Kształtowanie ruchu sieciowego (Traffic Control)
Spis treści
Każdy z nas chciałby, aby jego sieć działała możliwie szybko i bezproblemowo. W przypadku, gdy łącze nie jest zbytnio obciążone, a my jesteśmy jedynym użytkownikiem internetu, to nie doświadczymy raczej żadnych problemów z połączeniem. Rzecz w tym, że im więcej użytkowników ma nasza sieć, tym większe prawdopodobieństwo, że zostanie ona przeciążona, tj. będziemy chcieli przesyłać więcej danych niż sieć jest w stanie obsłużyć. W ten sposób zaczną pojawiać się kolejki pakietów na interfejsach, których obsługa zajmuje trochę czasu. Rosą zatem opóźnienia, które są bardzo odczuwalne w momencie, gdy ktoś lubi sobie pograć w różnego rodzaju gry online. Innym problemem może być sieć P2P, gdzie pojedynczy host z naszej sieci może nawiązywać dziesiątki czy nawet setki połączeń i tym samym zapychać łącze nie dając szansy innym użytkownikom na komfortowe korzystanie z internetu. W obu przypadkach może nam pomóc kształtowanie ruchu sieciowego (Traffic Control), która jest w stanie nadać pakietom odpowiedni priorytet, tak by część z nich nie musiała czekać zbyt długo w kolejce. W tym wpisie przyjrzymy się bliżej temu mechanizmowi.
Problematyczna sieć Torrent
Każdy chyba wie, że gdy odpalimy klienta sieci BitTorrent, np. Qbittorrent, to pingi mają w zwyczaju strasznie skakać i utrzymywać się w przedziale 300-1000 ms. W skrajnych przypadkach, czas można liczyć nawet w sekundach. Dodatkowo, jeśli pobieramy (lub wysyłamy) kilka plików jednocześnie, to transfer rozkłada się mniej więcej po równo. W taki sposób dysponując łączem 10 mbit/s, przy założeniu, że pobieramy tylko dwa pliki, transfer rozłoży się po 5 mbit/s na każdy z nich. Jeśli byśmy do tego zaczęli coś pobierać w sieci P2P, to jest wielce prawdopodobne, że klient Torrent'a zje nam całe pasmo i te dwa pliki dostaną jedynie niewielką jego część.
By radzić sobie z tą niedogodnością płynącą z korzystania z sieci Torrent, opracowano protokół UTP. Niemniej jednak, u mnie coś to nie bardzo chce działać i pingi są bardzo wysokie. Innym wyjściem może być skorzystanie z harmonogramu zadań, który jest oferowany przez chyba większość klientów Torrent'a. Możemy zatem ustawić sobie ograniczenie transferu w określonych godzinach, a w pozostałych klient może działać bez przeszkód, np. w nocy. Ja korzystałem z tego typu rozwiązania przez pewien czas ale ciągle musiałem te godziny przestawiać. Ostatecznie zrezygnowałem z tej opcji, a przełączanie między tymi dwoma stanami obywało się manualnie.
Kontrola ruchu sieciowego w takim przypadku umożliwi nam dynamiczny przydział łącza w zależności od obciążenia sieci. Konfiguracja możne być prosta lub też bardzo zaawansowana, w zależności od tego co tak na dobrą sprawę chcemy osiągnąć. Największe problemy stwarza ruch przychodzący i jeśli chcemy go również kształtować, to będziemy musieli się trochę napracować. W przypadku, gdy w grę wchodzi jedynie kształtowanie ruchu wychodzącego, to nie ma z tym większych problemów.
Podstawowym narzędziem jakie będziemy wykorzystywać w swojej pracy przy kształtowaniu ruchu
sieciowego to tc (dostępne w pakiecie iproute2 ). To za jego pomocą wyznaczymy kolejki na
interfejsach sieciowych, do których będą napływać pakiety. To nim również będą ustawione
gwarantowane limity łącza, oraz jak dużo pasma może zapożyczyć sobie dana kolejka. Jednak samo
stworzenie kolejek nic nam nie da, pakiety trzeba jakoś do nich przekierować i tu możemy skorzystać
z filtra oferowanego przez tc , oznaczać pakiety za pomocą
firewall'a lub też zaciągnąć do
tego celu cgroups. Należy pamiętać przy tym, że cgroups może oznaczać tylko (chyba) pakiety
wychodzące i nie da rady go użyć na ruchu skierowanym do naszej maszyny.
Kształtowanie ruchu wychodzącego
Do kształtowania ruchu wychodzącego możemy wykorzystać iptables z celami -j MARK oraz -j CLASSIFY . Mamy też możliwość skorzystania z cgroups, oraz z tc filter . Nie będę tutaj opisywał
celu -j MARK , bo to już zostało zrobione przy okazji zabawy z interfejsami IMQ i reguły tam
zastosowane nie różnią się zbytnio od tych, które by zostały użyte w tym przypadku. Jedyne co, to
trzeba by było pozmieniać interfejsy. W każdym razie, gdy w grę wchodzi jedynie kształtowanie ruchu
wychodzącego, to nie ma sensu sobie zawracać głowy celem -j MARK .
Target -j CLASSIFY
Cel -j CLASSIFY daje nam możliwość przekierowania ruchu do odpowiednich kolejek bez potrzeby
zaprzęgania do tego tc filter . Po tym jak reguła zostanie dopasowana, pakiet trafia do
odpowiedniej kolejki. Poniżej mamy kilka linijek, które mają na celu utworzenie odpowiednich kolejek
przy pomocy narzędzia tc :
tc qdisc del dev bond0 root 2>&1
tc qdisc add dev bond0 root handle 1: htb default 400 r2q 10
tc class add dev bond0 parent 1:0 classid 1:1 htb rate 1000mbit ceil 1000mbit quantum 60000
tc class add dev bond0 parent 1:1 classid 1:10 htb rate 980kbit ceil 980kbit
tc class add dev bond0 parent 1:10 classid 1:200 htb rate 480kbit ceil 980kbit prio 0
tc class add dev bond0 parent 1:10 classid 1:300 htb rate 200kbit ceil 980kbit prio 2
tc class add dev bond0 parent 1:10 classid 1:400 htb rate 150kbit ceil 980kbit prio 4
tc class add dev bond0 parent 1:10 classid 1:500 htb rate 150kbit ceil 980kbit prio 5
tc class add dev bond0 parent 1:1 classid 1:20 htb rate 999mbit ceil 999mbit quantum 60000
tc class add dev bond0 parent 1:20 classid 1:1000 htb rate 99mbit ceil 999mbit prio 1 quantum 60000
Mając kolejki, możemy przejść do przekierowania pakietów przy pomocy odpowiednich reguł iptables :
$ipt -N qos_egress
$ipt -A POSTROUTING -o bond0 -j qos_egress
$ipt -A qos_egress -s 192.168.0.0/16 -d 192.168.0.0/16 -j CLASSIFY --set-class 1:1000
$ipt -A qos_egress -s 192.168.0.0/16 -d 192.168.0.0/16 -j ACCEPT
$ipt -A qos_egress -m owner --gid-owner p2p -j CLASSIFY --set-class 1:500
$ipt -A qos_egress -m owner --gid-owner p2p -j ACCEPT
$ipt -A qos_egress -m owner --gid-owner morfik -j CLASSIFY --set-class 1:200
$ipt -A qos_egress -m owner --gid-owner morfik -j ACCEPT
$ipt -A qos_egress -m owner --gid-owner root -j CLASSIFY --set-class 1:300
$ipt -A qos_egress -m owner --gid-owner root -j ACCEPT
$ipt -A qos_egress -s 192.168.10.0/24 -j CLASSIFY --set-class 1:400
$ipt -A qos_egress -s 192.168.10.0/24 -j ACCEPT
To co zasługuje na uwagę, to --set-class . Wartość tego parametru musi pasować do wartości
classid w tc , który ustawiliśmy wyżej. Poniżej przykład działania:
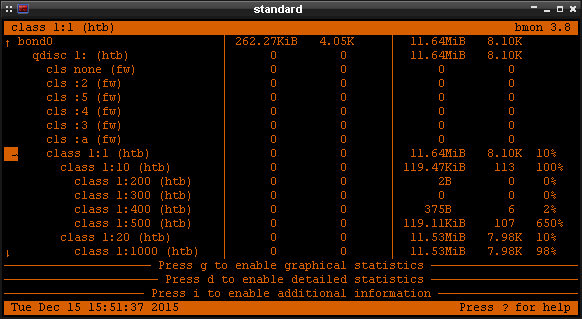
Cgroups
Systemd robi przyzwoity użytek z cgroups. Cgroups również możemy wykorzystać do kierowania ruchu do odpowiednich kolejek. O samej konfiguracji cgroups pisałem nieco w tym wpisie i sporo informacji tam zawartych przyda się nam tutaj.
Kształtowanie ruchu w systemd
Każda usługa systemowa, która posiada plik .service może być skonfigurowana pod kątem kontroli jej
pakietów. Taka funkcjonalność została dodana do systemd w wersji 227 . Jeśli posiadamy jedną z
nowszych wersji tego init'u, to zarządzanie pakietami usług systemowych jest banalnie proste.
Wystarczy dodać do pliku usługi parametr NetClass , przykładowo:
[Service]
...
NetClass=500
Zgodnie z
dokumentacją,
systemd powinien odpowiednio dostosować plik net_cls.classid w strukturze cgroups ale z jakichś
powodów tak się nie dzieje i ten mechanizm na dzień dzisiejszy nie działa tak jak
powinien.
Kształtowanie ruchu bez systemd
W przypadku, gdy nie korzystamy z systemd lub też chcemy nadawać priorytety pakietom, które pochodzą
od innych usług niż te systemowe, to musimy skorzystać z dodatkowych narzędzi zawartych w pakiecie
cgroup-tools . By kontrolować pakiety jakieś aplikacji, musimy dopisać odpowiednią linijkę z
uwzględnieniem kontrolera net_cls w pliku /etc/cgrules.conf , przykładowo:
*:firefox cpu,net_cls users/firefox/
*:firefox* cpu,net_cls users/firefox/
*:qbittorrent cpu,net_cls users/qbittorrent/
*:qbittorrent* cpu,net_cls users/qbittorrent/
Powyższe wpisy utworzą odpowiednią strukturę katalogów w /sys/fs/cgroups/ . Musimy jeszcze
odpowiednio uzupełnić plik net_cls.classid , który zawierać będzie numer grupy, do której te
pakiety będą trafiać. Dodajemy zatem do pliku /etc/cgconfig.conf bloki kodu podobne do tego
poniżej:
group users/firefox {
perm {
task {
uid = root;
gid = root;
dperm = 775;
fperm = 664;
}
admin {
uid = root;
gid = root;
dperm = 775;
fperm = 664;
}
}
cpu {
cpu.shares = "512";
}
net_cls {
net_cls.classid = 0x00010200;
}
}
Ten numerek 0x00010200 składa się tak naprawdę z dwóch liczb w zapisie HEX: 0001 oraz 0200. Liczba
0001 odpowiada za 1, a 0200 za 200 (tak wiem, dziwne). W ten sposób otrzymujemy grupę w postaci
1:200 . Pamiętajmy też, by po edycji powyższych plików zresetować usługi cgconfig.service oraz
cgrulesengd.service .
Pozostało nam jeszcze stworzenie odpowiednich kolejek w tc :
tc qdisc add dev bond0 root handle 1: htb default 400 r2q 10
tc class add dev bond0 parent 1:0 classid 1:1 htb rate 1000mbit ceil 1000mbit quantum 60000
tc class add dev bond0 parent 1:1 classid 1:10 htb rate 980kbit ceil 980kbit
tc class add dev bond0 parent 1:10 classid 1:200 htb rate 480kbit ceil 980kbit prio 0
tc class add dev bond0 parent 1:10 classid 1:300 htb rate 200kbit ceil 980kbit prio 2
tc class add dev bond0 parent 1:10 classid 1:400 htb rate 150kbit ceil 980kbit prio 4
tc class add dev bond0 parent 1:10 classid 1:500 htb rate 150kbit ceil 980kbit prio 5
tc class add dev bond0 parent 1:1 classid 1:20 htb rate 999mbit ceil 999mbit quantum 60000
tc class add dev bond0 parent 1:20 classid 1:1000 htb rate 99mbit ceil 999mbit prio 1 quantum 60000
Teraz już tylko wystarczy przekierować do nich pakiety via tc filter :
tc filter add dev bond0 protocol ip parent 1:0 prio 10 handle 500 cgroup
tc filter add dev bond0 protocol ip parent 1:0 prio 5 handle 200 cgroup
tc filter add dev bond0 protocol ip parent 1:0 prio 90 handle 300 cgroup
tc filter add dev bond0 protocol ip parent 1:0 prio 20 handle 400 cgroup
tc filter add dev bond0 protocol ip parent 1:0 prio 10 handle 500 cgroup
tc filter add dev bond0 protocol ip parent 1:0 prio 100 handle 1000 cgroup
Nie potrzebujemy żadnych wpisów w iptables , bo wszystko jest zarządzane przez cgroups w
połączeniu z tc . Warto nadmienić, że wartość w handle 200 cgroup ma odpowiadać tej określonej
w pliku /etc/cgconfig.conf (0x00010200). Poniżej zaś test:
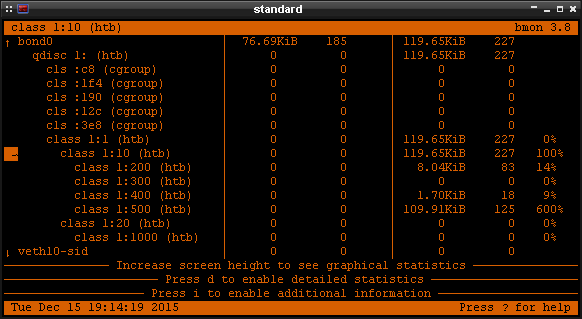
Interfejsy IMQ
Dokładny opis na temat tego jak aktywować interfejsy IMQ oraz jak przy ich pomocy ograniczyć i kształtować ruch zostały opisane w osobnym artykule. Ten mechanizm nie jest już wspierany przez kernel i iptables i bez rekompilacji tych pakietów niestety się nie obejdzie. Niemniej jednak, niewątpliwą zaletą interfejsów IMQ jest możliwość bezproblemowego kształtowania ruchu w obu kierunkach.
Interfejsy IFB
Jeśli nie odpowiada nam za bardzo zabawa z kompilacją kernela i iptables, a przy tym chcemy kontrolować pakiety w obu kierunkach, to możemy skorzystać z natywnego rozwiązania oferowanego przez kernel, czyli interfejsów IFB.
Quantum oraz r2q
W powyższych przykładach, kolejki, które ustawiliśmy sobie, maja określone dwa dość niejasne
parametry: quantum oraz r2q . Znalazłem ciekawe wyjaśnienie na temat ich działania pod tym
linkiem i postaram się pokrótce opisać jak korzystać z tych
opcji.
Przede wszystkim zarówno quantum jak i r2q mają jedynie znacznie w przypadku, gdy pasmo, które
zostało rozdysponowane pomiędzy szereg kolejek, jest utylizowane w pełni. Dla uproszczenia
przyjmijmy, że mamy trzy kolejki. Do dwóch z nich trafiają pakiety, a trzecia leży odłogiem. W obu
tych kolejkach, do których napływają pakiety, został osiągnięty limit ( rate ) i obie te kolejki
są w stanie korzystać z pasma tej kolejki, która nie jest obciążona. W jaki sposób zostaną
rozdysponowane jej zasoby? Właśnie ta kwestia jest rozstrzygana przy pomocy parametrów quantum jak
i r2q , które każda z kolejek ma ustawione, nawet w przypadku, gdy nie określamy ich ręcznie w
konfiguracji.
Standardowo quantum jest wyliczane przez rate/r2q . Z kolei r2q domyślnie wynosi 10 ale ta
wartość może zostać zmieniona. Natomiast wartość parametru quantum powinna być większa niż MTU i
mniejsza niż 60000.
Na necie spotkałem się z dwiema wartościami, które mogą być ustawione jako minimum: 1500 oraz 1514. W różnych dokumentach jest to zdefiniowane inaczej i jedne nie uwzględniają nagłówka ethernet'owego, inne zaś go wliczają. Chodzi generalnie o to, aby kolejka była w stanie przesłać pełny pakiet podczas jednej tury (gdy dwie lub więcej kolejek rywalizuje o zasoby ponad swój limit). Górny limit (60000) zaś jest ustawiony na sztywno w samym qdisc, by zapobiec zduszeniu pozostałych kolejek oraz w celu minimalizowania opóźnień.
W przypadku złego dobrania wartości, w logu zostanie zanotowany komunikat podobny do tego poniżej:
kernel: HTB: quantum of class 10500 is small. Consider r2q change.
Te błędy nie wpływają na samą funkcjonalność kolejek, a jedynie na ich precyzję przy ograniczaniu ruchu.
Wracając do naszego przykładu. Jeśli te dwie kolejki będą mieć ustawioną taką samą wartość parametru
quantum , to niewykorzystane zasoby będą rozdzielone po równo. W przypadku, gdy jedna z kolejek
będzie miała dwukrotnie większy quantum niż ta druga, to przypadnie jej 2/3 zasobów.