agent (GA)
QEMU Guest Agent jestem demonem uruchomionym wewnątrz maszyny wirtualnej (podobnie jak Agent SPICE). Jego zadaniem jest pomoc aplikacjom zarządzającym (management applications) przy wykonywaniu funkcji, które potrzebują pomocy ze strony systemu operacyjnego gościa. Dla przykładu może to być wejście w stan uśpienia (suspend) lub zamrożenie/odmrożenie systemu plików (freezing and thawing filesystems). QEMU Guest Agent może także zostać użyty do włączenia/wyłączenia wirtualnych procesorów (vCPUs) podczas pracy systemu gościa. Można w ten sposób dostosować liczbę wirtualnych CPU bez potrzeby użycia do tego celu mechanizmów hot plug/unplug.
Trzeba sobie jednak zdawać sprawę z faktu, że QEMU Guest Agent nie jest do końca bezpiecznym mechanizmem. Jeśli mamy do czynienia z niezaufanymi systemami gościa, to QEMU Guest Agent może być nadużywany i to mimo wbudowanych w niego zabezpieczeń. Wykorzystanie QEMU Guest Agent w pewnych sytuacjach może zatem prowadzić do ataków DoS na maszynę hosta.
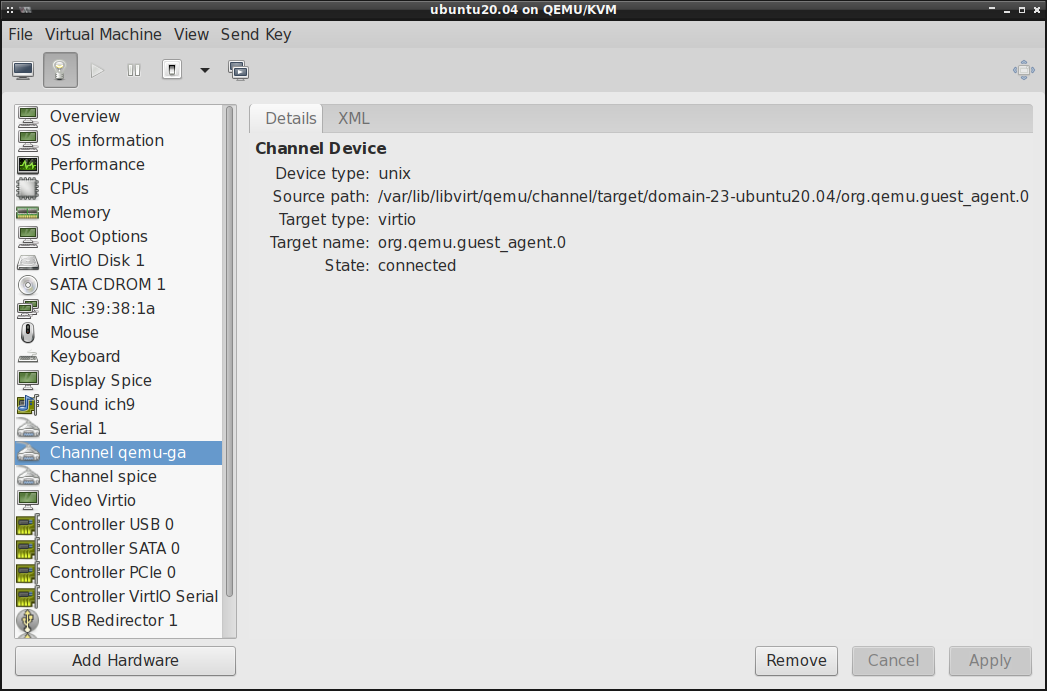
Jeśli chcielibyśmy włączyć obsługę QEMU Guest Agent w naszej maszynie wirtualnej, to trzeba dodać
Channel Device w jej konfiguracji:
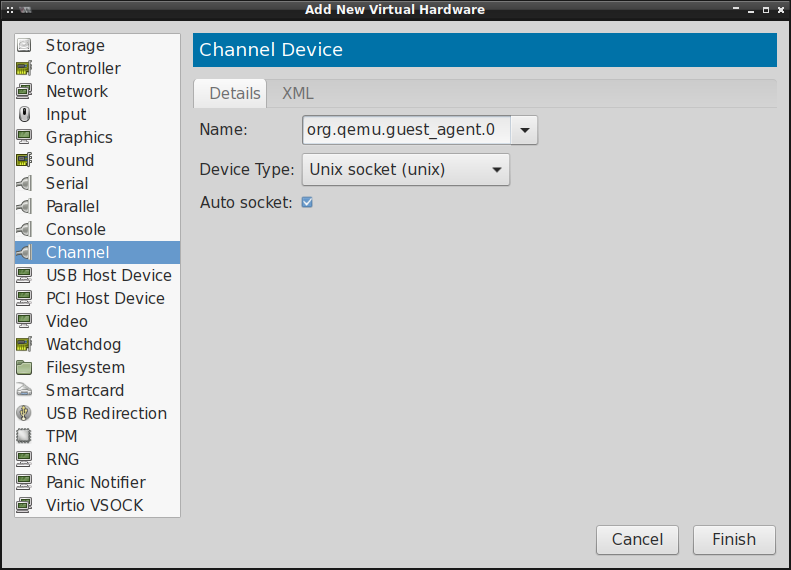
Jeśli State: w Channel qemu-ga wskazuje na disconnected , tak jak w poniższym przykładzie:
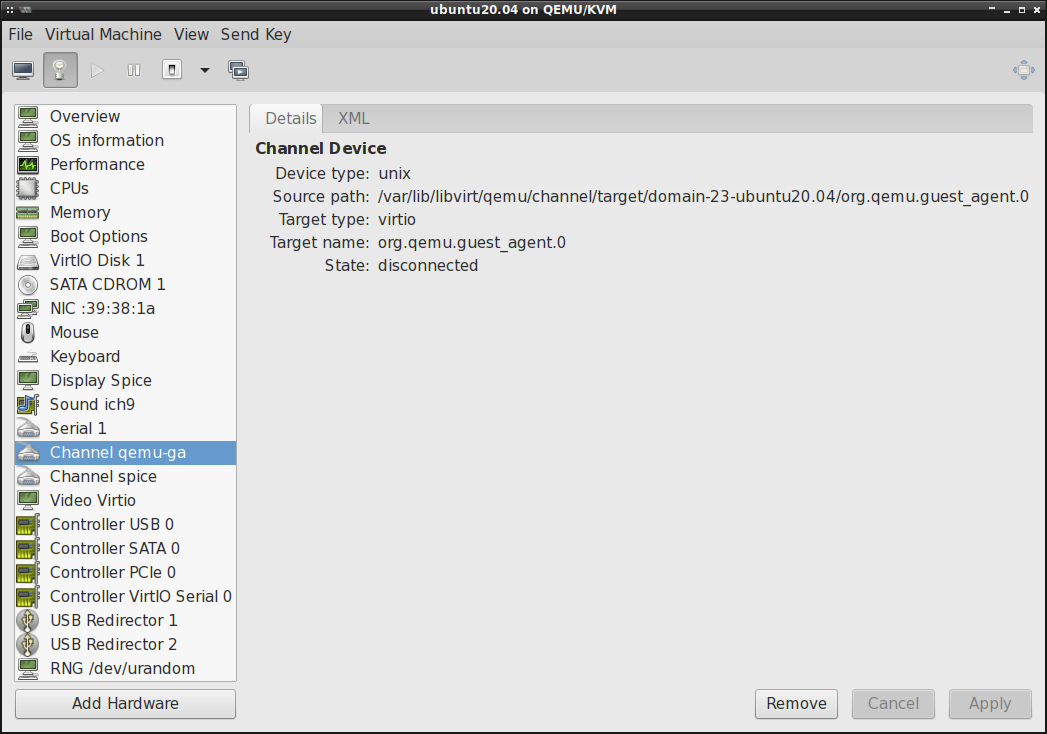
to trzeba jeszcze doinstalować systemie gościa (na maszynie wirtualnej) pakiet qemu-guest-agent
oraz uruchomić w nim usługę qemu-guest-agent.service (via systemctl start ). Jak tylko usługa
zacznie działać, to State: powinien ulec zmianie na connected :
Możemy teraz przetestować QEMU Guest Agent wydając w terminalu na maszynie hosta poniższe polecenie:
$ virsh -c qemu:///system 'reboot --mode agent --domain ubuntu20.04'
Domain ubuntu20.04 is being rebooted
Gdy usługa w systemie gościa jest nieaktywna, wtedy zostanie zwrócony poniższy błąd:
$ virsh -c qemu:///system 'reboot --mode agent --domain ubuntu20.04'
error: Failed to reboot domain ubuntu20.04
error: Guest agent is not responding: QEMU guest agent is not connected
Sterownik balloon
Przydzielenie maszynie wirtualnej jakiejś konkretnej wartości ilości RAM nie koniecznie oznacza, że
zostanie jej zarezerwowane tyle pamięci w przypadku, gdy ona w rzeczywistości wykorzystuje mniej
zasobów. Przykładowo, jeśli system maszyny wirtualnej po załadowaniu będzie utylizował 1 GiB RAM, a
maszynie przydzieliliśmy 2 GiB, to faktyczne zużycie pamięci RAM maszyny wirtualnej będzie na
poziomie 1 GiB. Jeśli teraz zaczniemy uruchamiać aplikacje w maszynie wirtualnej tak, że zużycie
pamięci operacyjnej wzrośnie z 1 GiB do 1,5 GiB, to ta maszyna wirtualna zwiększy wykorzystanie
pamięci RAM dynamicznie do tych 1,5 GiB. Nie działa to jednak w drugą stronę, tj. w przypadku
gdybyśmy pozamykali aplikacje w systemie maszyny wirtualnej, przez co zużycie pamięci RAM spadłoby
do 1 GiB, to w dalszym ciągu ta maszyna wirtualna będzie zjadać 1,5 GiB. Do tego dochodzi jeszcze
systemowy cache, który buforuje w pamięci RAM pewne dane. Jeśli teraz maszyna wirtualna ma do
dyspozycji sporo wolnej pamięci, to będzie więcej danych buforować, a to jeszcze dodatkowo zwiększy
jej apetyt na pamięć RAM w systemie hosta. Może się zdarzyć więc tak, że spora część pamięci
operacyjnej hosta będzie się marnować, bo nie będzie wykorzystywana przez maszynę wirtualną. W
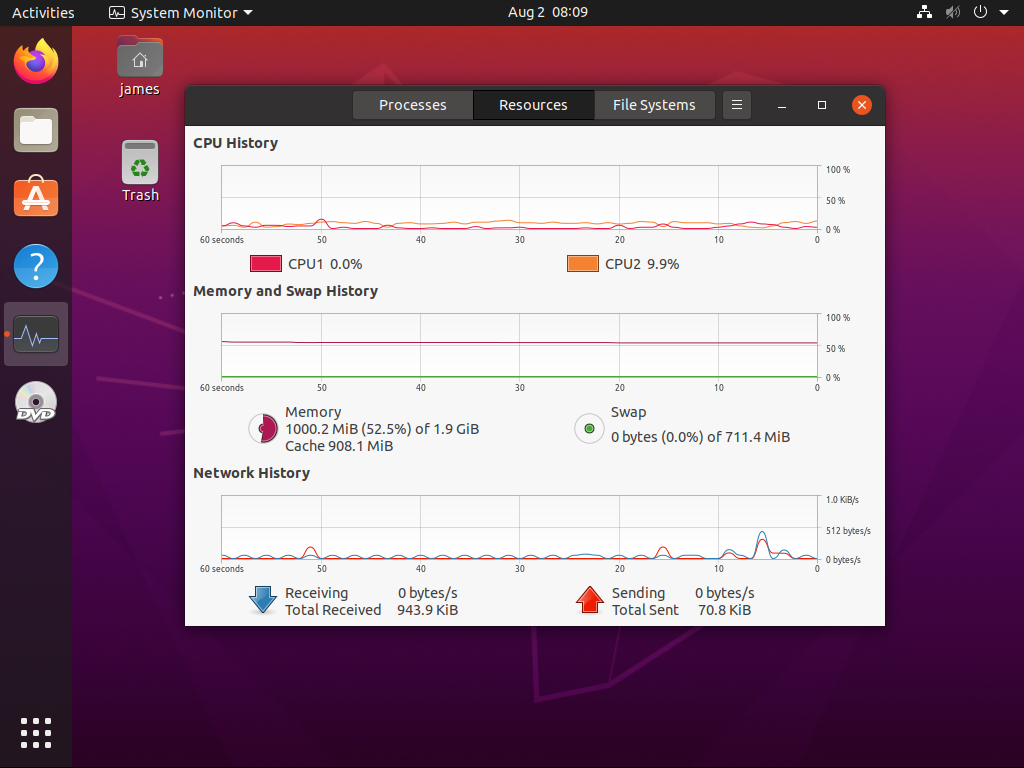
takiej sytuacji możemy odzyskać część pamięci za sprawą sterownika balloon , poniżej przykład:
Maszynie wirtualnej przydzielone zostały 2G, co widać na na poniższej fotce:
Jeśli teraz na maszynie hosta wydamy to poniższe polecenie:
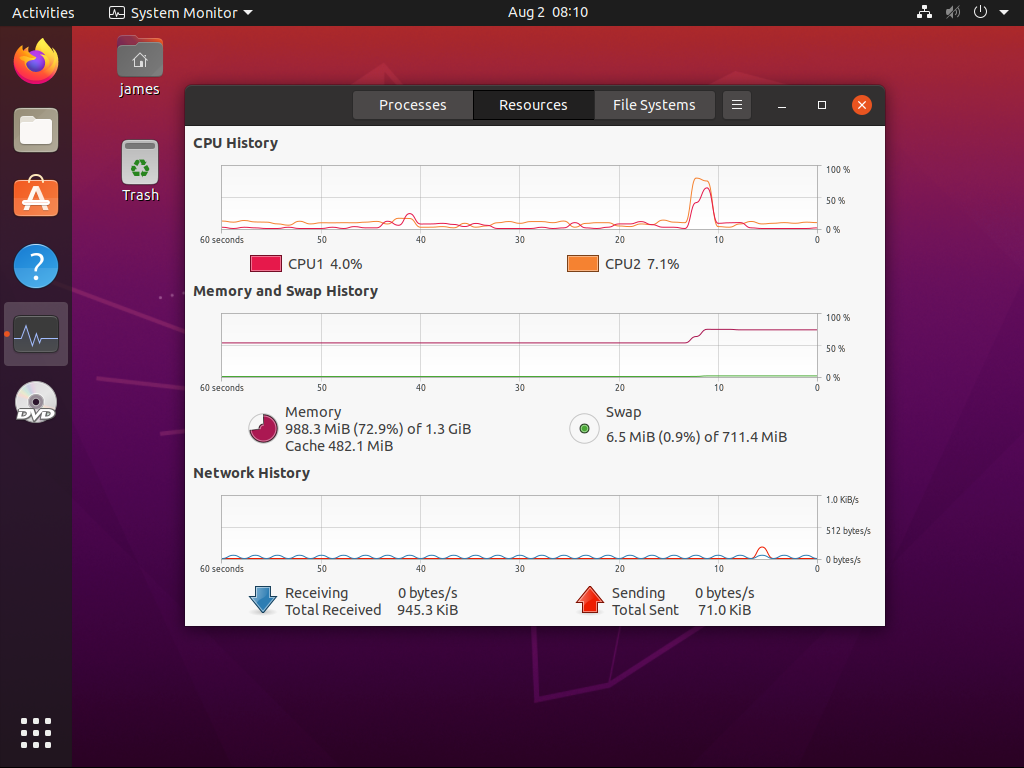
# virsh qemu-monitor-command --domain ubuntu20.04 --hmp "balloon 1500"
to ilość pamięci RAM w obrębie maszyny wirtualnej zostanie dynamicznie zmniejszona i to podczas jej normalnej pracy (nie trzeba jej wyłączać/resetować by zmiany weszły w życie):
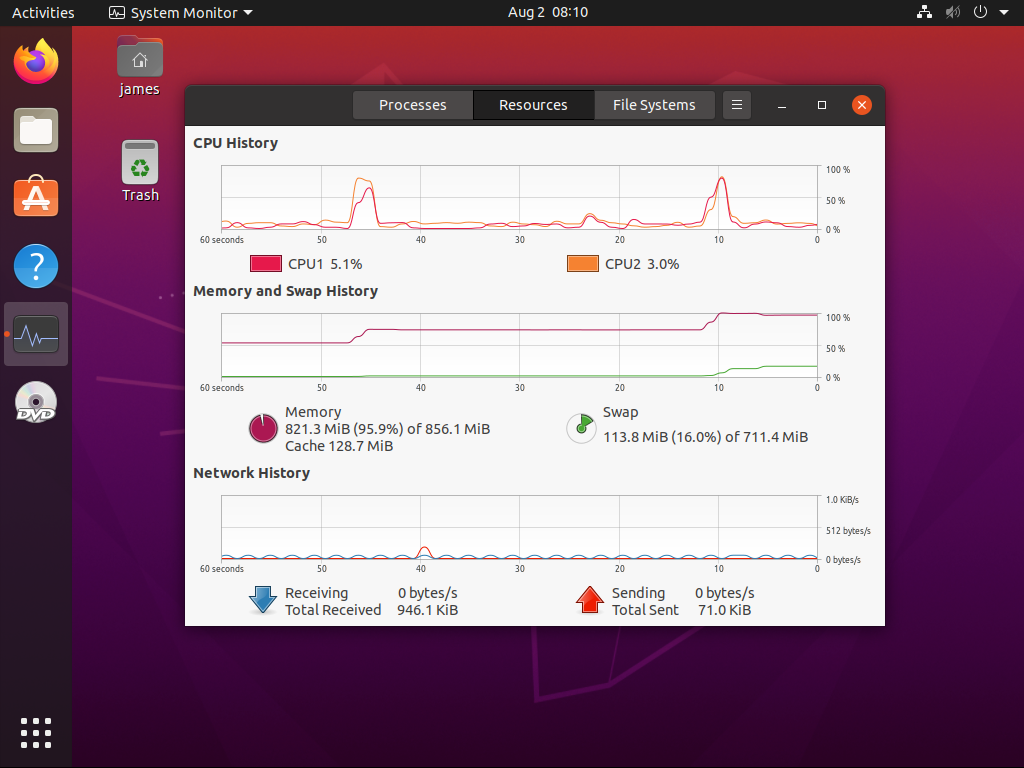
Można też zmniejszyć ilość dostępnej pamięci RAM poniżej tej, która jest aktualnie w użyciu, choć w takim przypadku system maszyny wirtualnej zacznie wykorzystywać SWAP:
Oczywiście ten mechanizm działa również w drugą stronę, tj. możemy przydzielić maszynie wirtualnej więcej pamięci niż aktualnie posiada:
# virsh qemu-monitor-command --domain ubuntu20.04 --hmp "balloon 2048"
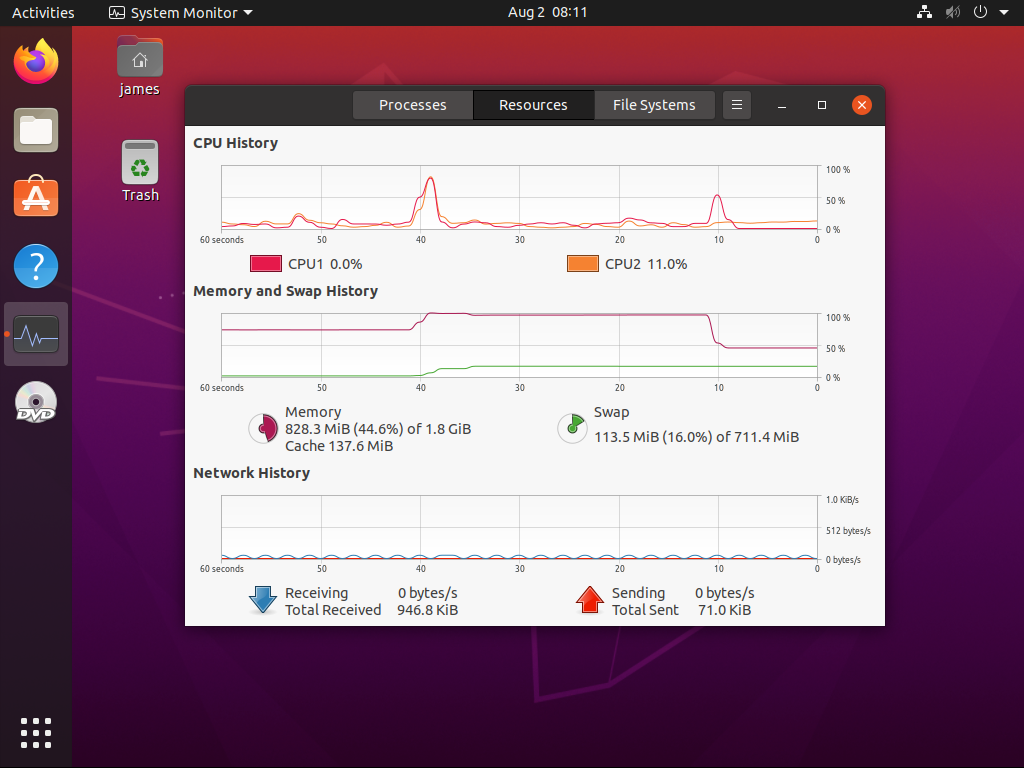
Jak widać, zmiana ilość przydzielonej pamięci operacyjnej nie jest natychmiastowa ale system maszyny wirtualnej dostosowuje się bez najmniejszego problemu. Po zmniejszeniu przydziału pamięci RAM maszynie wirtualnej, ta pamięć operacyjna jest natychmiast odzyskiwana na maszynie hosta:
# ps_mem -S | grep qemu
1.5 GiB + 3.5 MiB = 1.5 GiB 1.7 MiB qemu-system-x86_64
# virsh qemu-monitor-command --domain ubuntu20.04 --hmp "balloon 1000"
# ps_mem -S | grep qemu
1.0 GiB + 3.5 MiB = 1.1 GiB 1.7 MiB qemu-system-x86_64
Te wprowadzone zmiany są tymczasowe, tj. po restarcie maszyny wirtualnej jej ustawienia pamięci RAM zostaną przywrócone do tych, które skonfigurowaliśmy tworząc maszynę wirtualną.
Automatyczne odzyskiwanie pamięci RAM
Niestety póki co nie ma możliwości odzyskania nieużywanej przez maszyny wirtualne pamięci
operacyjnej. Jeśli taka maszyna ma wolnych 2G z przydzielonych jej 4G, to te niewykorzystane 2G nie
będą mogły zostać odzyskane przez hosta. Istnieje co prawda atrybut autodeflate, który można
określić w pliku XML z konfiguracją maszyny wirtualnej (brak możliwości ustawienia via
virt-manager ) przy sterowniku balloon , przykładowo:
<memballoon model='virtio' autodeflate='on'>
<address type='pci' domain='0x0000' bus='0x05' slot='0x00' function='0x0'/>
</memballoon>
ale ten parametr kontroluje jedynie odzyskiwanie pamięci operacyjnej przydzielonej maszynie wirtualnej w przypadku, gdy pamięć operacyjna maszyny hosta jest już na wyczerpaniu (sytuacja Out Of Memmory, OOM). Po ustawieniu tego parametru, system hosta spróbuje odzyskać trochę pamięci z maszyn wirtualnych i może powstrzyma się od ich zabijania.
Warto zauważyć tutaj, że autodeflate oraz deflate-on-oom oznaczają dokładnie to samo -- ten
pierwszy jest tylko wykorzystywany w pliku XML, ten drugi zaś w wierszu poleceń qemu .
Sterowniki VirtIO
Z racji, że hiperwizor przy pełnej wirtualizacji musi emulować fizyczny sprzęt (np. dyski czy karty
sieciowe), to ta technika wirtualizacji może się średnio sprawdzić (albo też i w ogóle) jeśli ma
dla nas znaczenie wysoka wydajność całego procesu. Dlatego też w przypadku KVM wykorzystuje się
VirtIO, który to działa na zasadzie parawirtualizacji zapewniającej szybki i wydajny sposób
komunikacji systemu gościa przy korzystaniu z urządzeń maszyny hosta. KVM prezentuje tak
zwirtualizowane urządzenia maszynom wirtualnym wykorzystując API VirtIO jako warstwę pośrednią
pomiędzy hiperwizorem na systemem gościa. By móc skorzystać ze sterowników VirtIO, muszą być
one włączone w kernelu maszyn wirtualnych (opcje CONFIG_VIRTIO_* ). Dystrybucyjne kernele mają
wszystko czego potrzeba i nie musimy nic w zasadzie dodatkowo konfigurować.
Sterowniki VirtIO poprawiają znacząco wydajność maszyn wirtualnych zmniejszając im opóźnienia operacji I/O i zwiększając za razem ich przepustowość. Zaleca się wykorzystywanie tych sterowników parawirtualizacji w przypadku maszyn wirtualnych, w obrębie których działają aplikacje intensywnie wykorzystujące I/O.
Jeśli nie wiemy czy linux, którego zainstalowaliśmy na maszynie wirtualnej, ma potrzebne moduły, to
zawsze możemy to zweryfikować przy pomocy lsmod :
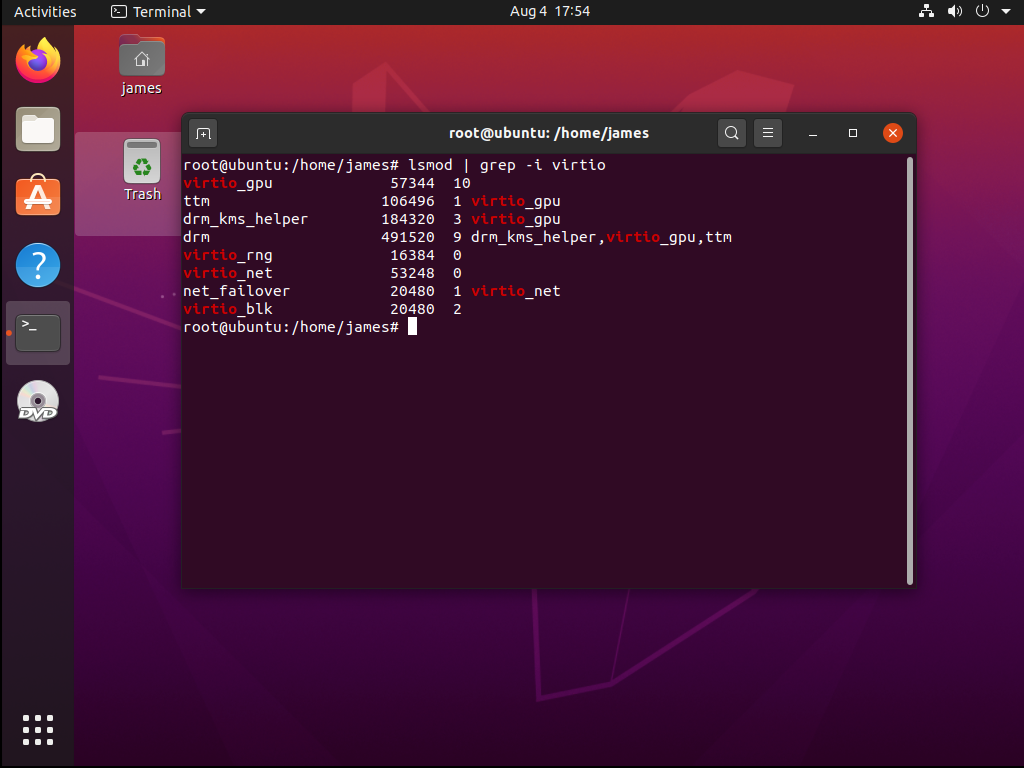
Mamy tutaj załadowane moduły virtio_blk , virtio_net , virtio_gpu oraz virtio_rng .
Niekoniecznie muszą być to wszystkie moduły virtio_* , z których maszyna robi użytek, bo część z
nich jest zwykle też wkompilowana na stałe w jądro:
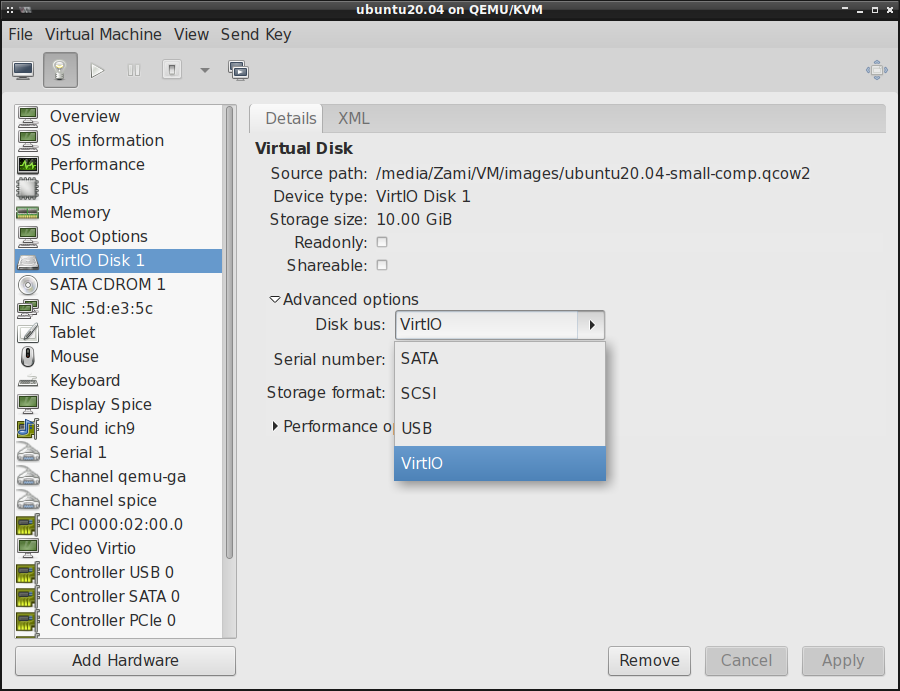
By zrobić użytek ze sterowników VirtIO, wystarczy w konfiguracji konkretnych urządzeń maszyny wirtualnej określić odpowiedni sterownik. Poniżej znajduje się kilka przykładów.
VirtIO dla dysku twardego:
VirtIO dla karty sieciowej:
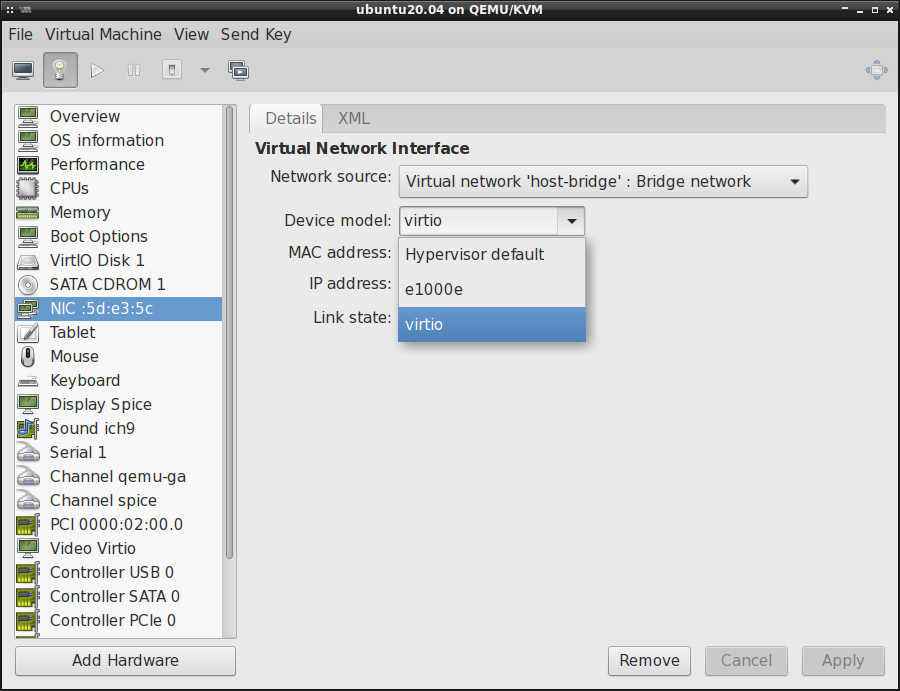
VirtIO dla karty graficznej:
QEMU/KVM i nftables
Jak już zostało wspomniane wyżej w tym artykule, maszyny wirtualne QEMU/KVM nie bardzo chcą działać
w sytuacji, gdy zamiast iptables wykorzystujemy nft do konfiguracji filtra pakietów w naszym
linux'ie. Chodzi generalnie o różnice w translacji NAT, przez co domyślna konfiguracja sieci jaka
jest dostarczana z libvirt nie zadziała nam w przypadku nftables i musimy sobie ręcznie
skonfigurować firewall pod maszyny wirtualne.
Failed to apply firewall rules /usr/sbin/iptables -w --table nat
Przede wszystkim, musimy coś zrobić z tą domyślą siecią, która ma określony NAT:
Tego typu sieci powodują dodanie łańcuchów LIBVIRT-* do filtra iptables . Dlatego też jeśli
korzystamy z nftables , to przy próbie podniesienia tej sieci dostaniemy taki komunikat błędu:
Error starting network 'default': internal error: Failed to apply firewall rules
/usr/sbin/iptables -w --table nat --list-rules: # Warning: iptables-legacy tables present, use
iptables-legacy to see them
iptables v1.8.5 (nf_tables): table `nat' is incompatible, use 'nft' tool.
Traceback (most recent call last):
File "/usr/share/virt-manager/virtManager/asyncjob.py", line 75, in cb_wrapper
callback(asyncjob, *args, **kwargs)
File "/usr/share/virt-manager/virtManager/asyncjob.py", line 111, in tmpcb
callback(*args, **kwargs)
File "/usr/share/virt-manager/virtManager/object/libvirtobject.py", line 66, in newfn
ret = fn(self, *args, **kwargs)
File "/usr/share/virt-manager/virtManager/object/network.py", line 75, in start
self._backend.create()
File "/usr/lib/python3/dist-packages/libvirt.py", line 3173, in create
if ret == -1: raise libvirtError ('virNetworkCreate() failed', net=self)
libvirt.libvirtError: internal error: Failed to apply firewall rules
/usr/sbin/iptables -w --table nat --list-rules: # Warning: iptables-legacy tables present, use
iptables-legacy to see them
iptables v1.8.5 (nf_tables): table `nat' is incompatible, use 'nft' tool.
Niekoniecznie musimy usuwać tę domyślną sieć, bo możemy jej zmienić typ z nat na open . Nie da
się jednak tego zrobić z poziomu virt-manager i trzeba edytować plik XML maszyny wirtualnej.
Poniżej przykład:
# virsh net-destroy default
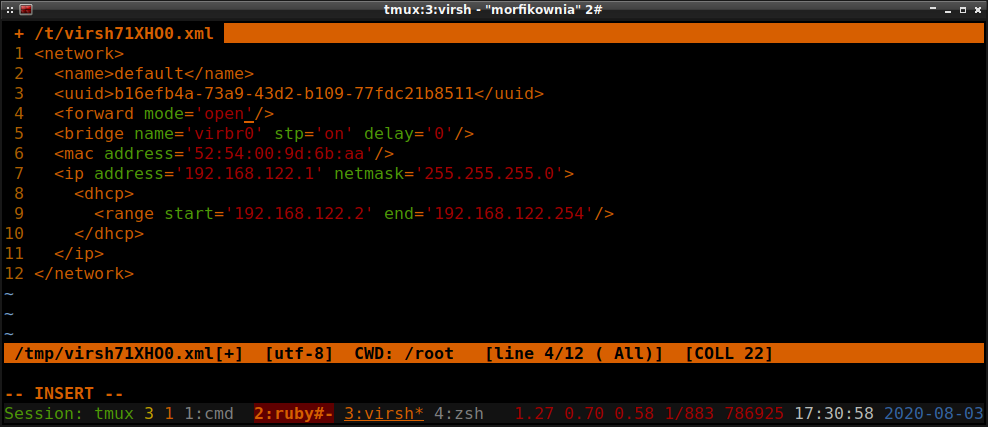
# virsh net-edit default
To pierwsze polecenie nie niszczy (jak nazwa parametru może sugerować) domyślnej sieci, tylko ją
wyłącza. Drugi polecenie edytuje tę wyłączoną sieć. Po wydaniu tego drugiego polecenia ujrzymy
konfigurację sieci default , w której to musimy zmienić <forward mode='nat'/> na
<forward mode='open'/> :
Konfiguracja nftables
Oczywiście to tylko część pracy jaką musimy wykonać. Ta powyższa zmiana zapobiegnie jedynie
dodawaniu jakichkolwiek reguł do filtra pakietów. W ten sposób możemy stworzyć własną konfigurację
firewall'a i bez znaczenia przy tym czy korzystamy z iptables czy też nftables . By dostęp do
internetu na maszynach wirtualnych był zapewniony, trzeba jeszcze dodać te poniższe reguły do
filtra.
Standardowe reguły mające na celu akceptowanie pakietów w stanie ESTABLISHED i RELATED i blokowanie pakietów w stanie INVALID:
create chain inet filter check-state
add rule inet filter check-state ct state { established, related } accept
add rule inet filter check-state ct state { invalid } counter drop
add rule inet filter INPUT jump check-state
add rule inet filter INPUT meta iif { "lo" } accept
add rule inet filter OUTPUT jump check-state
add rule inet filter OUTPUT meta oif { "lo" } counter accept
Tworzymy osobne łańcuchy dla ruchu z i do maszyn wirtualnych:
create chain inet filter input-kvm
create chain inet filter output-kvm
Przekierowujemy ruch do tych łańcuchów:
add rule inet filter INPUT meta iifname "virbr0" ip saddr 192.168.122.0/24 counter jump input-kvm comment "kvm network"
add rule inet filter OUTPUT meta oifname "virbr0" ip daddr 192.168.122.0/24 counter jump output-kvm comment "kvm network"
Tworzymy politykę w łańcuchach zezwalającą na komunikację maszyny hosta z maszynami wirtualnymi ( ping , dhcp , dns oraz ssh ):
add rule inet filter input-kvm meta l4proto icmp counter accept
add rule inet filter input-kvm ip6 nexthdr icmpv6 counter accept
add rule inet filter input-kvm udp sport { 68 } udp dport { 67 } counter accept
add rule inet filter input-kvm udp dport { 53 } counter accept
add rule inet filter input-kvm limit rate 30/minute burst 1 packets log flags all prefix "* IPTABLES:input-kvm * " counter
add rule inet filter input-kvm meta nfproto { ipv4, ipv6} counter reject with icmpx type port-unreachable comment "Reject all connections"
add rule inet filter input-kvm counter drop
add rule inet filter output-kvm meta l4proto icmp counter accept
add rule inet filter output-kvm ip6 nexthdr icmpv6 counter accept
add rule inet filter output-kvm udp sport { 67 } udp dport { 68 } counter accept
add rule inet filter output-kvm tcp dport { 22 } counter accept
add rule inet filter output-kvm limit rate 30/minute burst 1 packets log flags all prefix "* IPTABLES:output-kvm * " counter
add rule inet filter output-kvm meta nfproto { ipv4, ipv6} counter reject with icmpx type port-unreachable comment "Reject all connections"
add rule inet filter output-kvm counter drop
Dalej konfigurujemy forwarding pakietów oraz NAT:
create chain ip nat kvm
create chain inet filter kvm
create chain inet filter kvm-user
create chain inet filter kvm-isolation-stage-1
create chain inet filter kvm-isolation-stage-2
add rule inet filter FORWARD counter jump kvm-user
add rule inet filter FORWARD counter jump kvm-isolation-stage-1
add rule inet filter FORWARD meta oifname "virbr0" counter jump check-state
add rule inet filter FORWARD meta oifname "virbr0" counter jump kvm
add rule inet filter FORWARD meta iifname "virbr0" meta oifname != "virbr0" counter accept
add rule inet filter FORWARD meta iifname "virbr0" meta oifname "virbr0" counter accept
add rule ip nat PREROUTING fib daddr type local counter jump kvm
add rule ip nat OUTPUT ip daddr != { 127.0.0.0/8 } fib daddr type local counter jump kvm
add rule ip nat POSTROUTING meta oifname != "virbr0" ip saddr { 192.168.122.0/24 } counter masquerade
add rule ip nat kvm meta iifname "virbr0" counter return
add rule inet filter kvm-isolation-stage-1 meta iifname "virbr0" meta oifname != "virbr0" counter jump kvm-isolation-stage-2
add rule inet filter kvm-isolation-stage-2 meta oifname "virbr0" counter drop
add rule inet filter kvm meta iifname { "bond0" , "wwan0" , "usb0", "eth0", "wlan0" } counter drop comment "block external access to kvm network"
Ta powyższa konfiguracja filtra nftables pozwala na ograniczoną komunikację maszyn wirtualnych z
maszyną hosta. Dodatkowo zezwala na komunikację między maszynami wirtualnymi. Przy pomocy
translacji adresów (NAT) mamy możliwość dostępu do internetu na maszynach wirtualnych.
Nie zapomnijmy też dodać do /etc/sysctl.conf poniższego parametru:
net.ipv4.ip_forward = 1
Test konfiguracji połączenia sieciowego maszyn wirtualnych
Przetestujmy czy internet w maszynie wirtualnej działa (ten adres 192.168.1.150, to adres maszyny hosta):
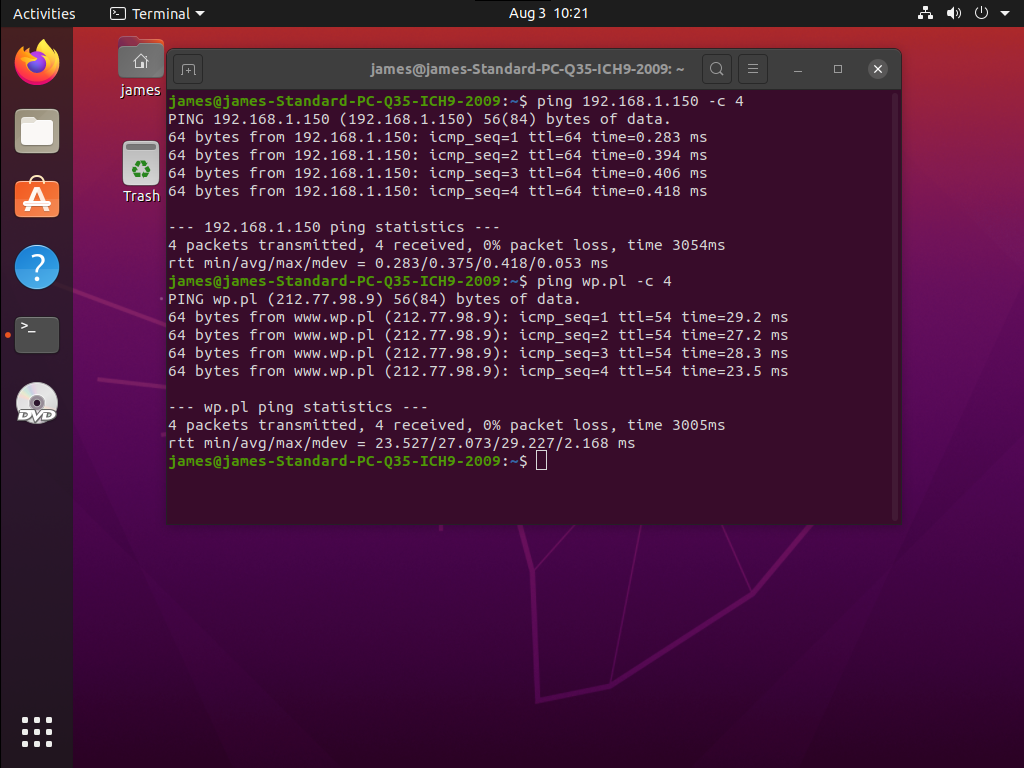
Zatem połączenie z internetem na maszynie wirtualnej można uzyskać. Podobnie też host bez problemu jest w stanie ping'nąć maszynę wirtualną:
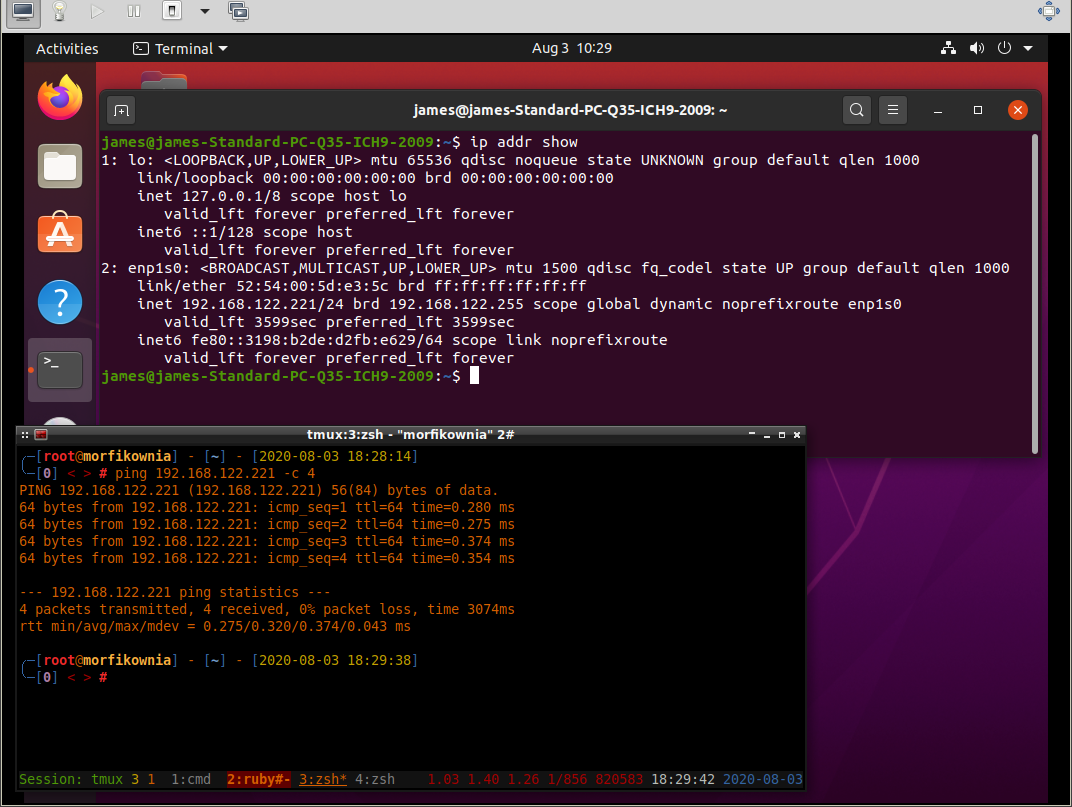
No i na koniec sprawdzenie połączenia między dwiema maszynami wirtualnymi:
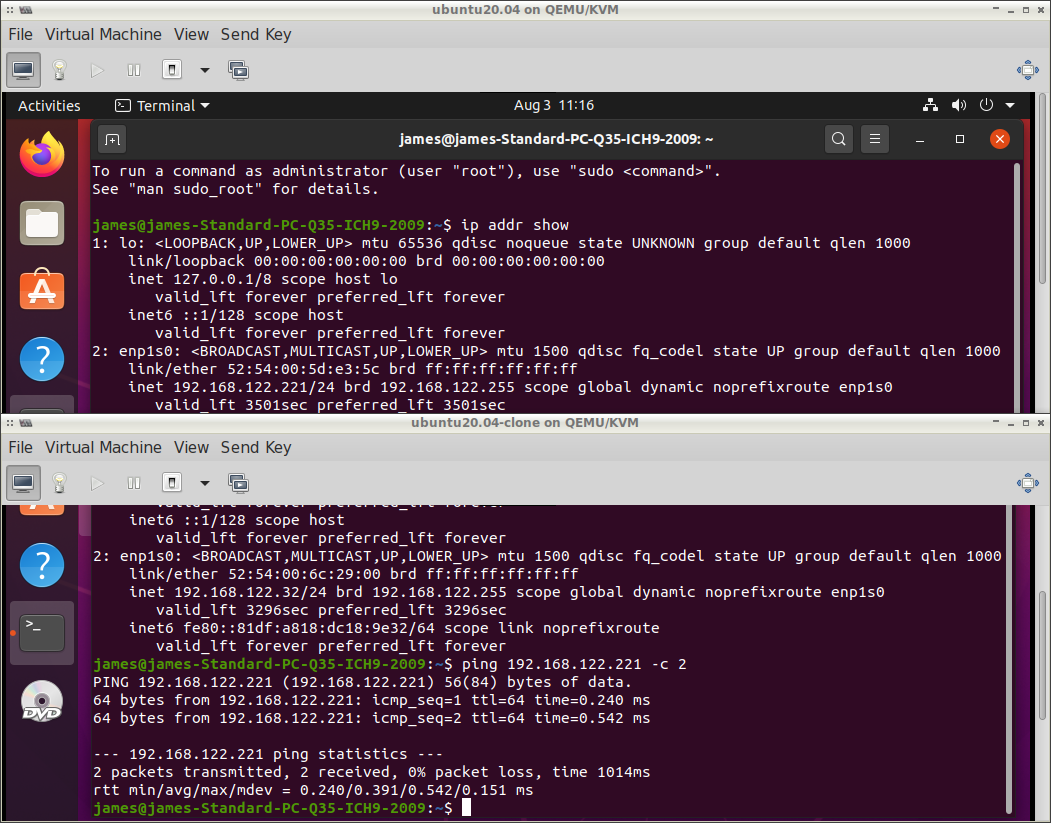
Wygląda, że połączenie sieciowe działa tak jak byśmy tego oczekiwali.
Dostęp do maszyny wirtualnej po SSH
Jeśli nie zamierzamy korzystać z protokołu SPICE/VNC przy dostępie do maszyn wirtualnych i zamiast
w trybie GUI chcielibyśmy operować w trybie tekstowym (via SSH), to musimy w systemie gościa
doinstalować pakiet openssh-server :
# apt-get install openssh-server
Jeśli usługa SSH na maszynie wirtualnej nie została automatycznie uruchomiona, to trzeba ją ręcznie uruchomić i dodać do autostartu:
# systemctl enable ssh.service
# systemctl start ssh.service
Teraz z maszyny hosta można się łączyć po SSH do maszyny wirtualnej w poniższy sposób:
$ ssh morfik@192.168.122.221
SSHFS
Jeśli chcielibyśmy mieć możliwość montowania katalogów maszyny wirtualnej w obrębie systemu plików
maszyny hosta, to trzeba w systemie gościa doinstalować pakiet openssh-sftp-server (powinien
zainstalować się razem z serwerem SSH):
# apt-get install openssh-sftp-server
Przy pomocy sshfs możemy zamontować dowolny katalog maszyny wirtualnej na maszynie hosta, choć
my ograniczymy się jedynie do katalogu domowego. Zatem na maszynie hosta wydajemy to poniższe
polecenie (trzeba doinstalować pakiet sshfs):
$ sshfs james@ubuntu.libvirt:/home/james/ ~/Desktop/ubuntu-vm
james@ubuntu.libvirt's password:
To polecenie zamontuje katalog domowy użytkownika james maszyny wirtualnej ubuntu.libvirt na
maszynie hosta w katalogu ~/Desktop/ubuntu-vm/ . Po przejściu do katalogu ~/Desktop/ubuntu-vm/
dowolnym menadżerze plików, będziemy mieli listing plików katalogu domowego użytkownika james .
Na tych plikach możemy operować dokładnie w taki sam sposób jak na lokalnych plikach maszyny hosta.
Jeśli stworzymy/usuniemy/edytujemy jakiś plik w katalogu ~/Desktop/ubuntu-vm/ , to wszystkie te
zmiany natychmiast dostrzeże użytkownik james wewnątrz maszyny wirtualnej. Jeśli zaś chcielibyśmy
skopiować jakiś plik z maszyny wirtualnej gościa na maszynę hosta, to wystarczy zwykłe CRTL+C i
CTRL+V do dowolnego katalogu na maszynie hosta (podobnie też w drugą stronę). Dodatkowo możemy np.
odtworzyć film z maszyny wirtualnej na maszynie hosta bez potrzeby kopiowania w tym celu plików na
maszynę hosta.
Współdzielenie katalogów maszyny hosta z maszyną wirtualną
SSHFS ma swoje zalety ale też ma jedną wadę. Chodzi o brak możliwości dzielenia systemu plików w obie strony, czyli jeśli zamontujemy katalog maszyny wirtualnej na maszynie hosta, to host ma pełny dostęp do katalogu gościa, ale jednocześnie gość nie ma w zasadzie żadnego dostępu do katalogów maszyny hosta. W takiej sytuacji trzeba kopiować pliki z maszyny hosta na maszynę wirtualną, co niekoniecznie ma sens, no i oczywiście zajmuje czas, zwłaszcza gdy to są większe pliki. Dlatego też w takich sytuacjach można zrezygnować z SSHFS na rzecz współdzielenia katalogów maszyny hosta z maszyną wirtualną.
Szukając na necie jak rozwiązać ten problem znalazłem w zasadzie trochę informacji na temat
V9FS, tj. UNIX'owej implementacji protokołu zdalnego systemu plików 9P (Plan 9). Założenia są
proste, tj. trzeba stworzyć nowe urządzenie w virt-manager typu system plików (filesystem) i
wskazać w nim ścieżkę do katalogu hosta, którą chcemy udostępnić, mniej więcej tak jak na poniższej
fotce:
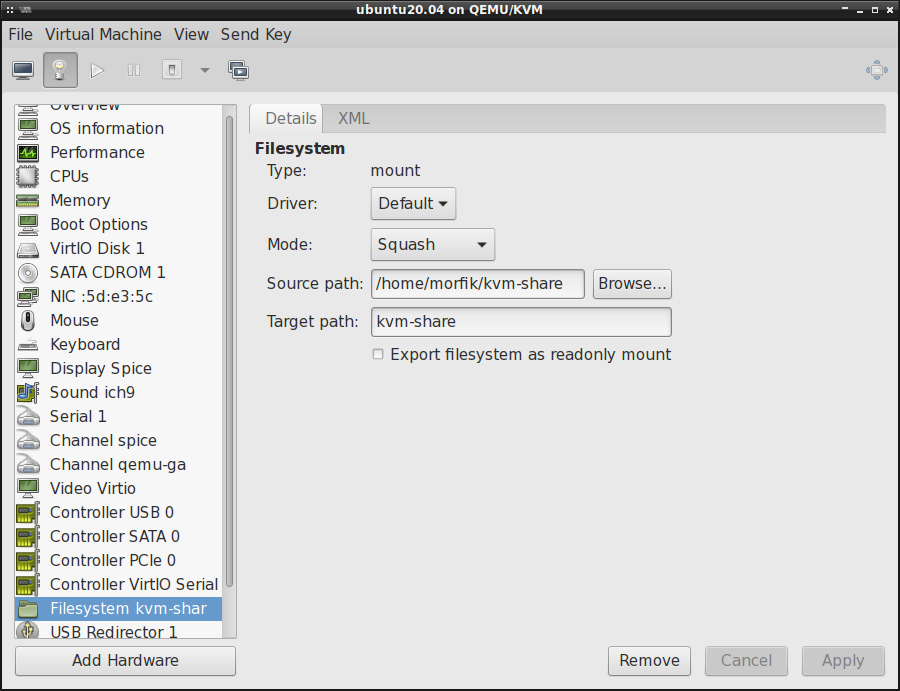
W Source Path podajemy ścieżkę do katalogu hosta, zaś Target Path jest ździebko mylącą nazwą,
bo oznacza ona w zasadzie jedynie TAG (zwykłą nazwę, a nie ścieżkę). Tak czy inaczej, to co
określimy w polu Target Path będzie wykorzystywane w późniejszym czasie. Jeśli chodzi zaś o
Driver , to zostawiamy domyślny ale w polu Mode trzeba określić Squash , by uniknąć problemów
z uprawnieniami do plików.
Po dodaniu tak stworzonego urządzenia, uruchamiamy maszynę wirtualną, odpalamy w niej terminal i logujemy się na użytkownika root. Następnie w oknie terminala wpisujemy poniższe polecenie:
# mount kvm-share -t 9p -o trans=virtio -oversion=9p2000.L /home/james/kvm-share/
Od tej chwili powinniśmy mieć dostęp do plików hosta z poziomu maszyny wirtualnej.
By nie wpisywać z każdym uruchomieniem maszyny wirtualnej tego powyższego polecenia, dobrze jest
dodać w systemie gościa do /etc/fstab poniższy wpis:
kvm-share /home/james/kvm-share/ 9p trans=virtio,version=9p2000.L 0 0
Problemy z uprawnieniami
Teoretycznie po wydaniu tych powyższych poleceń wszystko powinno zadziałać cacy. Problem w tym, że
w Debianie proces qemu jest uruchomiony jako użytkownik/grupa libvirt-qemu . W ten sposób
pojawiają się problemy z uprawnieniami do plików w tym współdzielonym katalogu. Parametr Mode ,
który można było ustawić przy tworzeniu zasobu w virt-manager , mógł w zasadzie przyjąć trzy
wartości: Mapped , Passthrough oraz Squash (który jest aliasem na None). Wybór każdego z
nich inaczej konfiguruje uprawnienia do plików.
Tryb Squash
Z tego co znalazłem, to ten Squash powinien umożliwić zapis/odczyt współdzielonego katalogu w obu
kierunkach ale tylko w przypadku, gdy proces maszyny wirtualnej jest uruchomiony jako zwykły
użytkownik (ten, który udostępnia zasób).
Tryb Mapped
Jeśli zaś chodzi o Mapped , to każdy plik/katalog utworzony na maszynie wirtualnej będzie w
maszynie hosta miał właściciela/grupę libvirt-qemu oraz uprawnienia dostępu tylko dla właściciela.
Weźmy przykładowo sytuację, w której na maszynie wirtualnej tworzymy katalog i plik testowy w
udostępnionym folderze:
james@ubuntu:~$ mkdir kvm-share/testdir
james@ubuntu:~$ touch kvm-share/testfile
james@ubuntu:~$ ls -al kvm-share/
total 20
drwxrwx--- 3 james 64055 4096 Aug 7 10:22 .
drwxr-xr-x 19 james james 4096 Aug 7 10:22 ..
drwxrwxr-x 2 james james 4096 Aug 7 10:22 testdir
-rw-rw-r-- 1 james james 0 Aug 7 10:22 testfile
Ten numerek 64055 widoczny wyżej odpowiada grupie libvirt-qemu w obrębie maszyny hosta.
Na maszynie hosta, ten katalog współdzielony wygląda tak:
# ls -al /home/morfik/kvm-share/
total 20
drwxrwx--- 3 morfik libvirt-qemu 4096 2020-08-07 18:22:28 ./
drwxr-xr-x 86 morfik morfik 4096 2020-08-07 17:59:27 ../
drwx------ 2 libvirt-qemu libvirt-qemu 4096 2020-08-07 18:22:20 testdir/
-rw------- 1 libvirt-qemu libvirt-qemu 0 2020-08-07 18:22:28 testfile
Pierw trzeba było zmienić grupę tego katalogu na libvirt-qemu oraz nadać tej grupie prawa rwx
(bez tego użytkownik na maszynie wirtualnej nie miał praw dostępu do tego katalogu). A po
utworzeniu plików na maszynie wirtualnej, te same pliki na hoście mają innego użytkownika, grupę i
uprawnienia. W efekcie zwykły użytkownik na maszynie hosta nie ma nawet do nich dostępu.
Tryb Passthrough
Ostatnią opcją był Passthrough , który też nie jest w stanie poprawić problemów z uprawnieniami
do katalogu współdzielonego. Nawet można powiedzieć, że tylko pogorszył sprawę:
james@ubuntu:~$ ls -al kvm-share/
total 8
drwxrwx--- 2 james 64055 4096 Aug 7 10:31 .
drwxr-xr-x 19 james james 4096 Aug 7 10:22 ..
james@ubuntu:~$
james@ubuntu:~$ mkdir kvm-share/testdir
mkdir: cannot create directory ‘kvm-share/testdir’: Operation not permitted
james@ubuntu:~$ mkdir kvm-share/testfile
mkdir: cannot create directory ‘kvm-share/testfile’: Operation not permitted
Zatem w przypadku Passthrough nie jesteśmy nawet w stanie nic utworzyć w tym współdzielonym
katalogu, przynajmniej jeśli chodzi o maszynę wirtualną.
Nie wiem zbytnio jak to udostępnianie katalogów ma działać skoro albo host, albo maszyna wirtualna ma problemy z wgrywaniem plików do tego współdzielonego katalogu. Jeśli ktoś ma pomysł jak sprawić, by to udostępnianie folderów zadziałało, to niech śmiało pisze, bo mi się już pomysły skończyły.
Udostępnianie maszynie wirtualnej całego dysku/partycji
Wygląda na to, że nie tylko pojedyncze foldery hosta można podpiąć pod maszynę wirtualną ale też
można w systemie gościa zamontować cały dysk twardy hosta czy też konkretne jego partycje. W tym
celu trzeba stworzyć nowe urządzenie typu storage :
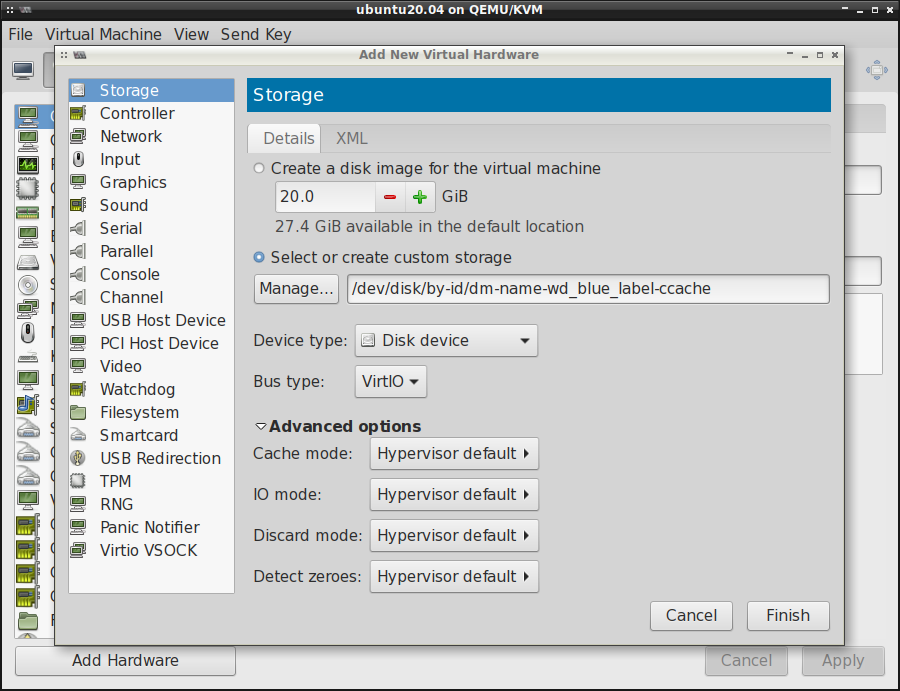
W ścieżce musimy podać lokalizację dysku/partycji w katalogu /dev/ hosta. Najlepiej jest to
zrobić po ID, jako że numerki typu sda/sdb mogą ulec zmianie z każdym restartem maszyny hosta.
Linki z ID możemy wyciągnąć z katalogu /dev/disk/by-id/ :
Wybieramy jedną z tych widocznych wyżej ścieżek, i podajemy ją w virt-manager . Po dodaniu nowego
urządzenia, powinno ono znaleźć się na liście i powinno się prezentować mniej więcej tak:
Możemy teraz wystartować maszynę wirtualną by sprawdzić, czy ten dodatkowy zasób jest widoczny w systemie gościa:
Jak widać, partycja dysku hosta, jest obecna w systemie gościa.
Ryzyko uszkodzenia danych zgromadzonych na dysku/partycji
W przypadku montowania całych dysków lub pojedynczych partycji hosta w systemie gościa trzeba być dość ostrożnym. Testowo zamontowałem tę partycję zarówno w systemie gościa jak i hosta w trybie do zapisu. Samo zamontowanie przebiegło bez większego problemu. Postanowiłem z poziomu gościa stworzyć katalog na tej partycji, po czym po chwili go usunąłem i tu już pojawiły się problemy.
Po skasowaniu katalogu z poziomu maszyny wirtualnej, system hosta w dalszym ciągu ten katalog widział. W logu systemowym maszyny hosta zaś pojawiły się takie oto komunikaty błędów:
kernel: EXT4-fs error (device dm-4): ext4_mb_generate_buddy:805: group 48, block bitmap and bg descriptor inconsistent: 0 vs 1 free clusters
kernel: Aborting journal on device dm-4-8.
kernel: EXT4-fs (dm-4): Remounting filesystem read-only
kernel: EXT4-fs error (device dm-4) in ext4_free_blocks:5140: Journal has aborted
kernel: EXT4-fs error (device dm-4) in ext4_reserve_inode_write:5652: Journal has aborted
kernel: EXT4-fs error (device dm-4): __ext4_ext_dirty:169: inode #516422: comm spacefm: mark_inode_dirty error
kernel: EXT4-fs error (device dm-4) in ext4_reserve_inode_write:5652: Journal has aborted
kernel: EXT4-fs error (device dm-4): __ext4_ext_dirty:169: inode #516422: comm spacefm: mark_inode_dirty error
kernel: EXT4-fs error (device dm-4) in ext4_ext_remove_space:3030: Journal has aborted
kernel: EXT4-fs error (device dm-4) in ext4_reserve_inode_write:5652: Journal has aborted
kernel: EXT4-fs error (device dm-4): ext4_truncate:4240: inode #516422: comm spacefm: mark_inode_dirty error
kernel: EXT4-fs error (device dm-4) in ext4_truncate:4243: Journal has aborted
System zdecydował się przemontować od razu tę partycję w tryb tylko do odczytu by zapobiec utracie danych -- na wypadek, gdybyśmy zaczęli wgrywać dane również z maszyny hosta na tę partycję. Ten powyższy błąd nie jest jakoś straszny i w zasadzie nic się z tą partycją nie stało ale zamontowanie dysku/partycji na obu maszynach w trybie do zapisu skończy się rozwaleniem jej systemu plików i, co z tym się wiąże, utratą zgromadzonych na niej danych. Dlatego też jeśli zamierzamy podpinać całe dyski czy też partycje hosta po maszynę wirtualną, to w systemie hosta przemontujmy ją pierw w tryb do odczytu albo też w ogóle ją odmontujmy, tak by maszyna wirtualna miała do tego nośnika swobodny dostęp.
Hostname maszyn wirtualnych zamiast ich adresów IP
Mając wiele maszyn wirtualnych oraz serwer DHCP, który im przydziela adresację w sposób dynamiczny,
w którymś momencie stanie się dość męczące łączenie do maszyn przy pomocy ich adresów IP. Możemy za
to tak skonfigurować sobie system, by łączyć się do maszyn wirtualnych wykorzystując ich nazwy
hosta (hostname). W tym celu trzeba skonfigurować dnsmasq na maszynie hosta. Nie będę tutaj
opisywał całego procesu konfiguracji dnsmasq , bo to zostało zrobione w osobnym artykule, a
jedynie opiszę tutaj kluczowe parametry konfiguracyjne, które powinny się znaleźć w pliku
/etc/dnsmasq.conf .
Przy założeniu, że mamy działający już dnsmasq , te poniższe linijki winny się znaleźć w pliku
/etc/dnsmasq.conf :
stop-dns-rebind
rebind-localhost-ok
rebind-domain-ok=libvirt
server=/libvirt/192.168.122.1
jeśli korzystamy z stop-dns-rebind , to trzeba także określić rebind-localhost-ok oraz
rebind-domain-ok= , który wskazuje na domenę maszyn wirtualnych. W tym przypadku domena maszyn
wirtualnych została ustawiona na libvirt , choć można sobie określić dowolną nazwę.
Dalej musimy edytować sieć, do której maszyny wirtualne są podłączane:
# virsh net-edit default
Trzeba tutaj dodać <domain name='libvirt' localOnly='yes'/> , gdzie parametr name= pasuje do
tego, który ustawiliśmy w pliku /etc/dnsmasq.conf :
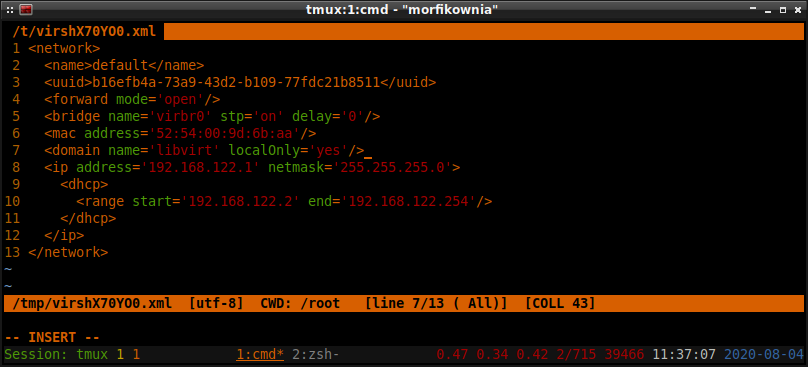
Następnie uruchamiamy maszynę wirtualną i ustawiamy jej pożądany hostname przy pomocy
hostnamectl :
# hostnamectl set-hostname ubuntu.libvirt
Po tym zabiegu restartujemy maszynę wirtualną, a z maszyny hosta próbujemy podłączyć się do systemu gościa przy pomocy SSH z tym, że zamiast adresu IP, korzystamy teraz z tego ustawionego wyżej hostname:
$ ssh james@ubuntu.libvirt
Jeśli wszystko ustawiliśmy jak należy, to naszym oczom powinien ukazać się prompt systemu gościa:
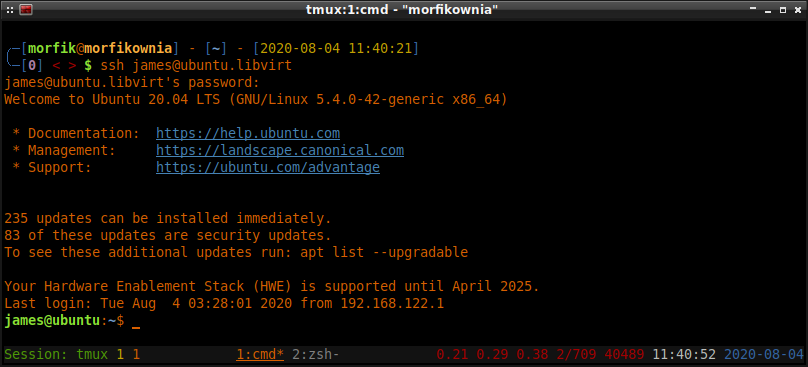
Jeśli z jakichś powodów nie działa nam rozwiązywanie nazw maszyn wirtualnych, to trzeba poszukać
przyczyny i najlepiej zacząć od sprawdzenia, czy dnsmasq w ogóle te nazwy rozwiązuje. By ten fakt
ustalić, na maszynie hosta wydajemy poniższe polecenie:
# kill -s USR1 `pidof dnsmasq`
W logu systemowym powinniśmy zaś ujrzeć komunikaty podobne do tych poniżej:
dnsmasq[3148]: time 1596533285
dnsmasq[3148]: cache size 10000, 0/262 cache insertions re-used unexpired cache entries.
dnsmasq[3148]: queries forwarded 336, queries answered locally 165
dnsmasq[3148]: queries for authoritative zones 0
dnsmasq[3148]: pool memory in use 288, max 288, allocated 2400
dnsmasq[3148]: server 192.168.122.1#53: queries sent 2, retried or failed 0
dnsmasq[3148]: server 192.168.1.1#53: queries sent 0, retried or failed 0
dnsmasq[3148]: server 127.0.2.1#53: queries sent 334, retried or failed 2
Jeśli mamy odpalone maszyny wirtualne, to w tym logu będzie więcej takich zwrotek (po jednej
dodatkowej na każda uruchomioną maszynę wirtualną). Odszukujemy te komunikaty, które dotyczą
naszego dnsmasq i patrzymy po adresie IP 192.168.122.1 . Jeśli przy nim widnieje queries sent
w ilości większej od 0 i nie ma przy tym żadnych zapytań nieudanych, to znaczy, że wszystko działa
jak należy.
Systemowy interfejs mostka dla maszyn wirtualnych
Domyślnie w libvirt jest stworzona jedna sieć i wszystkie maszyny wirtualne są do niej podłączane
automatycznie. Ta sieć przy podnoszeniu tworzy interfejs mostka virbr0 (konfiguracja w pliku
/etc/libvirt/qemu/networks/default.xml ), dzięki czemu może być realizowany NAT. Poniżej jest
konfiguracja tej domyślnej sieci:
<network>
<name>default</name>
<uuid>b16efb4a-73a9-43d2-b109-77fdc21b8511</uuid>
<forward mode='open'/>
<bridge name='virbr0' stp='on' delay='0'/>
<mac address='52:54:00:9d:6b:aa'/>
<domain name='libvirt' localOnly='yes'/>
<ip address='192.168.122.1' netmask='255.255.255.0'>
<dhcp>
<range start='192.168.122.2' end='192.168.122.254'/>
</dhcp>
</ip>
</network>
Nie jestem fanem takiego rozwiązania i zamiast niego preferuję statycznie konfigurowane interfejsy
sieciowe za sprawą pliku /etc/network/interfaces . By z takiego rozwiązania skorzystać, trzeba
ręcznie stworzyć i skonfigurować mostek dodając poniższą zwrotkę w pliku /etc/network/interfaces :
auto virbr0
iface virbr0 inet static
bridge_bridgeprio 20
address 192.168.122.1
netmask 255.255.255.0
bridge_ports none
bridge_stp on
bridge_waitport 5
dns-nameservers 127.0.0.1
dns-search libvirt
Konfiguracja mostka virbr0 widoczna powyżej jest wzorowana na konfiguracji tego dynamicznie
tworzonego mostka przez libvirt przy podnoszeniu sieci wirtualnej ( virsh net-start default ).
Warto też zwrócić uwagę na fakt ustawienia dns-nameservers na 127.0.0.1 . Dzięki takiemu
zabiegowi, zapytania DNS będą przesyłane do instancji dnsmasq hosta, a nie bezpośrednio do
upstream'owych serwerów DNS.
By maszyny wirtualne mogły z tego mostka skorzystać, trzeba zdefiniować nową sieć wirtualną.
Najprościej jest stworzyć nowy plik /etc/libvirt/qemu/networks/host-bridge.xml i dodać do niego
poniższą zawartość:
<network>
<name>host-bridge</name>
<forward mode="bridge"/>
<bridge name="virbr0"/>
</network>
Następnie restartujemy demona libvirtd :
# systemctl restart libvirtd
Ta nowa sieć powinna pojawić się na listingu sieci w virt-manager :
Teraz przy tworzeniu maszyn wirtualnych wystarczy wybrać tę utworzoną przez nas sieć:
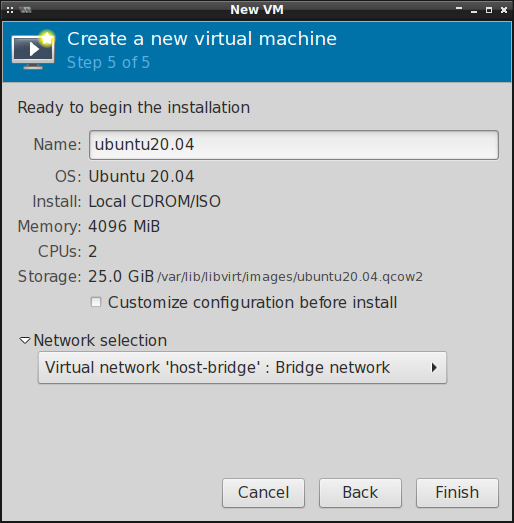
I w ten sposób tak stworzone maszyny wirtualne będą przypisane automatycznie do tego statycznego interfejsu mostka.
Jeśli zaś chodzi o maszyny wirtualne, które już mamy utworzone, to trzeba edytować ich konfigurację zmieniając przypisanie do tej nowej, utworzonej przez nas sieci:
Jedna instancja dnsmasq
W przypadku korzystania z domyślnej sieci dla maszyn wirtualnych, libvrit tworzy dla niej osobny
proces dnsmasq przy podnoszeniu sieci. Może to powodować problemy zwłaszcza, gdy sami już
korzystamy z dnsmasq . W takiej sytuacji najlepiej jest skonfigurować własny interfejs mostka
oraz korzystać z jednej instancji dnsmasq , tj. tej uruchomionej na stałe na hoście, tak by
zapewnić zarówno maszynie hosta, jak i maszynom wirtualnym, dynamiczny przydział adresów IP za
pomocą protokołu DHCP oraz usługi DNS. Edytujemy zatem plik /etc/dnsmasq.conf na maszynie hosta i
dodajemy w nim te poniższe wpisy:
interface=virbr0
bind-interfaces
domain=libvirt,192.168.122.2,192.168.122.254,
dhcp-range=192.168.122.2,192.168.122.254,255.255.255.0,12h
dhcp-lease-max=253
dhcp-authoritative
Podobnie jak w przypadku konfiguracji mostka, konfiguracja dnsmasq jest wzorowana na tej
dostarczanej z libvirt, by oba rozwiązania były możliwie zbliżone do siebie.
Trzeba tutaj określić interfejs mostka, w tym przypadku virbr0 . Dodatkowo, dla maszyn
wirtualnych będzie obowiązywać inna domena, tj. libvirt . Sam mostek ma statyczną konfigurację
adresacji IP (192.168.122.1), dlatego też zakres adresów IP, które są oddelegowane do wykorzystania
przez maszyny wirtualne to 192.168.122.2 do 192.168.122.254 (łącznie 253 lease mogą zostać
wydane).
Teraz już powinna być tylko jedna instancja dnsmasq obecna w systemie hosta:
# ps aux | grep -i dnsmasq
dnsmasq 3231 0.0 0.0 18296 3600 ? S 15:24 0:00 /usr/sbin/dnsmasq -x /run/dnsmasq/dnsmasq.pid -u dnsmasq -7 /etc/dnsmasq.d,.dpkg-dist,.dpkg-old,.dpkg-new --local-service
Zmiana rozmiaru obrazu maszyny wirtualnej
Rozmiar pliku .qcow2 , który przechowuje obraz maszyny wirtualnej, można zmienić. Możemy zarówno
zmniejszyć rozmiar obrazu maszyny wirtualnej, jak i również go zwiększyć. Cały proces zmiany
rozmiaru obrazu został opisany w osobnym artykule.