Jak zmusić jeden proces do korzystania z VPN na linux (OpenVPN)
Spis treści
Parę dni temu na forum dug.net.pl pojawiło się zapytanie dotyczące skonfigurowania linux'a w
taki sposób, by ten umożliwił pojedynczemu procesowi w systemie (i tylko jemu) korzystanie z VPN,
podczas gdy wszystkie pozostałe aplikacje korzystają ze standardowego łącza internetowego naszego
ISP. Oczywiście to niekoniecznie musi być tylko jeden proces, bo to zagadnienie można rozciągnąć
też na większą grupę procesów jednego lub więcej użytkowników. By to zadanie zrealizować, trzeba
zdać sobie sprawę z faktu, że każdy proces w linux ma swojego właściciela, a ten właściciel
przynależy do co najmniej jednej grupy. Dzięki takiemu rozwiązaniu, każdy proces w systemie ma
przypisany m.in. identyfikator użytkownika (UID) oraz identyfikatory grup (GID), z którymi działa i
na podstawie których to linux przyznaje uprawienia dostępu do różnych części systemu, np. urządzeń
czy plików na dysku. W ten sposób możemy bardzo prosto ograniczyć dostęp do określonych zasobów
konkretnym użytkownikom (bardziej ich procesom). Problem się zaczyna w przypadku sieci, gdzie w
zasadzie dostęp do internetu ma domyślnie przyznany każdy proces. Naturalnie możemy skonfigurować
filtr pakietów i zezwolić tylko części aplikacji na dostęp do sieci ale w dalszym ciągu, gdy tylko
odpalimy VPN (w tym przypadku OpenVPN), to każdy proces mający prawo wysyłać pakiety sieciowe
będzie je przesyłał z automatu przez VPN, jak tylko to połączenie zostanie zestawione. Istnieje
jednak sposób, by nauczyć linux'a aby tylko procesy określonych użytkowników czy grup miały dostęp
do VPN i gdy to połączenie zostanie zerwane, to te procesy nie będą mogły korzystać ze
standardowego łącza internetowego. Trzeba jednak zaprzęgnąć do pracy iptables / nftables ,
tablice routingu oraz nieco inaczej skonfigurować klienta OpenVPN.
Konfiguracja OpenVPN
Nie będę tutaj opisywał jako takiej konfiguracji OpenVPN, bo to zostało zrobione w osobnym
artykule. Dlatego jeśli ktoś potrzebuje informacji na temat jak skonfigurować OpenVPN, to odsyłam
do podlinkowanego wpisu. Tutaj zakładam, że mamy już działające połączenie VPN i jesteśmy w stanie
bez większego problemu nawiązać łączność ze światem zewnętrznym przy jego pomocy. W tym przypadku
wykorzystywany będzie Proton VPN, którego konfiguracja znajduje się w pliku
/etc/openvpn/nl-free-02.protonvpn.com.udp1194.conf . Ten plik trzeba będzie poddać edycji (o tym
za moment).
W przypadku części serwerów OpenVPN (Proton VPN się do nich zalicza), cały ruch klienta po
zestawieniu połączenia jest wrzucany w tunel SSL/TLS i szyfrowany na linii klient-serwer. By ten
zabieg zrealizować, serwer przesyła do klienta żądanie push "redirect-gateway" , które ma na
celu przekonfigurować trasy u klienta w taki sposób, by znalazło się w jego tablicy routingu kilka
dodatkowych wpisów, m.in. 0.0.0.0/1 oraz 128.0.0.0/1 , które efektywnie nadpisują domyślną
trasę routingu bez potrzeby jej usuwania z tablicy.
Poniżej jest przykład tablicy routingu z mojego laptopa:
# ip route show
default via 192.168.1.1 dev bond0 metric 10
10.10.10.0/24 dev br-docker proto kernel scope link src 10.10.10.1 dead linkdown
192.168.1.0/24 dev bond0 proto kernel scope link src 192.168.1.150
192.168.122.0/24 dev virbr0 proto kernel scope link src 192.168.122.1 dead linkdown
Domyślna brama (wpis z default ) ma adres 192.168.1.1 i jest osiągalna przez interfejs bond0 .
Pod default kryje się adres 0.0.0.0/0 , który w zasadzie oznacza wszystkie adresy. Routing
działa na zasadzie najdłuższego prefiksu, czyli preferowane są bardziej specyficzne trasy. Zatem
cały ruch niepasujący do żadnej skonfigurowanej na tej maszynie sieci, tj 10.10.10.0/24 ,
192.168.1.0/24 oraz 192.168.122.0/24 , będzie przesyłany na adres 192.168.1.1 i tam już
odpowiednio przekierują pakiety, tak by np. trafiły pod adres 8.8.8.8 .
Jeśli teraz zestawimy połączenie VPN, to ta widoczna wyżej tablica routingu będzie się prezentować w poniższy sposób:
# ip route show
0.0.0.0/1 via 172.27.100.1 dev tun0
default via 192.168.1.1 dev bond0 metric 10
10.10.10.0/24 dev br-docker proto kernel scope link src 10.10.10.1 dead linkdown
128.0.0.0/1 via 172.27.100.1 dev tun0
172.27.100.0/22 dev tun0 proto kernel scope link src 172.27.100.19
192.168.1.0/24 dev bond0 proto kernel scope link src 192.168.1.150
192.168.122.0/24 dev virbr0 proto kernel scope link src 192.168.122.1 dead linkdown
198.252.153.226 via 192.168.1.1 dev bond0
Jak zostało wspomniane wcześniej, wpisy 0.0.0.0/1 oraz 128.0.0.0/1 mają za zadanie przekierować
cały ruch do bramy VPN. W zakres 0.0.0.0/1 łapią się wszystkie adresy, których pierwszy bit ma
wartość 0 , natomiast w zakres 128.0.0.0/1 łapią się adresy mające pierwszy bit ustawiony na
wartość 1 . Dla lepszego zrozumienia, poniżej jest rozpiska:
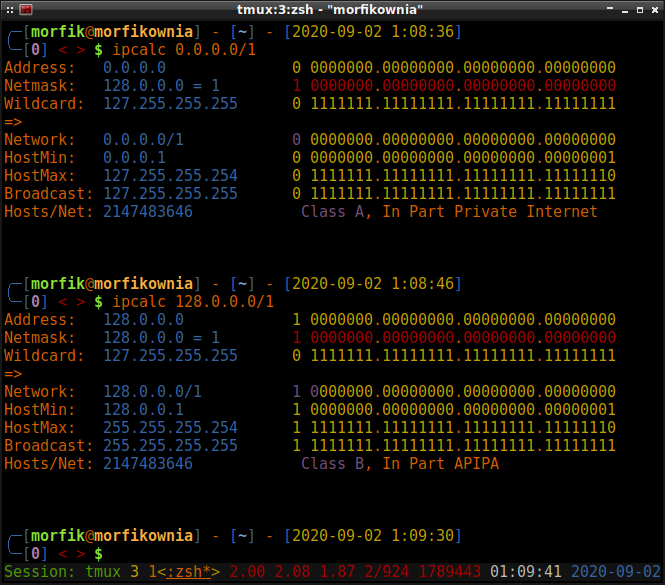
W ten sposób każda z tych dwóch tras jest bardziej specyficzna niż 0.0.0.0/0 , która również
łapie wszystkie adresy. Tym prostym zabiegiem nasza domyślna brama nie ma już żadnego wpływu na
routing pakietów. Każda z tych dwóch tras ma określony via 172.27.100.1 oraz dev tun0 , przez
co nową bramą domyślną staje się adres 172.27.100.1 osiągalny przez interfejs tun0 . Dalej w
tablicy routingu widzimy, że została także skonfigurowana trasa dla nowej sieci 172.27.100.0/22
(sieć VPN) oraz pojawił się wpis 198.252.153.226 , którego IP wskazuje na adres serwera VPN.
Chodzi tutaj o to, że pakiety po zaszyfrowaniu (odebrane z interfejsu tun0 ) muszą zostać
przesłane do serwera VPN. Nie mogą jednak lecieć kanałem VPN. Zatem wszystkie pakiety (te wrzucone
w tunel SSL/TLS) kierowane są na adres 198.252.153.226 . Dalej w tej trasie mamy via 192.168.1.1 dev bond0 , przez co pakiety kierowane na adres 198.252.153.226 będą przesyłane przez naszą
wcześniejszą bramę domyślną.
Parametr route-nopull
Po skonfigurowaniu tras routingu, wszystkie aplikacje sieciowe będą przesyłać ruch przez VPN.
Niemniej jednak, ta domyślna polityka przekonfigurowania tras routingu sprawia, że nie damy rady
rozdzielić procesów w taki sposób, by tylko określone z nich przesyłały pakiety przez VPN. Trzeba
zatem tych domyślnych tras routingu się pozbyć i do tego służy parametr route-nopull , który
trzeba dopisać w konfiguracji OpenVPN w pliku /etc/openvpn/nl-free-02.protonvpn.com.udp1194.conf :
route-nopull
Odpalmy teraz OpenVPN. Po rzuceniu okiem na tablicę routingu, możemy stwierdzić, że przypomina ona
tę podstawową tablicę sprzed zestawiania połączenia VPN. W zasadzie to została dodana jedynie trasa
dla sieci VPN (wpis z 172.27.100.0/22 ):
# ip route show
default via 192.168.1.1 dev bond0 metric 10
10.10.10.0/24 dev br-docker proto kernel scope link src 10.10.10.1 dead linkdown
172.27.100.0/22 dev tun0 proto kernel scope link src 172.27.100.18
192.168.1.0/24 dev bond0 proto kernel scope link src 192.168.1.150
192.168.122.0/24 dev virbr0 proto kernel scope link src 192.168.122.1 dead linkdown
W taki sposób po zestawieniu połączenia VPN, nic u nas w systemie się jeszcze nie dzieje, tj. pakiety w dalszym ciągu wędrują przez domyślny gateway routera domowego albo naszego ISP. Niemniej jednak, teraz te trasy routingu musimy sobie sami skonfigurować, by aplikacje miały w ogóle jakąkolwiek możliwość przesyłania pakietów przez VPN.
Konfiguracja tras routingu dla OpenVPN
Pora przejść do ręcznej konfiguracji tras routingu. Przede wszystkim, musimy określić w tym miejscu jaki proces albo bardziej użytkownik lub grupa, z którymi uruchomiony jest dany proces, ma mieć dostęp do VPN. W zasadzie to nie ma znaczenia czy zdecydujemy się na grupę czy użytkownika, bo konfiguracja tras będzie przebiegać tak samo, no może za wyjątkiem drobnych różnic w numerach czy nazwach parametrów. Każde z tych dwóch rozwiązań ma swoje wady i zalety. Jeśli korzystamy z grup, to bez problemu nasz zwykły użytkownik, na którym operujemy na co dzień, będzie w stanie bezpośrednio wywoływać procesy, co może uprościć operowanie na graficznych aplikacjach. Jeśli zaś chcemy określić użytkownika, który będzie korzystać z VPN, to trzeba będzie się na niego logować. Tak czy inaczej, zarówno użytkownik jak i grupa posiada swój numer identyfikacyjny i to nim będziemy się posługiwać w dalszej części tego artykułu.
Na początek stwórzmy nową tablicę routingu i nazwijmy ją vpn . By dodać nową tablicę routingu,
trzeba edytować plik /etc/iproute2/rt_tables i umieścić w niej poniższy wpis:
200 vpn
Numerek może być dowolny, podobnie jak i nazwa tablicy. Nazwy są bardziej dla ludzi, maszyny wolną numerki i ta para to właśnie takie mapowanie nazw na numery. Do obu tych wartości będzie można się odwoływać w poleceniach.
Następnie dodajemy nowy wpis do tablicy vpn , który ma za zadanie skonfigurować trasę domyślną
dla interfejsu tun0 :
# ip route add default dev tun0 table vpn
Problem z tą trasą jest taki, że gdy interfejs tun0 zniknie (np. rozłączymy VPN), to ta trasa
również zostanie usunięta, a pakiety, które miałyby iść przez VPN, będą teraz lecieć przez bramę
domyślną naszego ISP. Taka sytuacja niekoniecznie jest pożądana, zwłaszcza w przypadku, gdy chcemy
by określony proces miał dostęp do sieci jedynie przez VPN. W takim przypadku trzeba jeszcze do
tablicy vpn dodać trasę typu blackhole, tak by wszystkie pakiety przekierowane do VPN były
cicho niszczone bez przekazywania ich dalej w przypadku braku połączenia VPN:
# ip route append blackhole default table vpn
W ten sposób upewnimy się, że proces korzystający z VPN nie będzie miał możliwości bezpośredniego kontaktu z siecią:
# ip route show table vpn
default dev tun0 scope link
blackhole default
Cache routingu został usunięty z kernela dość dawno (od wersji v3.6), zatem nie musimy już wydawać tego poniższego polecenia:
# ip route flush cache
Mamy zatem domyślną trasę w tablicy vpn ale potrzebujemy jeszcze jakiejś reguły, która sprawi, że
ta trasa będzie w ogóle brana pod uwagę. Bez tej reguły, kernel przy routingu pakietów będzie
posługiwał się w zasadzie tablicą main , przez co połączenie VPN nie będzie używane:
# ip rule add fwmark 0x1111 priority 2002 table vpn
Za sprawą tej powyższej reguły, pakiety będą dopasowane na podstawie fwmark nakładanego przez
netfilter ( iptables / nftables). Wartość fwmark możemy określić z zakresu od 0x00000000 do
0xffffffff , zarówno dziesiętnie, jak i w HEX. Jeśli chcemy podać wartość w HEX, to używamy 0x .
Trzeba mieć na uwadze fakt, że niektóre aplikacje (np. conntrack ) przeliczają HEX'y na wartości
dziesiętne. W taki sposób 0x00001111 przyjmie wartość 4369 . Zatem lepiej uważać jaką wartość w
fwmark podajemy. Priorytet określony w priority nie ma znaczenia, gdy w grę wchodzi tylko jedna
reguła. Niemniej jednak, każda reguła musi mieć określony priorytet i ten priorytet musi być inny
dla każdej z nich. Warto tutaj zaznaczyć, że im wyższa wartość parametru priority , tym niższy
priorytet. Z kolei table vpn nakazuje kernelowi sprawdzenie tablicy vpn ilekroć tylko mark w
pakietach zostanie dopasowany.
Po wydaniu tego powyższego polecenia, reguły routingu powinny wyglądać mniej więcej tak:
# ip rule show
0: from all lookup local
2002: from all fwmark 0x1111 lookup vpn
32766: from all lookup main
32767: from all lookup default
Mamy tutaj cztery reguły -- jedna nasza, a trzy pozostałe są domyślnie skonfigurowane na każdym linux'ie.
Konfiguracja iptables/nftables
Została nam już ostatnia rzecz do skonfigurowania, tj. filtr pakietów iptables lub nftables . W
tym przypadku będziemy korzystać z nftables ale bez problemu te reguły można przepisać i na
iptables .
Pisząc regułę routingu, określiliśmy w niej fwmark o wartości 0x1111 . Ten mark może zostać
nałożony przez filtr pakietów w tablicy mangle w łańcuchu OUTPUT . Stwórzmy zatem dodatkowy
łańcuch w tej tablicy i przekierujmy do niego ruch w oparciu o informacje o pakiecie, tj UID
( skuid ) lub GID ( skgid ):
nft create chain inet mangle force-vpn
nft add rule inet mangle OUTPUT meta skuid 1001 counter jump force-vpn
Każdy pakiet sieciowy, który zostanie stworzony przez aplikacje uruchomione przez użytkownika
mającego ID 1001 zostanie dopasowany do tej drugiej reguły i przesłany do łańcucha force-vpn .
W tym łańcuchu dodajemy kolejną regułę, której zadaniem jest oznaczenie pakietów markiem 0x1111 :
nft add rule inet mangle force-vpn meta skgid 1001 meta mark set 0x1111 counter
W tej chwili każdy pakiet sieciowy użytkownika z ID 1001 będzie oznaczany w nftables , a reguła
routingu sprawi, że pakiety zostaną skierowane do kanału VPN. Warto tutaj zaznaczyć, że takie
oznaczanie pakietów dotyczy każdego pakietu z osobna, tj. każdy pakiet tego użytkownika z ID 1001
będzie dopasowany do tej reguły, co niekoniecznie jest optymalnym rozwiązaniem jeśli chodzi o
wydajność. Naturalnie taki mechanizm oznaczania pakietów nie sprawi, że prędkość połączenia
sieciowego ucierpi ale to rozwiązanie oznaczania pakietów można poprawić przez oznaczanie całego
połączenia zamiast pojedynczych pakietów. Niemniej jednak, jest to ździebko skomplikowane i nie
będę tej kwestii tutaj poruszał. Ci, których interesuje to zagadnienie, mogą rzucić okiem na
artykuł o oznaczaniu połączeń przy pomocy targetu MARK w iptables. Poniżej jest tylko
przykładowa konfiguracja dla nftables (do umieszczenia, np. w skrypcie firewall'a ):
table inet mangle {
chain PREROUTING {
type filter hook prerouting priority -150; policy accept;
iifname != "lo" jump marking
}
chain OUTPUT {
type route hook output priority -150; policy accept;
oifname != "lo" jump marking
}
chain marking {
counter meta mark set ct mark & 0x0000ffff
meta mark & 0x0000ffff != 0x00000000 counter return
meta skgid 1001 meta mark & 0x0000ffff == 0x00000000 meta mark set 0x00001111 counter
counter ct mark set meta mark & 0x0000ffff
}
}
Oznaczenie pakietów i przekierowanie ich pod określony adres mamy z głowy. Problem jednak w tym, że
te pakiety nie będą chciały opuścić naszej maszyny, bo nie jest jeszcze realizowany NAT. Musimy
zatem dodać parę reguł w nftables dla tablicy NAT.
Podobnie jak poprzednio, tworzymy osobny łańcuch i przekierowujemy ruch do niego, tym razem w
oparciu o interfejs wychodzący, który ma wskazywać na interfejs VPN (w tym przypadku tun0 ):
nft create chain inet nat force-vpn
nft add rule inet nat POSTROUTING meta oifname tun0 counter jump force-vpn
W łańcuchu force-vpn dodajemy teraz regułę, która ma przepisać źródło pakietów na adres jaki
klient OpenVPN otrzymał z serwera. W tym przypadku serwer VPN dynamicznie przydziela klientom
adresy IP i nigdy nie wiadomo na jaki się trafi, dlatego lepiej skorzystać z maskarady:
nft add rule inet nat force-vpn meta oifname tun0 counter masquerade
Jeśli jednak mamy przydzielony stały adres IP, to można również dać SNAT zamiast maskarady, choć nie jest to wymagane:
nft add rule inet nat force-vpn meta oifname tun0 counter snat 172.27.100.18
Test VPN dla określonego użytkownika
Te powyżej przeprowadzone kroki to w zasadzie wszystko co jest nam potrzebne do skonfigurowania VPN
dla pojedynczego procesu czy użytkownika/grupy, przy założeniu, że mieliśmy wcześniej działający
VPN. Wystarczy się teraz zalogować na tego określonego user'a lub też odpalić jakiś proces z
konkretną grupą i przetestować np. przy pomocy ping czy opóźnienia do tego samego serwera ulegają
zmianie w zależności czy ping leci przez VPN czy bezpośrednio do docelowego hosta. Jak widać na
przykładzie zobrazowanym poniżej, różnica w ping'u jest i to dość znaczna. Zawsze można też dla
potwierdzenia odpytać o nasz adres IP jakiś zewnętrzny serwis, by sprawdzić czy faktycznie te
adresy IP widziane przez serwery WWW się różnią:
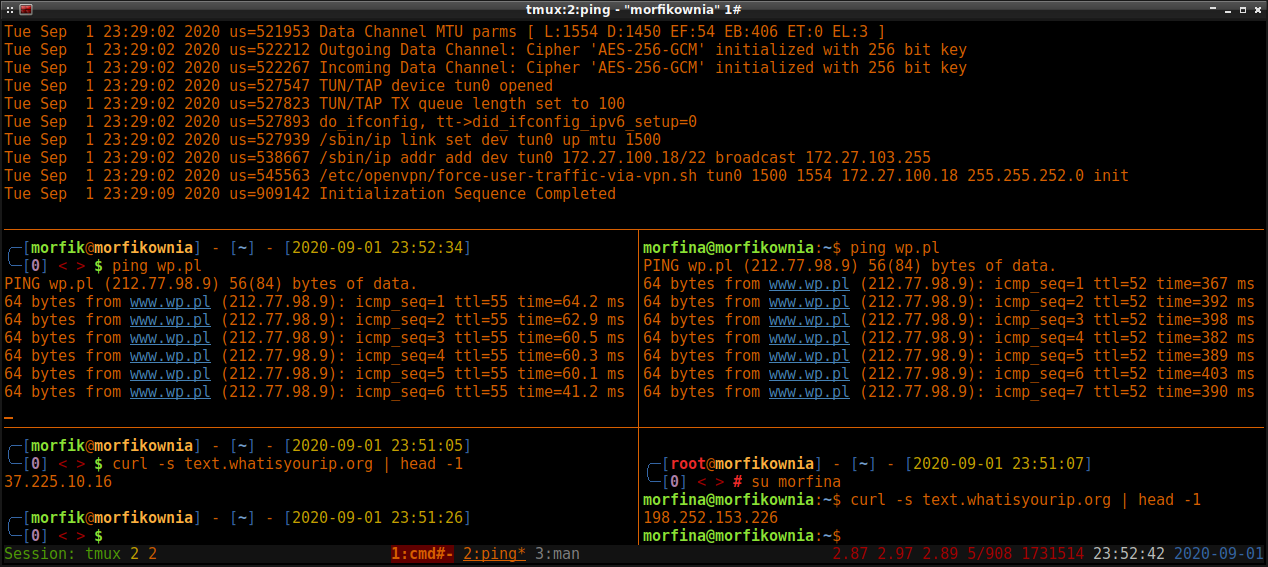
Podczas testowania połączenia można także podejrzeć tablicę conntrack'a i sprawdzić czy przy wpisie od nawiązanego połączenia widnieje ustawiony przez nas mark:
# conntrack -L | grep 212.77.98.9
icmp 1 29 src=192.168.1.150 dst=212.77.98.9 type=8 code=0 id=35 src=212.77.98.9 \
dst=172.27.100.20 type=0 code=0 id=35 mark=4369 use=1
Jak widać, mamy tutaj mark=4369 , czyli 0x1111 zapisany w formie dziesiętnej. Zatem to
połączenie zostało poprawnie oznaczone przez nftables i wszystkie pakiety tego połączenia lecą
przez VPN.
Problemy związane z procesowym VPN
Przedstawione w niniejszym artykule rozwiązanie nie jest pozbawione wad. Przede wszystkim, te
poczynione zmiany w konfiguracji systemu nie są permanentne. Z każdym restartem maszyny trzeba by
te wszystkie kroki przeprowadzać ponownie. Podobnie sprawa wygląda w przypadku restartu połączenia
VPN czy też jego rozłączenia w skutek różnych przyczyn. Chodzi generalnie o to, że gdy połączenie
VPN zniknie, to trasy przypisane do interfejsu VPN ( tun0 ) również znikną, w efekcie czego
trzeba by je dodać jeszcze raz. Można jednak ten stan rzeczy dość łatwo poprawić pisząc prosty
skrypt shell'owy dla OpenVPN. Poniżej jest przykład takiego skryptu, który zapisujemy w
/etc/openvpn/force-user-traffic-via-vpn.sh :
#!/bin/sh
id="1001"
mark="0x1111"
route_table="vpn"
rule_prio="2002"
[ "$script_type" ] || exit 0
[ "$dev" ] || exit 0
case "$script_type" in
up)
if ! grep ${route_table} /etc/iproute2/rt_tables > /dev/null
then
echo "200 ${route_table}" >> /etc/iproute2/rt_tables
fi
if ip route show table ${route_table} | grep blackhole > /dev/null
then
ip route del default table ${route_table}
fi
ip route add default dev ${dev} table ${route_table}
ip route append blackhole default table ${route_table}
if ! ip rule show | grep ${mark} > /dev/null
then
ip rule add fwmark ${mark} priority ${rule_prio} table ${route_table}
fi
if ! nft -a list table inet nat | grep force-vpn > /dev/null
then
nft create chain inet nat force-vpn
nft add rule inet nat POSTROUTING meta oifname ${dev} counter jump force-vpn
nft add rule inet nat force-vpn meta oifname ${dev} counter masquerade
fi
if ! nft -a list table inet mangle | grep force-vpn > /dev/null
then
nft create chain inet mangle force-vpn
nft add rule inet mangle OUTPUT meta skuid ${id} counter jump force-vpn
nft add rule inet mangle force-vpn meta skuid ${id} meta mark set ${mark} counter
fi
;;
down)
;;
esac
W zasadzie wszystkie kroki, które przeprowadziliśmy wcześniej, zostały zebrane w tym skrypcie. Ma
on, co prawda, akcje up oraz down ale w down nie ma żadnych poleceń. Chodzi o to, by nie cofać
zmian w konfiguracji systemu, tj. tych wprowadzonych podczas zestawiania połączenia VPN po raz
pierwszy. W ten sposób, gdy nastąpi zerwanie połączenia VPN, to proces korzystający z niego nie
będzie miał dostępu do sieć hosta i nie będzie w stanie przesłać żadnego pakietu przez sieć do
momentu aż to połączenie z VPN zostanie nawiązane ponownie.
By ten skrypt był wykonywany podczas zestawiania połączenia VPN, musimy jeszcze edytować konfigurację VPN i dodać do niej te poniższe wpisy:
script-security 2
up /etc/openvpn/force-user-traffic-via-vpn.sh
down /etc/openvpn/force-user-traffic-via-vpn.sh
I to w zasadzie cała robota -- kawałek skryptu w połączeniu z paroma dodatkowymi wpisami w konfiguracji połączenia VPN. Przy pomocy tego rozwiązania można bez większego problemu skonfigurować sobie dwa różne profile Firefox'a i ruch jednego z nich puścić tradycyjnie przez łącze naszego ISP, a ruch drugiego przez VPN, co powinno nieco poprawić naszą prywatność wtedy, gdy tego potrzebujemy bez dodatkowych zabiegów konfiguracyjnych i ciągłego przełączania się między VPN a zwykłym połączeniem internetowym.