Badsector dysku HDD w kontenerze LUKS zawierającym LVM
Spis treści
Podczas rutynowego skanu powierzchni dysków HDD w moim laptopie, S.M.A.R.T wykrył w jednym z nich
podejrzany blok, który zdawał się wyzionąć już ducha, przez co proces weryfikacji integralności
powierzchni dysku twardego nie był w stanie zakończyć się z powodzeniem. Komunikat zwracany przy
czytaniu padniętego sektora też był nieco dziwny: bad/missing sense data, sb[] . Jakiś czas temu
już opisywałem jak realokować uszkodzony sektor dysku HDD i w zasadzie wszystkie informacje
zawarte w tamtym artykule można by wykorzystać do próby poprawienia zaistniałego problemu, gdyby
tylko nie fakt, że w tym przypadku badblock znalazł się w obszarze voluminu logicznego LVM na
partycji zaszyfrowanej przy pomocy mechanizmu LUKS. Taki schemat układu partycji sprawia, że do
realokowania błędnego bloku trzeba podejść nieco inaczej uwzględniając w tym procesie kilka
offset'ów, bez których w zasadzie nic nie da się zrobić. Postanowiłem zatem napisać na konkretnym
przykładzie jak realokować badsector dysku, gdy do czynienia mamy z zaszyfrowanym linux'em
zainstalowanym na voluminach LVM.
Błędy dysku
Wszystko zaczęło się od niewinnego skanu S.M.A.R.T, bo do chwili jego wykonania w zasadzie mój Debian jak i dysk, na którym ten system jest zainstalowany, działał bez zarzutu. W logu systemowym nie było żadnych komunikatów świadczących o jakiekolwiek awarii nośnika, czy ewentualnych problemach z odczytem jego powierzchni. Niemniej jednak, w raporcie S.M.A.R.T widniał taki oto błąd:
Error 4 [3] occurred at disk power-on lifetime: 22336 hours (930 days + 16 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER -- ST COUNT LBA_48 LH LM LL DV DC
-- -- -- == -- == == == -- -- -- -- --
40 -- 51 00 01 00 00 00 5e a7 db e0 00 Error: UNC at LBA = 0x005ea7db = 6203355
Commands leading to the command that caused the error were:
CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name
-- == -- == -- == == == -- -- -- -- -- --------------- --------------------
20 00 00 00 01 00 00 00 5e a7 db e0 00 01:47:04.105 READ SECTOR(S)
ec 00 00 00 01 00 00 00 00 00 00 40 00 01:47:04.103 IDENTIFY DEVICE
ef 00 10 00 03 00 00 00 00 00 00 a0 00 01:47:01.930 SET FEATURES [Enable SATA feature]
ef 00 10 00 02 00 00 00 00 00 00 a0 00 01:47:01.920 SET FEATURES [Enable SATA feature]
ec 00 00 00 00 00 00 00 00 00 00 a0 00 01:47:01.918 IDENTIFY DEVICE
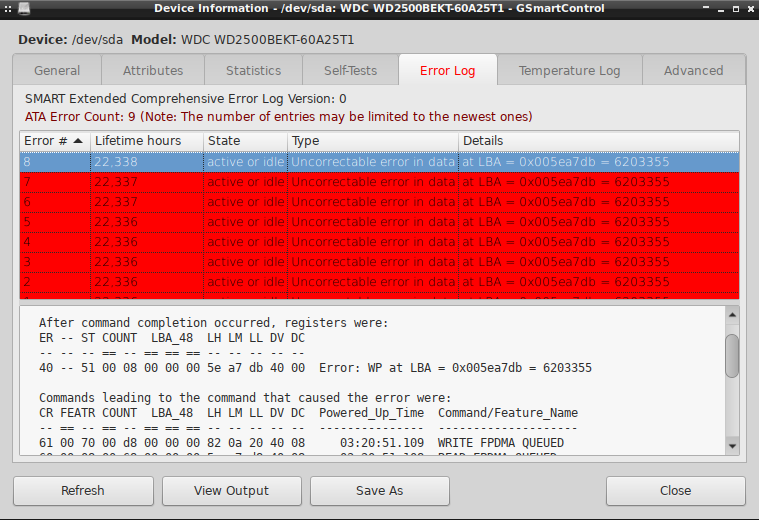
No i widać tutaj Error: UNC at LBA oraz numer bloku, do którego ten błąd się odnośni: 6203355 .
Właściwie to tych błędów było kilka, co musiało oczywiście przerwać proces skanowania:
Patrząc w podsumowanie raportu parametrów dysków, można zauważyć, że ten sektor został przeznaczony do realokacji:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
...
5 Reallocated_Sector_Ct PO--CK 200 200 140 - 0
...
196 Reallocated_Event_Count -O--CK 200 200 000 - 0
197 Current_Pending_Sector -O--CK 200 200 000 - 1
198 Offline_Uncorrectable ----CK 100 253 000 - 0
Wygląda na to, że są jakieś większe problemy z odczytaniem tego bloku numer 6203355 . Spróbujmy
zatem odczytać go ręcznie:
# time hdparm --read-sector 6203355 /dev/sda
/dev/sda:
reading sector 6203355: SG_IO: bad/missing sense data, sb[]: 70 00 03 00 00 00 00 0a 40 51 e0 01 11 04 00 00 00 db 00 00 00 00 00 00 00 00 00 00 00 00 00 00
succeeded
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0000
0.00s user 0.01s system 0% cpu 2.174 total
To dopiero ciekawa przypadłość, bo niby hdparm udało się odczytać ten sektor ( succeeded ) ale
błąd bad/missing sense data, sb[]: nie brzmi jakość szczególnie miło. Jeśli zwrócimy uwagę na
czas w jakim ten sektor został odczytany, to widać, że ta czynność zajęła ponad 2 sekundy. W
przypadku czytania zdrowego sektora otrzymuje się coś na poniższy wzór:
# time hdparm --read-sector 6203356 /dev/sda
/dev/sda:
reading sector 6203356: succeeded
...
0.00s user 0.00s system 22% cpu 0.021 total
Nie ma zatem ani widocznego wyżej błędu, a sam odczyt to kwestia kilku milisekund.
Warto tutaj zaznaczyć, że podczas czytania tego badsector'a przy pomocy hdparm , w logu
systemowym nie pojawiły się jakiekolwiek błędy. To trochę dziwna sytuacja, bo zwykle w takich
przypadkach system powinien zacząć narzekać, że coś uniemożliwia poprawne czytanie powierzchni
dysku.
Czym jest bad/missing sense data
Z początku nie miałem pojęcia jak zinterpretować ten błąd bad/missing sense data i te wartości
HEX, które zostały zwrócone. Ten cały komunikat można jednak zdekodować przy pomocy narzędzia
sg_decode_sense zawartego w Debianie w pakiecie sg3-utils :
$ sg_decode_sense 70 00 03 00 00 00 00 0a 40 51 e0 01 11 04 00 00 00 db 00 00 00 00 00 00 00 00 00 00 00 00 00 00
Fixed format, current; Sense key: Medium Error
Additional sense: Unrecovered read error - auto reallocate failed
Wygląda na to, że mamy do czynienia z uszkodzonym blokiem dysku, który wymaga ręcznej realokacji.
Ustalenie partycji z badblock'iem
Gdy przytrafi nam się ten cały bad/missing sense data , to nie ma innego wyjścia jak realokować
blok danych, który powoduje błąd odczytu. Całą zabawę zaczynamy standardowo od ustalenia przy
pomocy fdisk/gdisk (czy innych narzędzi do partycjonowania dysku), na której partycji ten
padnięty sektor się znajduje:
# fdisk -l /dev/sda
Disk /dev/sda: 232.9 GiB, 250059350016 bytes, 488397168 sectors
Disk model: WDC WD2500BEKT-6
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x0006320c
Device Boot Start End Sectors Size Id Type
/dev/sda1 * 2048 4196351 4194304 2G 83 Linux
/dev/sda2 4196352 488396799 484200448 230.9G 83 Linux
Jako, że numer problematycznego bloku wskazuje na 6203355 , to wiadomo, że znajduje się on na
partycji sda2 , bo 6203355 zawiera się w przedziale między 4196352 a 488396799 . W tym
przypadku jest to zaszyfrowany kontener LUKS z kilkoma voluminami logicznymi LVM w środku.
Offset badblock'u
Mając informacje o początku partycji musimy znaleźć offset badblock'u względem tej partycji.
Odejmujemy zatem od numeru LBA (widocznego w logu S.M.A.R.T) wartość w kolumnie start (widoczną
wyżej w wyjściu fdisk ) dla partycji sda2 : 6203355 − 4196352 = 2007003 .
Rozmiar fizycznego zakresu bloków LVM
Musimy teraz znaleźć volumin logiczny LVM, do którego ten uszkodzony blok należy. Ustalamy na początek rozmiar fizycznego zakresu bloków LVM (Physical Extent, PE):
# pvdisplay -c /dev/mapper/sda2_crypt | awk -F: '{print $8}'
4096
Rozmiar fizycznego zakresu to 4096 KiB, czyli 4 MiB (standardowy kawałek).
Ten dysk ma 512 bajtowe sektory, czyli 0,5 KiB. Musimy to uwzględnić w wyliczeniach i pomnożyć
otrzymaną wyżej wartość przez 2, co daje nam 4096 * 2 = 8192 bloków na każdy fizyczny zakres LVM
(8192 * 512 = 4194304, czyli również 4 MiB).
Dyski logiczne nie zaczynają się zaraz na początku partycji fizycznej dysku HDD. W tym przypadku na początku partycji znajduje się nagłówek LUKS, a po nim nagłówek LVM. Te dwa offsety musimy znać.
Offset kontenera LUKS
Kontener LUKS zwykle zaczyna się na początku partycji ale zaszyfrowane dane zawarte w nim znajdują
się zaraz za nagłówkiem LUKS. Informacje o przesunięciu tych danych możemy wyciągnąć przez
cryptsetup :
# cryptsetup luksDump /dev/sda2
LUKS header information
Version: 2
Epoch: 7
Metadata area: 16384 [bytes]
Keyslots area: 2064384 [bytes]
UUID: e017ac1c-c46f-4b3f-a319-e1f5ed15144a
Label: wd_black_label
Subsystem: (no subsystem)
Flags: (no flags)
Data segments:
0: crypt
offset: 2097152 [bytes]
length: (whole device)
cipher: aes-xts-plain64
sector: 512 [bytes]
Keyslots:
0: luks2
Key: 512 bits
Priority: normal
Cipher: aes-xts-plain64
Cipher key: 512 bits
PBKDF: argon2i
Time cost: 2
Memory: 1048576
Threads: 1
Salt: 7e d0 31 80 49 c9 ba 1d 86 42 dd 76 69 4e 2a 99
b6 79 82 64 76 0c a0 ad ea 4b 3f 97 66 df 94 3c
AF stripes: 4000
AF hash: sha256
Area offset:32768 [bytes]
Area length:258048 [bytes]
Digest ID: 0
Tokens:
Digests:
0: pbkdf2
Hash: sha512
Iterations: 56888
Salt: 55 6e 7e aa 70 ce 81 e9 23 94 8c 07 35 32 09 9d
4a 06 cb 49 85 b3 4b 4c ec f1 44 18 86 da a8 da
Digest: fe b5 16 eb b3 20 73 9d a7 e2
e9 c8 c4 07 f6 ad 09 06 30 df
Mamy tutaj sekcję Data segments: i w niej offset: 2097152 [bytes] . Jest to 4096 sektorów 512
bajtowych, lub 2 MiB.
Offset LVM
Zakresy voluminów logicznych również nie zaczynają się na początku partycji fizycznej lub (tak jak
w tym przypadku) zaraz za nagłówkiem LUKS. Bezpośrednio za nagłówkiem LUKS znajdują się metadane
LVM. Musimy ustalić, gdzie zaczyna się wobec tego pierwszy fizyczny zakres bloków LVM. To zadanie
można zrealizować na kilka sposobów. Najprościej jest odczytać offset z wyjścia polecenia pvs :
# pvs -o+pe_start /dev/mapper/sda2_crypt
PV VG Fmt Attr PSize PFree 1st PE
/dev/mapper/sda2_crypt wd_black_label lvm2 a-- <230.88g 4.00g 1.00m
W ostatniej kolumnie mamy 1.00m , czyli nasz offset LVM to 1 MiB, co daje 2048 sektorów 512
bajtowych. Możemy to łatwo potwierdzić dodając do powyższego polecenia --units s :
# pvs -o pe_start --units s /dev/mapper/sda2_crypt
1st PE
2048S
Drugim sposobem na ustalenie offsetu fizycznych zakresów LVM jest przejrzenie plików backupu
zlokalizowanych w /etc/lvm/backup/ :
# grep pe_start $(grep -l /dev/mapper/sda2_crypt /etc/lvm/backup/*)
pe_start = 2048
Ustalenie voluminu LVM zawierającego badblock
Mając wartość rozmiaru zakresu fizycznych bloków LVM, która wynosi 8192 , możemy ustalić volumin
logiczny zawierający badblock. W tym celu trzeba podzielić offset padniętego bloku uzyskany w
fdisk przez rozmiar zakresu: 2007003 / 8192 = 244.99548 . Sprawdźmy zatem jak prezentuje się
mapa zakresów dysków LVM:
# lvdisplay --maps wd_black_label | egrep 'Physical|LV Name|Type'
LV Name freespace
Type linear
Physical volume /dev/mapper/sda2_crypt
Physical extents 0 to 15
LV Name root
Type linear
Physical volume /dev/mapper/sda2_crypt
Physical extents 16 to 10255
LV Name home
Type linear
Physical volume /dev/mapper/sda2_crypt
Physical extents 11280 to 27663
LV Name kabi
Type linear
Physical volume /dev/mapper/sda2_crypt
Physical extents 27664 to 59104
Liczba, którą wyżej otrzymaliśmy ( 244.99548 ) znajduje się w zakresie od 16 do 10255 . Zatem
uszkodzony sektor jest gdzieś w obrębie partycji root .
Offset badblock'u w systemie plików ext4
Trzeba jeszcze odszukać ten badblock w systemie plików (w tym przypadku ext4) i ustalić co za plik w tym miejscu rezyduje. Do tego celu potrzebny nam będzie rozmiar bloku systemu plików:
# dumpe2fs /dev/mapper/wd_black_label-root | grep 'Block size'
dumpe2fs 1.45.0 (6-Mar-2019)
Block size: 4096
Widoczna wyżej wartość 4096 (4 KiB) to standardowy rozmiar bloku w systemie plików ext4.
Logiczny volumin LVM, który zawiera badsector, zaczyna się na fizycznym zakresie 16 . Mnożymy tę
wartość przez rozmiar zakresu fizycznego i dodajemy do niego offset samego zakresu LVM jak i offset
kontenera LUKS:
(ilość bloków LVM * rozmiar bloku LVM) + offset fizycznych zakresów + offset LUKS
(16 * 8192) + 2048 + 4096 = 137216
Mamy 512 bajtowe bloki na dysku, zatem uszkodzony blok ma w systemie plików ext4 na partycji root
numer:
(offset bloku w fdisk - offset LUKS+LVM+volumin) / (rozmiar bloku ext4 / rozmiar sektora dysku)
(2007003 - 137216) / (4096 / 512) = 233723.38
Jeśli wszystko wyliczyliśmy prawidłowo, to przy próbie czytania bloku 233723 powinniśmy odnotować
jakieś błędy w logu systemowym lub terminalu . Spróbujmy zatem odczytać ten blok przy pomocy dd :
# dd if=/dev/mapper/wd_black_label-root of=block233723 bs=4096 count=1 skip=233723
dd: error reading '/dev/mapper/wd_black_label-root': Input/output error
0+0 records in
0+0 records out
0 bytes copied, 3.90926 s, 0.0 kB/s
No i tutaj już mamy wyraźny błąd Input/output error . Natomiast w logu systemowym nieco więcej
komunikatów:
kernel: ata1.00: exception Emask 0x0 SAct 0x10 SErr 0x40000 action 0x0
kernel: ata1.00: irq_stat 0x40000008
kernel: ata1: SError: { CommWake }
kernel: ata1.00: failed command: READ FPDMA QUEUED
kernel: ata1.00: cmd 60/08:20:d8:a7:5e/00:00:00:00:00/40 tag 4 ncq dma 4096 in
res 41/40:00:db:a7:5e/00:00:00:00:00/40 Emask 0x409 (media error) <F>
kernel: ata1.00: status: { DRDY ERR }
kernel: ata1.00: error: { UNC }
kernel: ata1.00: configured for UDMA/100
kernel: sd 0:0:0:0: [sda] tag#4 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE
kernel: sd 0:0:0:0: [sda] tag#4 Sense Key : Medium Error [current]
kernel: sd 0:0:0:0: [sda] tag#4 Add. Sense: Unrecovered read error - auto reallocate failed
kernel: sd 0:0:0:0: [sda] tag#4 CDB: Read(10) 28 00 00 5e a7 d8 00 00 08 00
kernel: print_req_error: I/O error, dev sda, sector 6203355 flags 80700
kernel: ata1: EH complete
kernel: ata1.00: exception Emask 0x0 SAct 0x2000 SErr 0x0 action 0x0
kernel: ata1.00: irq_stat 0x40000008
kernel: ata1.00: failed command: READ FPDMA QUEUED
kernel: ata1.00: cmd 60/08:68:d8:a7:5e/00:00:00:00:00/40 tag 13 ncq dma 4096 in
res 41/40:00:db:a7:5e/00:00:00:00:00/40 Emask 0x409 (media error) <F>
kernel: ata1.00: status: { DRDY ERR }
kernel: ata1.00: error: { UNC }
kernel: ata1.00: configured for UDMA/100
kernel: sd 0:0:0:0: [sda] tag#13 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE
kernel: sd 0:0:0:0: [sda] tag#13 Sense Key : Medium Error [current]
kernel: sd 0:0:0:0: [sda] tag#13 Add. Sense: Unrecovered read error - auto reallocate failed
kernel: sd 0:0:0:0: [sda] tag#13 CDB: Read(10) 28 00 00 5e a7 d8 00 00 08 00
kernel: print_req_error: I/O error, dev sda, sector 6203355 flags 0
kernel: Buffer I/O error on dev dm-2, logical block 233723, async page read
kernel: ata1: EH complete
smartd[1636]: Device: /dev/disk/by-id/ata-WDC_WD2500BEKT-60A25T1_WD-WX41A90E5928 [SAT], 1 Currently unreadable (pending) sectors
smartd[1636]: Device: /dev/disk/by-id/ata-WDC_WD2500BEKT-60A25T1_WD-WX41A90E5928 [SAT], SMART Usage Attribute: 187 Reported_Uncorrect changed from 93 to 91
smartd[1636]: Device: /dev/disk/by-id/ata-WDC_WD2500BEKT-60A25T1_WD-WX41A90E5928 [SAT], ATA error count increased from 7 to 9
Mamy tam informację Unrecovered read error - auto reallocate failed (tę samą, którą zdekodował
nam sg_decode_sense ) . Czyli prawdopodobnie na tym bloku rezyduje jakiś plik, bo automatyczna
realokacja się nie powiodła. Przynajmniej wiemy, że wszystkie wyliczenia wyżej zostały
przeprowadzone prawidłowo. Jeśli ten sektor by się dał odczytać bez problemu, to prawdopodobnie coś
źle policzyliśmy.
Realokowanie błędnego bloku
By realokować ten uszkodzony sektor musimy go zapisać. Warto zatem ustalić, który plik trzeba
będzie skasować, bo nie będzie się on już nadawał do odzyskania. Odpalamy zatem debugfs i
wskazujemy w nim ten blok, który próbowaliśmy odczytać w dd :
# debugfs
debugfs 1.45.0 (6-Mar-2019)
debugfs: open /dev/mapper/wd_black_label-root
debugfs: testb 233723
Block 233723 not in use
To ciekawe, niby automatyczna realokacja badblock'u się nie powiodła ale ten blok nie jest wykorzystany przez żaden plik. Do tej pory myślałem, że blok może zostać automatycznie realokowany jedynie w sytuacji, w której żaden i-node (i-węzeł) się do niego nie odwołuje. Wygląda jednak na to, że puste bloki też mogą mieć problemy z automatyczną realokacją.
Spróbujmy zapisać ten blok przy pomocy dd :
# dd if=/dev/zero of=/dev/mapper/wd_black_label-root count=1 bs=4096 seek=233723
1+0 records in
1+0 records out
4096 bytes (4.1 kB, 4.0 KiB) copied, 0.000132102 s, 31.0 MB/s
Jak widać, zapis bloku dokonał się bez większego problemu. Może jednak zapisaliśmy nie ten blok, który powinniśmy? Spróbujmy ponowić odczyt bloku, który wcześniej wyrzucił nam sporo błędów (chodzi o użycie tego samego polecenia co wcześniej):
# dd if=/dev/mapper/wd_black_label-root of=block233723 bs=4096 count=1 skip=233723
1+0 records in
1+0 records out
4096 bytes (4.1 kB, 4.0 KiB) copied, 0.00075293 s, 5.4 MB/s
No i proszę, uszkodzony sektor się odblokował. A jak prezentuje się wyjście hdparm ?
# time hdparm --read-sector 6203355 /dev/sda
/dev/sda:
reading sector 6203355: succeeded
6cf9 cd2a 7d6e 84c9 6685 bc59 62a5 2192
abd0 ca00 c518 c183 578b 66b6 8115 5b89
75c8 5381 7178 1702 358f 605d ebc6 6075
4f66 b633 7d84 07e4 1ca6 33f1 d1fb 126f
86b6 9642 244b f5b2 2709 4060 5954 8635
bd50 fa22 3a0e 2023 8459 e791 822b 416f
bfb9 0912 1ea2 7c34 9ba9 732c 3e7b ddfb
0c5e f190 2a25 991a 5f24 a402 0cfe 1d9f
a458 6815 45a4 ac90 9246 b081 8ee2 ba72
1383 7f9c 5824 3532 0095 bea0 271f b67b
1a0c a281 a7bf b4aa 7b58 0533 81e0 b219
73f3 b228 77b2 1bc7 ec61 dce2 df62 2b49
addf 216a fd10 a38c e090 1304 ef44 6afc
abc4 2d05 e36b 2f29 080b a5df 6735 bb2f
28d5 1fde 40d3 0010 45f1 a21d a311 6409
75f3 7f76 eecd 5c71 2687 b0fd 925e 8aa5
7e7e 9e99 29e2 1ecd 5cff badc 78c2 8e83
b610 179d 770c 58f8 a012 547c b6b9 5ef3
8145 ef62 36cb 5900 4c24 48a6 0c62 98fe
5381 3775 83ff 3483 6b27 a856 e875 68c5
8832 f0ca 576a add5 fc9b 9813 9db7 907b
646e 715c 2b9e 5098 c83e 65c2 d1db d734
f988 3fae dfec b465 fbcc 7235 cafa f4c5
211d 34f8 e356 11a9 cf0e 03ec ea05 a47f
7fc6 a98f 6a7c 0a15 7122 cc9c 152f 2840
2317 a76a 3dad 8888 8d47 edb2 541e 500a
ec0d e2e8 8ba9 cd71 270f bc9b aec6 ae78
e219 d719 009b 176f 960b f052 9063 9658
8e6b 739a e9c3 fd5f b51a 043e 902c 3e3b
2cc3 92ac fb4d 0e7f 81d8 c49b 51d1 41f9
ef4e c4b4 d9ca 84f2 b70b c391 1d3b 7e34
c442 c3d2 2078 1cc1 0ac3 260a b900 41f8
0.00s user 0.01s system 59% cpu 0.009 total
Czas dostępu jest niski, no i nie ma również samych 0000 , tak jak to było wcześniej.
Pełny skan S.M.A.R.T
Wypadałoby teraz przeskanować całą powierzchnię dysku i rzucić okiem na raport S.M.A.R.T. W tym przypadku skanowanie zakończyło się już powodzeniem:
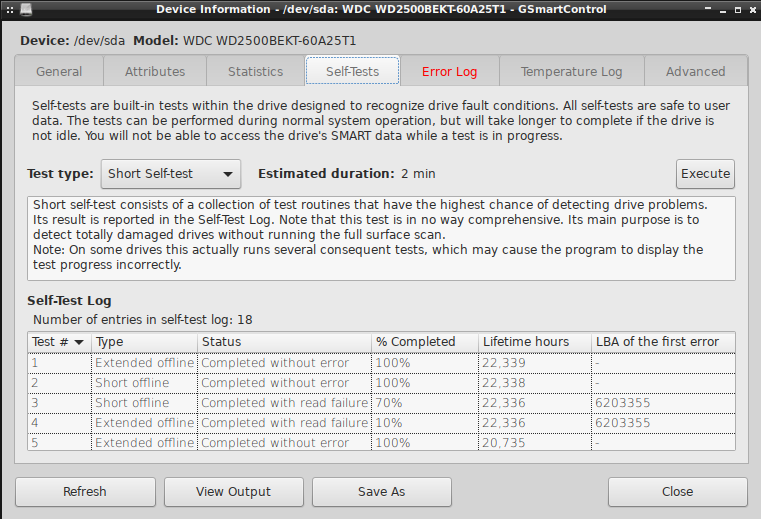
A raport pokazuje, że sektor udało się uratować:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
...
5 Reallocated_Sector_Ct PO--CK 200 200 140 - 0
...
196 Reallocated_Event_Count -O--CK 200 200 000 - 0
197 Current_Pending_Sector -O--CK 200 200 000 - 0
198 Offline_Uncorrectable ----CK 100 253 000 - 0
Więcej informacji na temat próby odzyskania uszkodzonych sektorów można znaleźć tutaj.