Unikanie SYN/ICMP/UDP/PING flood w linux z nftables
Spis treści
Obecnie nftables cierpi dość mocno z powodu pewnych problemów związanych z wydajnością przy
aplikowaniu reguł zapory sieciowej. Niemniej jednak, w stosunku do iptables , nftables posiada
tablicę netdev , która jest w stanie nieco zyskać w oczach tych nieco bardziej wybrednych
użytkowników linux'a. Chodzi generalnie o fakt, że ta tablica jest umieszczona zaraz na początku
drogi pakietów, tuż po odebraniu ich z NIC (interfejsu karty sieciowej), a biorąc pod uwagę fakt,
że ruch sieciowy, który nigdy ma nie trafić do naszej maszyny, powinien być zrzucany jak
najwcześniej (by nie marnować zasobów procesora i pamięci), to ta tablica wydaje się być idealnym
miejscem by zablokować cały niepożądany ruch przychodzący. Przy wykorzystaniu iptables , takie
pakiety zrzuca się w tablicy raw . Jeśli zaś chodzi o nftables , to zrzucanie pakietów w
tablicy netdev jest ponad dwu lub nawet trzykrotnie bardziej wydajne (szybsze i mniej
zasobożerne). Można zatem dość dobrze poradzić sobie z wszelkiego rodzaju atakami DOS/DDOS, np.
ICMP/PING flood czy SYN flood. Zastanawiające może być natomiast ogarnięcie ataku UDP flood ale
przed tym rodzajem ataku linux również jest w stanie się bez problemu ochronić.
Gdzie dokładnie znajduje się tablica netdev
Poniżej znajduje się fotka (źródło) obrazująca przepływ pakietów sieciowych przechodzących przez linux'owy firewall:
{kind=link}
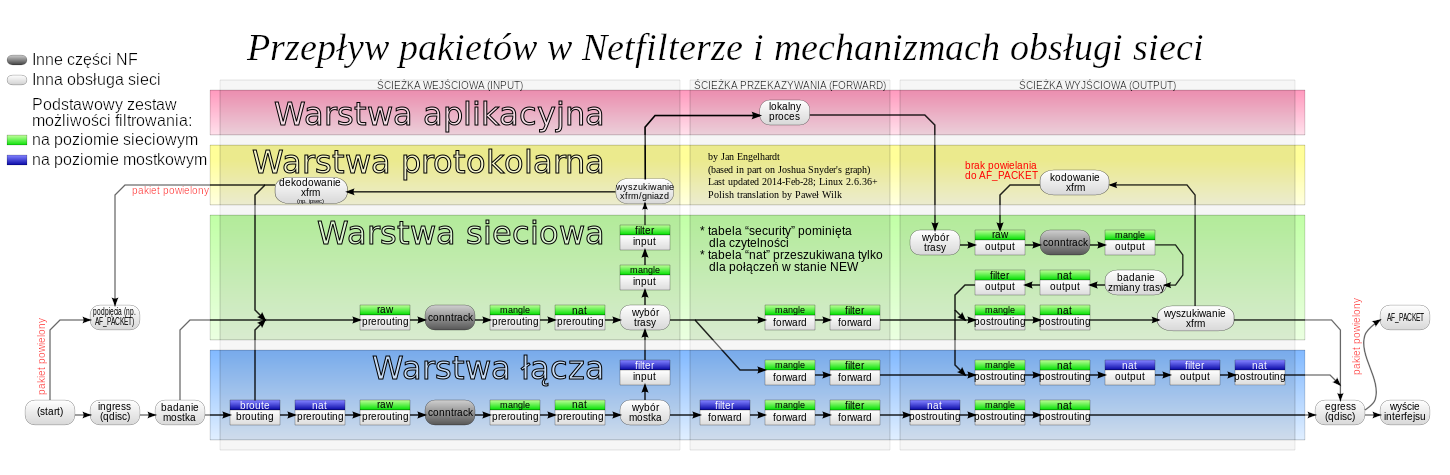
Nie dopatrzymy się tam jednak tej tablicy netdev . Zgodnie z tym co jest napisane
w tej prezentacji,
tablica netdev jest zlokalizowana zaraz za ingress (tym od TC), który wyżej jest opisany jako
ingress (qdisc) . Widać zatem, że jest to praktycznie na początku drogi pakietu.
Struktura tablicy netdev w nftables
Tablica netdev składa się w zasadzie z jednego łańcucha podstawowego, który ma zaczep (hook)
ingress . Przez ten łańcuch przechodzić będzie cały ruch sieciowy skierowany do naszej maszyny.
Poniżej znajdują się reguły, które mają na celu dodanie stosownej struktury do filtra nftables :
#!/usr/sbin/nft -f
create table netdev traffic-control
create chain netdev traffic-control INGRESS { type filter hook ingress device bond0 priority 0; policy accept; }
To, co trzeba uwzględnić przy tworzeniu tej tablicy, a konkretnie jej łańcucha, to nazwa interfejsu
sieciowego (określona w device ). W powyższym przykładzie tablica netdev została stworzona dla
interfejsu bond0 , bo akurat w tym przypadku mamy do czynienia
z bonding'iem interfejsów sieciowych,
a konkretnie wlan0 + eth0 + usb0 , przez co zamiast operować na każdym interfejsie z osobna,
można mieć jeden wirtualny interfejs i to na nim filtrować ruch, co ułatwia nieco zdanie.
Podobnie sprawa wygląda w przypadku interfejsów zmostkowanych (bridge), z tym, że tutaj tworzenie
tablicy netdev dla interfejsu mostka nie zawsze może być pożądane. Rozpatrzmy sobie przykładowo
sytuację, w której tylko jeden z interfejsów mostka wymaga dodatkowego filtrowania w postaci tej
tablicy. Jeśli stworzymy tablicę netdev dla zbiorczego interfejsu mostka, to ruch na wszystkich
interfejsach podpiętych do niego będzie przechodził przez tę tablicę, co wiązałoby się z dodatkowym
przetwarzaniem pakietów w przypadku tych interfejsów, gdzie to filtrowanie jest zupełnie zbędne.
Dobrze jest też rozdzielić ruch ICMP i TCP (o UDP będzie nieco później) i przekierować pakiety do osobnych łańcuchów. Tworzymy zatem dwa nowe łańcuchy i przekierowujemy do nich ruch:
create chain netdev traffic-control chain-tcp
create chain netdev traffic-control chain-icmp
add rule netdev traffic-control INGRESS iif !="lo" ip protocol vmap { tcp:jump chain-tcp, icmp:jump chain-icmp }
Unikanie ataku SYN flood z nftables
Technicznie rzecz biorąc, to obecnie ataki SYN flood nie
powinny wyrządzić szkody naszemu linux'owi, bo kernel od jakiegoś już czasu, a konkretnie od
końcówki 2015 roku zyskał nowy mechanizm ochronny
zwany tcp/dccp lockless listener, który to dość znacznie
łagodzi niedogodności związane z tego typu atakami DOS/DDOS. Niemniej jednak, jeśli chcielibyśmy
nieco dozbroić naszą maszynę, to możemy do tablicy netdev dodać kilka dodatkowych reguł.
Tworzymy najpierw set, w którym będą przechowywane źródłowe adresy IP hostów chcących nawiązać połączenie z naszym linux'em:
add set netdev traffic-control meter-tcp { type ipv4_addr; flags dynamic; timeout 60s; size 128000; }
W timeout określamy przez jaki czas wpis w tym secie będzie figurował, a w size maksymalną
ilość wpisów w secie. Gdy zostanie stworzony wpis w secie i przez następne 60 sekund nie zostanie
odnotowany żaden pakiet SYN z danego adresu IP, to wpis zostanie z seta sunięty, a informacja o nim
przestanie marnować miejsce w pamięci RAM. Warto o tym fakcie pamiętać i nie ustawiać w timeout
sporych wartości, by niepotrzebnie nie marnować pamięci operacyjnej.
Mając set, możemy w oparciu o niego filtrować ruch. Dodajmy zatem jeszcze te poniższe regułki:
add rule netdev traffic-control chain-tcp meta l4proto tcp tcp flags & (fin|syn|rst|ack) == syn add @meter-tcp { ip saddr timeout 60s limit rate over 10/second } counter drop
add rule netdev traffic-control chain-tcp meta l4proto tcp tcp flags & (fin|syn|rst|ack) == syn counter accept
Te reguły dopasowują pakiety w oparciu o ustawione flagi TCP, a konkretnie jest sprawdzana flaga SYN, której obecność w pakiecie inicjuje nowe połączenie w tym protokole. Pierwsza reguła doda do seta źródłowy adres IP na czas 60 sekund oraz ograniczy ilość tych pakietów do 10 na sekundę. Jeśli tych pakietów w ciągu pojedynczej sekundy z danego adresu IP byłoby więcej, to zostaną one zablokowane przez właśnie tę regułę. Druga reguła ma na celu zaakceptowanie pakietów mających ustawioną flagę SYN, co otwiera im drogę do dalszego procesowania przez linux'owy firewall.
Warto tutaj zaznaczyć, że to iż pakiet w tablicy netdev zostanie zaakceptowany nie oznacza, że
kończy się jego przetwarzanie przez zaporę sieciową. Jeśli mamy w filtrze dodatkowe tablice, np.
raw czy filter , to pakiet jak najbardziej przez nie będzie musiał przejść.
Limitowanie pakietów SYN na konkretnych portach
W nftables istnieje możliwość tworzenia setów połączonych. Taki set może przechowywać kilka
wartości, np. źródłowy adres IP, docelowy adres IP, źródłowy port, docelowy port, itd. Każda
kombinacja tych elementów jest możliwa przez zastosowanie . . Przykładowo, można by stworzyć set,
który by zawierał adres źródłowy hosta próbującego nawiązać połączenie oraz port docelowy, na który
próbuje się on połączyć:
add set netdev traffic-control meter-tcp { type ipv4_addr . inet_service; flags dynamic; timeout 60s; size 128000; }
add rule netdev traffic-control chain-tcp meta l4proto tcp tcp flags & (fin|syn|rst|ack) == syn add @meter-tcp { ip saddr . tcp dport timeout 60s limit rate over 10/second } counter drop
add rule netdev traffic-control chain-tcp meta l4proto tcp tcp flags & (fin|syn|rst|ack) == syn counter accept
Niemniej jednak, w takim przypadku dany adres IP będzie figurował w secie kilka razy w zależności od portów, na które wysłał on pakiety SYN, przykładowo:
# nft list meter netdev traffic-control meter-tcp
table netdev traffic-control {
set meter-tcp {
type ipv4_addr . inet_service
size 128000
flags dynamic,timeout
timeout 1m
elements = { 192.168.1.150 . 22 expires 45s803ms limit rate over 10/second,
192.168.1.150 . 222 expires 53s650ms limit rate over 10/second,
192.168.1.150 . 2222 expires 58s530ms limit rate over 10/second }
}
}
I tu już widać niebezpieczeństwo związane z niezbyt przemyślanym wdrożeniem tego mechanizm ochronny przed SYN flood -- będzie on działał jedynie na naszą niekorzyść, bo dany adres IP będzie w stanie wysłać do naszego linux'a całą masę pakietów SYN na dowolne porty, a to z kolei rozbuduje set, co zje nam tylko niepotrzebnie pamięć operacyjną, bo te pakiety i tak będą przecież przetwarzane przez kolejne tablice i łańcuchy firewall'a, aż w końcu gdzieś zostaną zablokowane lub przepuszczone.
A co z atakiem UDP flood?
Z racji, że protokół UDP jest bezpołączeniowy (nie jest utrzymywana żadna sesja), to nie mamy do
czynienia z flagami, tak jak w przypadku protokołu TCP, i nie możemy zbytnio uchronić się
przed atakiem UDP flood wykorzystując do tego
celu tablicę netdev . Ten atak w zasadzie polega na wysyłaniu całej masy pakietów UDP na losowe
porty serwera. Takie zachowanie może skutkować odsyłaniem sporej ilości pakietów ICMP Destination
Unreachable przez atakowanego hosta, co może doprowadzić do wyczerpania się jego zasobów procesora
i pamięci.
Przed UDP flood można się ochronić zaprzęgając mechanizm śledzenia połączeń (conntrack) ale ten
zaczyna widzieć pakiety dopiero po przejściu ich przez tablicę raw i najwcześniej jest to łańcuch
PREROUTING tablicy mangle (wyżej na obrazku).
Oczywiście linux standardowo jest w stanie się ochronić przed UDP flood limitując ilość odsyłanych
pakietów ICMP Destination Unreachable. W zasadzie to trzeba sobie dostosować jedynie te poniższe
parametry w pliku /etc/sysctl.conf :
net.ipv4.icmp_msgs_per_sec = 1000
net.ipv4.icmp_ratelimit = 2000
net.ipv4.icmp_ratemask = 6168
Parametr icmp_msgs_per_sec określa limit ilości pakietów ICMP, które linux będzie w stanie wysłać
w ciągu jednej sekundy. To ustawienie aplikuje się jedynie do komunikatów określonych przez
parametr icmp_ratemask . Z kolei icmp_ratelimit spowalnia odpowiedzi na pakiety ICMP,
określone również w icmp_ratemask. Jeśli zaś chodzi o maskę zdefiniowaną w icmp_ratemask , to
sprawa wygląda nieco skomplikowanie. Poniżej znajduje się rozpiska bitów komunikatów ICMP:
Bity: IHGFEDCBA9876543210
Maska: 0000001100000011000 (6168)
0 Echo Reply
3 Destination Unreachable *
4 Source Quench *
5 Redirect
8 Echo Request
B Time Exceeded *
C Parameter Problem *
D Timestamp Request
E Timestamp Reply
F Info Request
G Info Reply
H Address Mask Request
I Address Mask Reply
Pozycje mające * są domyślnie włączone i te limity w icmp_msgs_per_sec oraz icmp_ratelimit
aplikują się tylko i wyłącznie do tych pozycji. Jeśli chcemy by limity chroniły również inne typy
komunikatów ICMP, to naturalnie trzeba sobie tę maskę dostosować.
Jeśli jednak ktoś chciałby jeszcze dodatkowo jakieś reguły do zapory dodać, to można by ograniczyć ilość jednoczesnych połączeń UDP przypadających na jeden adres IP:
create chain ip mangle flood-udp
add set ip mangle meter-udp { type ipv4_addr; flags dynamic; size 128000; }
add rule ip mangle PREROUTING iif !="lo" meta l4proto udp ct state new jump flood-udp
add rule ip mangle flood-udp add @meter-udp { ip saddr ct count over 100 } counter drop
add rule ip mangle flood-udp counter return
Warto zwrócić uwagę, że ten limit połączeń został dodany do tablicy mangle , a nie netdev .
Kluczową rolę w tym mechanizmie limitowania połączeń UDP gra { ip saddr ct count over 100 } w
przedostatniej regule. Monitoruje ona ilość wpisów w tablicy conntrack'a dla tego konkretnego
adresu IP. Gdy liczba wpisów przekroczy 100, kolejne połączenia z tego adresu IP będą blokowane.
Warto tu też zaznaczyć, że ilość wpisów w tablicy conntrack'a nie oznacza ilości realnych połączeń.
W przypadku protokołu UDP w tablicy conntrack'a możemy zanotować [UNREPLIED] lub [ASSURED] w
zależności od tego czy druga strona odpowiedziała na pakiet UDP. Każdy z wpisów oznaczony przez
jeden lub drugi tag ma inny czas życia w tablicy conntrack'a (domyślnie 30s i 180s odpowiednio dla
[UNREPLIED] i [ASSURED] ). Wartości tych czasów można dostosować w pliku /etc/sysctl.conf za
pomocą poniższych parametrów:
net.netfilter.nf_conntrack_udp_timeout = 30
net.netfilter.nf_conntrack_udp_timeout_stream = 120
Zatem jeśli połączenie UDP zostało potwierdzone i zakończone, to nasz system będzie je jeszcze widział przez następne 180s. Gdyby host nawiązujący połączenie z naszą maszyną uderzył w limit 100 jednoczesnych połączeń (wpisów w tablicy conntrack'a), to nawet po zakończeniu ich wszystkich musiałby czekać 3 minuty aż wpisy z tablicy conntrack'a zostałyby usunięte. Dopiero wtedy linux'owy firewall pozwoli temu hostowi na stworzenie nowych połączeń.
Unikanie ataku ICMP/PING flood z nftables
Jeśli się przyjrzymy tej umieszczonej wyżej rozpisce bitów komunikatów ICMP, to zauważymy, że
standardowo pakiety ICMP Echo Reply nie są limitowane w żaden sposób, co z kolei otwiera drogę
do ataku ICMP/PING flood. Możliwa jest zatem sytuacja,
gdzie nasz linux będzie próbował odpowiadać na każdy pakiet ping , który otrzyma, co może
wyczerpać jego zasoby procesora, pamięci operacyjnej i zjeść sporą część przepustowości łącza
sieciowego.
Można naturalnie podciągnąć odpowiedzi na ping pod limity w icmp_msgs_per_sec oraz
icmp_ratelimit ale taki limit w przypadku odpowiedzi na ping może prowadzić do błędnych wniosków
przy próbie ustalenia problemów z działaniem sieci. Dlatego też te komunikaty nie są limitowane
domyślnie i jeśli chcemy je w jakiś sposób ograniczać to lepiej jest to zrobić na zaporze sieciowej.
Podobnie jak w przypadku SYN flood, atak ICMP/PING flood można ograniczyć za pomocą tablicy
netdev . Tworzymy zatem w w niej set dla adresów źródłowych wysyłających pakiety ICMP:
add set netdev traffic-control meter-icmp { type ipv4_addr; flags dynamic; timeout 60s; size 128000; }
I dorabiamy do tego dwa ograniczenia:
add rule netdev traffic-control chain-icmp add @meter-icmp { ip saddr limit rate over 10/second } counter drop
add rule netdev traffic-control chain-icmp limit rate over 1 mbytes/second counter drop
add rule netdev traffic-control chain-icmp counter accept
Pierwsza reguła nakłada limit 10 pakietów ICMP (wszystkie typy) na sekundę na pojedynczy źródłowy adres IP. Druga reguła ogranicza maksymalną przepustowość łącza, która może zostać przeznaczona na pakiety ICMP, w tym przypadku 1 MiB/s. Jeśli któryś z tych warunków zostanie spełniony, to te nadmiarowe pakiety ICMP (wychodzące poza limity) zostaną zrzucone i nasz linux nie będzie na nie odpowiadał. Trzecia reguła akceptuje pakiety ICMP.