Równoważenie ruchu łącz kilku ISP (load balancing)
Spis treści
Podłączenie pojedynczego komputera do sieci raczej nie stanowi żadnego problemu dla przeciętnego
użytkownika linux'a. Wystarczy jedynie skonfigurować kilka parametrów i możemy oglądać swoje
ulubione serwisy www. Co jednak w przypadku, gdy mamy do dyspozycji kilka łącz internetowych? Jedną
z opcji jest używanie łącza tego ISP, które jest lepsze gabarytowo, a pozostałe łącza trzymać na
wypadek awarii tego pierwszego. Nie jest to zbytnio satysfakcjonujące rozwiązanie, zwłaszcza w
przypadku, gdy tym providerom płacimy za świadczone nam usługi. W taki sposób płacimy, np. za dwa
łącza, a korzystamy z jednego w danej chwili. W linux'ie obsługa wielu łącz różnych ISP jest dość
skomplikowana. By taki mechanizm zaimplementować sobie, trzeba stworzyć kilka tablic routingu.
Następnie ruch sieciowy musi zostać oznaczony w iptables i przekierowany do tych tablic przez
kernel. Przy odrobienie wysiłku jesteśmy jednak w stanie zaprojektować sobie load balancer, który
będzie równoważył obciążenie łącza między kilku ISP. Dodatkowo, jeśli jedno z łączy nam nawali, to
automatycznie zostaniemy przełączeni na drugie łącze (failover). W tym artykule postaramy się
zaprojektować taki właśnie mechanizm.
Filtrowanie trasy powrotnej (rp_filter)
Ze względów bezpieczeństwa, cześć dystrybucji linux'a włącza mechanizm filtrowania trasy powrotnej
pakietów. Gdy maszyna, która ma włączony ten mechanizm otrzymuje pakiet, próbuje pierw sprawdzić czy
źródło tego pakietu jest osiągalne przez interfejs, przez który pakiet trafił do danej maszyny.
Jeśli źródło nie jest osiągalne, pakiety zostaną zrzucone. Znacznie poprawia to bezpieczeństwo
ponieważ poważnie utrudnia spoof'owanie adresu IP. Trzeba jednak brać pod uwagę fakt, że włączenie
filtrowania trasy powrotnej często stwarza problemy, gdy mamy do czynienia z wieloma interfejsami
sieciowymi. By móc zaimplementować sobie load balancing i failover łącza kilku ISP, to musimy
wyłączyć to filtrowanie. Możemy to zrobić zapośrednictwem pliku /etc/sysctl.conf dopisując w nim
te dwa poniższe parametry:
net.ipv4.conf.all.rp_filter = 2
net.ipv4.conf.default.rp_filter = 2
W niektórych linux'ach ten parametr przyjąć może wartości 0 (wyłącza) , 1 (włącza) lub 2 . W
przypadku ustawienia 2 , nie będzie miał znaczenia interfejs, przez który pakiet dodarł do naszej
maszyny, tylko to czy źródło pakietu jest osiągalne przez którykolwiek z nich. Jest to swojego
rodzaju kompromis w stosunku do całkowitego wyłączenia filtrowania.
Translacja adresów (NAT, maskarada)
Na każdy interfejs sieciowy, który będziemy chcieli uwzględnić w konfiguracji równoważenia ruchu
sieciowego, trzeba będzie założyć NAT, czyli translację adresów. To zadanie z kolei sprawdza się do
dodania poniższych reguł w filtrze iptables :
iptables -t nat -A POSTROUTING -o bond0 -j MASQUERADE
iptables -t nat -A POSTROUTING -o wwan0 -j MASQUERADE
Mimo, że korzystamy tutaj z translacji adresów, to forwarding pakietów na tych interfejsach nie jest wymagany.
Automatyczny failover łącza
Mając do dyspozycji minimum dwa łącza od różnych ISP, może się zdarzyć tak, że któreś z nich nam
zwyczajnie nawali. W takiej sytuacji przy podniesionym interfejsie sieciowym i próbie połączenia
przez niego, dostaniemy komunikat No route to host lub też Network is unreachable . Oczywistym
jest, że takie połączenie nie zostanie zrealizowane. Natomiast od nas wymagane jest stałe
monitorowanie łącza pod kątem dostępności. Od wersji kernela 4.4 nie musimy się już troszczyć o tego
typu sprawy, bo mamy w nim dostępny parametr ignore_routes_with_linkdown . Jak jego nazwa
wskazuje, wszystkie nieosiągalne trasy będą ignorowane. W efekcie połączenia zostaną puszczone
automatycznie drugim łączem. Oczywiście sesje TCP zostaną powieszone, a transfer danych zatrzymany.
Jeśli przywrócenie łączności nie nastąpi w krótkim czasie, to raczej trzeba będzie ponownie nawiązać
połączenie. Dobrze jest zatem ustawić sobie ten parametr dodać co pliku /etc/sysctl.conf poniższe
linijki:
net.ipv4.conf.all.ignore_routes_with_linkdown = 1
net.ipv4.conf.default.ignore_routes_with_linkdown = 1
net.ipv6.conf.all.ignore_routes_with_linkdown = 1
net.ipv6.conf.default.ignore_routes_with_linkdown = 1
Wielościeżkowa domyślna trasa routingu (multipath gateway)
Wielościeżkowa domyślna trasa routingu jest połączeniem kilku domyślnych bramek, które zwykle są przypisywane poszczególnym interfejsom sieciowym. Jeśli nie chce nam się zbytnio kombinować z dodatkowymi tablicami routingu, to przy pomocy takiej bramki możemy praktycznie bez większego wysiłku rozłożyć ruch na różnych ISP.
Na necie można znaleźć informację, że ruch sieciowy możemy rozkładać na kilku providerów internetowych w oparciu o pakiety (per-packet), o połączenia (per-connection) oraz przepływ pakietów (per-flow). Różnica między nimi jest następująca. W per-packet, pakiety należące do tego samego połączenia mogą być przesyłane przez wielu ISP. W przypadku per-connection, pakiety są grupowane i przypisywane do określonego połączenia w oparciu o protokół, adres źródłowy i docelowy oraz port źródłowy i docelowy. Wszystkie takie pakiety w połączeniu mogą zostać przesłane tylko przez jednego ISP. Natomiast jeśli chodzi o per-flow, to tutaj decyduje adres źródłowy i docelowy. Jeśli szereg połączeń ma pasujące te dwa parametry, to zostaną one wszystkie przesłane przez tego samego ISP. Protokoły takie jak TCP wymagają do poprawnego działania per-connection lub per-flow. Natomiast per-packet może działać bez problemu z protokołem UDP.
O wyborze rozdzielenia ruchu w oparciu o pakiety (per-packet) ma decydować parametr equalize
dodany do ip route . Jeśli equalize zostanie określony, to będziemy mieli do czynienia z
sytuacją, gdzie każde z połączeń będzie w stanie wykorzystać pełną przepustowość wszystkich
dostępnych providerów internetowych. Jeśli nie skorzystamy z equalize , to każde z połączeń
będzie mogło wykorzystać tylko łącze jednego z operatorów. Nadal możliwe jest nawiązywanie kilku
równoczesnych połączeń i wtedy ruch zostanie rozłożony na wszystkich ISP.
W aktualnej wersji kernela w debianie (4.5) nie ma wsparcia dla tego całego equalize i raczej ten
parametr w ip route nie zostanie póki co zaimplementowany. Zatem nie ma co sobie nim głowy
zawracać. Nie będziemy więc zagłębiać się w rozdzielanie ruchu w oparciu o pakiety. Do
zaimplementowania rozwiązania opartego o przepływ pakietów (per-flow) posłuży nam wspomniane wyżej
polecenie ip route . Musimy za jego pomocą określić bramę domyślą uwzględniając przy tym dwa
dodatkowe parametry: nexthop oraz weight . Poniżej jest przykładowe polecenie:
# ip route add default \
nexthop via 192.168.1.1 dev bond0 weight 4 \
nexthop via 10.143.105.17 dev wwan0 weight 1
Warto zaznaczyć tutaj, iż mimo, że ta trasa składa się z dwóch bram, to w dalszym ciągu jest
uznawana przez kernel za pojedynczą trasę. Bramy określamy w parametrze nexthop podając mu adres
oraz interfejs. Z kolei parametr weight odpowiada za częstość wybierania danej trasy dla nowych
połączeń. W tym przypadku rozdział jest mniej więcej 4/5 dla pierwszej bramy i 1/5 dla drugiej.
Parametry wag są opcjonalne. Jeśli ich nie podamy, wtedy nowe połączenia powinny zostać rozłożone w
stosunku 50%:50%.
Problem z tą powyższa trasą jest taki, że operuje ona na cache, który wykorzystuje hash adresów źródłowych i docelowych. W ten sposób każde połączenie wykonane na określony adres IP z tego samego adresu źródłowego zawsze będzie odbywać się przez ten sam interfejs sieciowy. W efekcie jeśli byśmy chcieli sprawdzić swój adres IP na jednym z serwisów www do tego przeznaczonych, to zawsze zostanie nam pokazany taki sam adres i to bez znaczenia ile razy taką stronę odpowiedzmy. Nie nazwałbym tego zbytnio równoważeniem ruchu w przypadku, gdy z internetu korzysta tylko jeden użytkownik i do tego z jednego komputera w tym samym czasie.
Jeśli potrzebujemy faktycznie mechanizmu, który zrównoważy nam ruch sieciowy, to musimy niestety
zagłębić się w tajniki routingu na linux'ie i stworzyć sobie
kilka tablic routingu. Przy ich
pomocy będziemy w stanie rozdzielić ruch na podstawie oznaczeń FWMARK w iptables . Zanim jednak
przejdziemy do rozdzielenia ruchu, rzućmy okiem na te tak złowrogo wyglądające tablice routingu.
Tablica routingu
Każda maszyna podłączona do sieci do poprawnego komunikowania się ze światem wymaga odpowiednio
skonfigurowanych tablic rutingu. Pakiety, które przechodzą przez taki komputer, są sprawdzane przez
kernel pod kątem adresu IP przeznaczenia. Ten adres jest kluczowy przy określaniu trasy. To na jego
podstawie system wie, do której sieci pakiet ma trafić, a ta sieć z kolei jest powiązana z
określonym interfejsem sieciowy. Wszystkie te powiązania adresów, sieci i interfejsów są zbierane i
umieszczane w tablicy routingu. Każdy linux może mieć kilka takich tablic. Standardowo są jednak do
dyspozycji tylko trzy: local , main oraz default . Linux'owe narzędzia, takie jak ifconfig ,
route czy ip operują domyślnie na tablicach main i local . Wpisy w tablicy local są
zarządzane głównie przez kernel i my jako administrator nie możemy do tej tablicy dodawać żadnych
nowych wpisów. Możemy za to usuwać z niej te już istniejące wpisy, choć nie powinniśmy tego robić.
Nas głównie interesować będzie tablica main . Poniżej znajduje się przykład takiej tablicy:
# ip route list table main
default via 192.168.1.1 dev bond0
192.168.1.0/24 dev bond0 proto kernel scope link src 192.168.1.150
192.168.10.0/24 dev br-lxc proto kernel scope link src 192.168.10.100
Ta powyższa tablica nie jest zbytnio rozbudowana. Są w niej określone trzy reguły dotyczące dwóch
interfejsów: bond0 oraz br-lxc . Widzimy, że mamy do czynienia z dwiema sieciami, po jednej dla
każdego z interfejsu: 192.168.1.0/24 oraz 192.168.10.0/24 . W przypadku, gdy pakiet zostanie
zaadresowany do jednej z tych sieci, to zostanie puszczony przez jeden z tych dwóch interfejsów.
Dodatkowo, w zależności od adresu docelowego, pakiet zostanie uzupełniony o odpowiedni adres
źródłowy. Ten adres jest określony w parametrze src . Zatem jeśli pakiet będzie adresowany na
IP 192.168.1.120, to zostanie mu ustawiony adres źródłowy 192.168.1.150 i to na ten adres host
docelowy będzie musiał przysłać odpowiedź. Jeśli pakiet będzie zawierał inny adres docelowy niż
określony przez te dwie powyższe sieci, to wtedy zostanie on wysłany na adres 192.168.1.1 . Jest to
brama domyślna. Gdybyśmy nie określili tego wpisu z default , router zwróciłby dla takich pakietów
komunikat ICMP net unreachable (ICMP Typ 3 Kod 0).
Trasy mogą być różnych typów, a te mogą się zmieniać w zależności od tablicy routingu. Dla
przykładu, wszystkie powyższe trasy w tablicy main są typu unicast . Natomiast w tablicy
local mamy trasy broadcast i local . Poniżej zaś jest rozpiska możliwych do określenia typów
tras (tutaj są przykłady):
unicast-- wpis w tablicy opisuje rzeczywistą trasę umożliwiającą komunikację z siecią opisaną przez zadany prefiks.local-- miejsca docelowe są przypisane do lokalnej maszyny. Pakiety zostaną skierowane z powrotem do komputera.broadcast-- adres rozgłoszeniowy. Pakiety zostaną wysłane jako rozgłoszenie w warstwie 2.multicast-- specjalny typ wpisu, używany do obsługi routingu typu multicast. Normalnie nie pojawia się w tablicach routingu.throw-- specjalny typ wpisu, używany wraz z regułami polityki routingu. Jeżeli trasa tego typu zostanie dopasowana, zadziała tak, jakby w tablicy nie znaleziono pasującej trasy (spowoduje to przejście do następnej reguły). Brak polityki routingu jest równoznaczne z brakiem trasy w tablicy routingu. W ten sposób pakiety są zrzucane i generowana jest wiadomośćnet unreachable(ICMP Typ 3 Kod 0). Jeżeli nadawca jest lokalny, to otrzyma błąd ENETUNREACH.unreacheable-- miejsce docelowe jest nieosiągalne. Dopasowanie trasy spowoduje wysłanie wiadomości ICMPhost unreachable(ICMP Typ 3 Kod 1) do zdalnych nadawców. Lokalni nadawcy otrzymają komunikat EHOSTUNREACH.prohibit-- miejsce docelowe jest nieosiągalne. Dopasowanie trasy spowoduje wysłanie komunikatu ICMPcommunication administratively prohibited(ICMP Typ 3 Kod 13). Lokalni nadawcy otrzymają błąd EACCESS.blackhole-- miejsce docelowe jest nieosiągalne. Pakiety są zrzucane po cichu. Lokalni nadawcy otrzymują błąd EINVAL.nat-- ten typ trasy służył do realizacji NAT. W jądrze serii >2.6 nie jest obsługiwany.anycast-- nie zaimplementowane. Miejsce docelowe jest adresem typuanycastprzyporządkowanym do lokalnej maszyny. Ten typ trasy jest podobny dolocalz tą różnicą, że adres docelowy nie jest poprawnym adresem źródłowym.
Podczas listowania reguł w tablicy main mieliśmy także określony protokół ( proto ). Informuje
nas on o tym, kto daną trasę dodał do tablicy routingu. Protokół może zostać oznaczony liczbowo, lub
za pomocą nazwy zapisanej w pliku /etc/iproute2/rt_protos . Wyróżniamy następujące protokoły:
kernel-- trasa została dodana automatycznie przez jądro podczas konfiguracji sieci. Przykładem mogą być trasy powiązane z adresem przypisanym do interfejsu sieciowego.boot-- trasa została dodana podczas uruchamiania systemu. Trasy takie zostaną automatycznie usunięte przez demona routingu, jeżeli zostanie uruchomiony. Jest to domyślny protokół, więc jeżeli trasa ma być używana w konfiguracji z demonami routingu należy podawać protokółstatic.static-- trasa została dodana przez administratora systemu. Trasa taka nadpisuje trasy dynamiczne, jest respektowana przez demony routingu, a nawet rozgłaszana przez nie sąsiadom.redirect-- trasa została dodana w wyniku otrzymania przekierowania ICMP (5.x). Trasy takie mają ograniczony czas życia.ra-- trasa została dodana w wyniku działania protokołu Router Discovery.
Zasięg tras ( scope ) jest zwykle ustalany przez narzędzie ip automatycznie i nie trzeba go
ręcznie określać. Niemniej jednak, wyróżniamy następujące zasięgi:
host-- trasa o tym zasięgu prowadzi na adres lokalnego hosta.link-- trasa o tym zasięgu prowadzi na adres sieć lokalnej, która jest osiągalna przez przypisany jej interfejs sieciowy. Dotyczy również adresów broadcast. A to z tego względu, że broadcast ma tylko sens w sieci, gdzie mamy podłączonych ze sobą szereg komputerów, do których dostęp możemy uzyskać przez dany interfejs sieciowy.global-- trasa o tym zasięgu prowadzi zwykle do bramy domyślnej.
Konfigurując interfejs sieciowy, trasa dla pakietów dla tego interfejsu jest automatycznie
konfigurowana przez kernel na podstawie podanych parametrów (adres i maska). Weźmy przykładowo w/w
interfejs bond0 . By go skonfigurować i jednocześnie określić trasy dla niego, musimy w terminalu
wydać te poniższe polecenia:
# ip addr add 192.168.1.150/24 brd + dev bond0
# ip link set dev bond0 up
W ten sposób zostanie utworzona przez kernel trasa dynamiczna opisująca sieć 192.168.1.0/24 , która
jest osiągalna przez interfejs bond0 . Nie zawsze tego typu automatyzacja jest pożądana. Jeśli
chcemy skonfigurować trasy statycznie, to musimy określić adresy podając maskę /32 , np.
192.168.1.150/32 . W każdym innym przypadku nie ma potrzeby manualnie dodawać tras. Po
skonfigurowaniu interfejsów bond0 oraz br-lxc , pakiety mogą być przesłane między tymi dwiema
sieciami. Czyli pakiety muszą zawierać adres IP, który należy do jednej lub drugiej sieci. Niemniej
jednak, jeśli pojawi się pakiet, który w polu adresu docelowego zawiera IP, spoza tych dwóch
powyższych sieci, to przy próbie połączenia wystąpi błąd.
Domyślna brama/trasa (default gateway)
By pakiety mogły się dostać do sieci innych niż te wyżej określone, musimy skonfigurować bramę
domyślną. Nie jest ona konfigurowana automatycznie przez kernel, tak jak trasy sieci. A to z tego
względu, że zwyczajnie nie wiemy, jaki adres może mieć brama domyślna. Dlatego też zawsze trzeba ją
określać manualnie. Zwykle przy określaniu bramy domyślnej nie używa się dla niej adresu jako
takiego. Zamiast niego korzysta się ze słówka default , który oznacza adres 0.0.0.0 i maskę
0.0.0.0 . Poniżej jest polecenie konfigurujące bramę domyślną:
# ip route add default via 192.168.1.1 dev bond0
W ten sposób dopełniliśmy całą tablicę routingu i kernel wie gdzie ma przesyłać pakiety o określonych docelowych adresach IP. Niemniej jednak, w tym artykule nie interesuje nas zbytnio podstawowa tablica routingu oferowana przez systemy linux'owe, a możliwość korzystania z wielu tablic routingu jednocześnie.
Metryka trasy (metric)
Jeśli chcemy korzystać z dwóch, czy też i więcej, ISP jednocześnie, to musimy skonfigurować bramy
domyślne dla każdego ISP. Robimy to mniej więcej tak samo jak zostało zrobione powyżej. By móc tego
typu zabieg przeprowadzić, musimy określić metryki dla tras wszystkich interfejsów sieciowych, przez
które mamy dostępny internet. Standardowo każda trasa domyślna ma ustawioną metrykę 0 , przez co w
systemie możemy posiadać tylko jedną domyślną bramę. W przypadku różnych metryk, w tablicy routingu
możemy mieć określonych kilka domyślnych bramek. Metryki zaś definiujemy za pomocą parametru
metric dodanego do polecenia ip route , przykładowo:
# ip route add default via 192.168.1.1 dev bond0 metric 10
# ip route add default via 10.143.105.17 dev wwan0 metric 100
Im niższą wartość ustawimy w opcji metric , tym brama ma większy priorytet. W ten sposób możemy
określić pożądaną przez nas kolejność bramek domyślnych. Zatem standardowo, po podniesieniu obu
interfejsów, ruch będzie przesyłany przez interfejs bond0 . Gdy połączenie przez ten interfejs
zostanie w jakiś sposób utracone, wtedy pakiety zostaną przełączone na drugie łącze. W ten sposób
mamy zapewniony automatyczny failover łącza.
Wiele tablic routingu
W linux'ie mamy możliwość zdefiniowania 255 różnych tablic routingu. Jako, że chcemy korzystać z
dwóch ISP, to dla każdego z nich możemy utworzyć osobną tablicę routingu i do niej kierować ruch w
oparciu o pewne zasady. Tego typu zabieg rozpoczynamy od edycji pliku /etc/iproute2/rt_tables .
Ten plik może nie istnieć i nic złego się z tego powodu nie powinno dziać. Niemniej jednak jeśli
chcemy określić dodatkowe tablice routingu, to musimy utworzyć ten plik. Następnie definiujemy w nim
wpisy podobne do tych poniżej:
255 local
254 main
253 default
0 unspec
10 home
20 lte
Wyżej określiliśmy sobie dwie dodatkowe tablice routingu: home oraz lte . Nazwy mogą być
dowolne. Każda z tych nowych tablic jest póki co pusta. Możemy to sprawdzić wydając poniższe
polecenia:
# ip route show table lte
# ip route show table home
Jeśli chcielibyśmy teraz rozdzielić ruch na kilku ISP, to w każdej tej dodatkowej tablicy routingu musimy określić domyślną bramę. Robimy to przy pomocy tych poniższych poleceń:
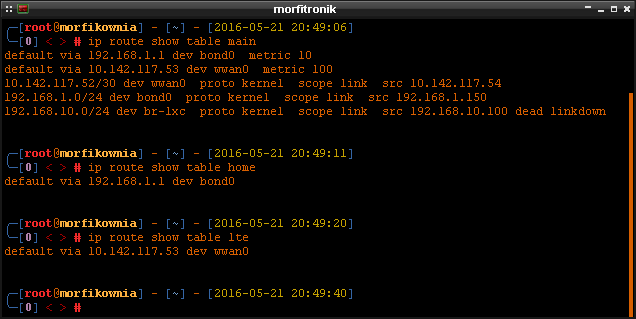
# ip route add default via 192.168.1.1 dev bond0 table home
# ip route add default via 10.142.117.53 dev wwan0 table lte
W tej chwili tablice routingu powinny wyglądać mniej więcej tak jak na tym poniższym obrazku:
By ten cały mechanizm routujący puścić w ruch potrzebne nam są jeszcze reguły routingu. To w oparciu o nie, kernel będzie wiedział gdzie ma przesłać dany pakiet.
Reguły routingu
W przypadku, gdy mamy do czynienia z pojedynczym interfejsem sieciowym, zwykle nas nie interesują
reguły rutingu. I tak wiemy, że pakiet opuści naszą maszynę przez ten jeden interfejs sieciowy,
która ona posiada. Nie ma przecie innej opcji. Niemniej jednak, w bardziej skomplikowanych
sytuacjach będziemy mieli do czynienia z wieloma interfejsami sieciowymi, tak jak mamy w tym
przypadku. Mając do dyspozycji kila łącz różnych providerów internetowych, dostęp do hostów w
internecie można uzyskać za sprawą kilku różnych tras. Każda z nich jest nas w stanie zaprowadzić
tego samego miejsca przeznaczenia. Standardowo w linux'ie mamy trzy reguły, które możemy sobie
wyświetlić przy pomocy polecenia ip rule :
# ip rule show
0: from all lookup local
32766: from all lookup main
32767: from all lookup default
Pierwsza reguła ma priorytet 0 , następne zaś 32766 i 32767 . Im niższa wartość, tym większy
priorytet. Każda reguła ma również selektor, w oparciu o który są przeprowadzane akcje routingu. W
tym przypadku wszystkie trzy reguły dotyczą pakietów z każdego źródła ( from all ) . Po
dopasowaniu pakietu na podstawie selektora, kernel musi podjąć jakąś akcję. W powyższych regułach,
wszystkie akcje sprowadzają się do przeszukania określonych tablic routingu: lookup local ,
lookup main oraz lookup default . O tablicach local i main powiedzieliśmy sobie parę słów
wcześniej. Natomiast tablica default jest zwykle pusta. Jest ona zarezerwowana na potrzeby
późniejszego przetwarzania w przypadku, gdy pakiet nie zostałby dopasowany do którejś z
poprzednich reguł.
Nie powinniśmy mylić ze sobą tablic routingu z regułami routingu. Reguły zawsze wskazują na którąś z tablic routingu. Kilka reguł może się odwoływać do jednej tablicy. Może też zaistnieć taka sytuacja, że do danej tablicy nie referuje żadna reguła. W takim przypadku, tablica nie jest używana ale dalej sobie istnieje. Tablica może jednak zniknąć, gdy wszystkie trasy wewnątrz niej zostają usunięte.
Każdy pakiet jest sprawdzany w oparciu o powyższe reguły począwszy od tej z najwyższym priorytetem.
Jeśli reguła zostanie dopasowana, to kończy się przetwarzanie pakietu. W przeciwnym wypadku, kernel
sprawdza następną regułę i tak do samego końca. Jeśli żadna reguła nie zostanie dopasowana, to wtedy
zostanie zwrócony odpowiedni komunikat ICMP, np. net unreachable .
Reguły można dodawać na kilka sposobów. Można operować na źródłowych i docelowych adresach IP
pakietów ( from/to ) . Można także posłużyć się interfejsem sieciowym ( iif/oif ). Istnieje
także opcja kierowania pakietów w oparciu o nałożone im oznaczenia w iptables ( fwmark ).
Analizując sobie mechanizm multiwan, który jest do zaimplementowania w OpenWRT przy pomocy
mwan3, byłem w stanie odtworzyć
reguły routingu, tak by można je było wprowadzić na debianie i dopasować na ich podstawie ruch.
Generalnie rzecz biorąc będą nas interesować dwa dopasowania, po jednym dla ruchu wychodzącego i
przychodzącego. Ruch wychodzący będzie dopasowywany w oparciu o FWMARK. Natomiast ruch przychodzący
w oparciu o interfejs sieciowy. Poniżej są przykładowe reguły, które rozdzielają ruch (póki co
statycznie) między tych dwóch naszych ISP:
# ip rule add iif bond0 priority 1001 table main
# ip rule add fwmark 0x5/0xff priority 2001 table home
# ip rule add iif wwan0 priority 1002 table main
# ip rule add fwmark 0x2/0xff priority 2002 table lte
Zasada działania przepływu pakietu w oparciu o tablice routingu main , lte oraz home jest
następująca. Pakiet wychodzący z naszej maszyny wpada do iptables . Tam zaś jest oznaczane
połączenie w oparciu o target MARK i CONNMARK.
Jeśli pakiet w stanie NEW będzie miał mark 0x5/0xff , to zostanie przesłany do tablicy home .
Podobnie sprawa wygląda w przypadku połączenia oznaczonego markiem 0x2/0xff , z tym, że to
połączenie trafi to tablicy lte . Jako, że w obu tych tablicach jest określona inna bramka
domyślna, to pakiety zostaną wysłane różnymi interfejsami sieciowymi przez innych ISP. Następnie w
drodze powrotnej, pakiety znów przejdą przez tablice routingu, z tym, że tutaj już ma spore
znaczenie priorytet, który został ustawiony w powyższych regułach. Reguły z iif , czyli te
dopasowujące ruch na podstawie interfejsu wejściowego, zostaną zaaplikowane wcześniej. Ich akcją
jest przeszukanie tablicy main, która zawiera konfigurację sieci, do których jest podłączony host. W
oparciu o te wpisy, pakiet trafi do maszyny bez problemu.
W powyżej podlinkowanym artykule opisałem sposób markowania pakietów przy pomocy iptables .
Niemniej jednak, w tym wpisie nie będziemy się skupiać na tym temacie, bo nas to zbytnio nie
interesuje w tym momencie. O ile samo markowanie pakietów i połączeń można zrobić czytając tamten
wpis, to nie zrobimy przy jego pomocy mechanizmu równoważącego ruch (load balancing). W dalszym
jednak ciągu działa nam failover, czyli w przypadku zaniku połączenia na jednym z tych interfejsów,
ruch zostanie przełączony automatycznie na drugi z nich.
Równoważenie obciążenia (load balancing)
Równoważenie obciążenia również zahacza o markowanie pakietów w iptables . Potrzebna nam jest
tylko reguła, która z pewnym prawdopodobieństwem oznaczy pakiety nowych połączeń markiem
0x5/0xff . Natomiast pozostałe połączenia, które nie mają jeszcze nałożonego marka, zostaną
oznaczone markerem 0x2/0xff . Jak tego typu zadanie zrealizować? Przede wszystkim, potrzebna nam
jest baza markująca. Jeśli korzystamy z kontroli ruchu w wykonaniu tc (traffic control), to po
dokładny opis jak ten mechanizm wykonać odsyłam pod podlinkowany wyżej wpis. Nam natomiast
potrzebne są te poniższe reguły, które trzeba dodać do iptables :
iptables -t mangle -N load-in
iptables -t mangle -N load-out
iptables -t mangle -A PREROUTING -j CONNMARK --restore-mark --nfmask 0xff --ctmask 0xff
iptables -t mangle -A PREROUTING -m mark ! --mark 0x0/0xff -j RETURN
iptables -t mangle -A PREROUTING -m mark --mark 0x0/0xff -j load-in
iptables -t mangle -A PREROUTING -j CONNMARK --save-mark --nfmask 0xff --ctmask 0xff
iptables -t mangle -A OUTPUT -j CONNMARK --restore-mark --nfmask 0xff --ctmask 0xff
iptables -t mangle -A OUTPUT -m mark ! --mark 0x0/0xff -j RETURN
iptables -t mangle -A OUTPUT -m mark --mark 0x0/0xff -j load-out
iptables -t mangle -A OUTPUT -j CONNMARK --save-mark --nfmask 0xff --ctmask 0xff
Teraz do łańcuchów load-in oraz load-out dodajemy po dwie
reguły:
iptables -t mangle -A load-in -m mark --mark 0x0/0xff -m statistic --mode random --probability 0.5 -j MARK --set-xmark 0x2/0xff
iptables -t mangle -A load-in -m mark --mark 0x0/0xff -j MARK --set-xmark 0x5/0xff
iptables -t mangle -A load-out -m mark --mark 0x0/0xff -m statistic --mode random --probability 0.5 -j MARK --set-xmark 0x2/0xff
iptables -t mangle -A load-out -m mark --mark 0x0/0xff -j MARK --set-xmark 0x5/0xff
Wszystkie powyższe reguły dotyczą pakietów, które mają w dalszym ciągu mark 0x0/0xff . Jeśli jakiś
pakiet zostanie oznaczony i ten mark zostanie nałożony na połączenie, to wtedy przez te powyższe
reguły nie będzie już on przechodził. Pierwsza z tych dwóch reguł wykorzystuje moduł
statistic. W tym przypadku korzystamy
z trybu losowego i przy pomocy --probability określamy, że 50% pakietów zostanie dopasowana do tej
reguły. Pakiety po dopasowaniu zostaną oznaczone markiem 0x2/0xff . Druga z reguł zaś oznaczy
pozostałe 50% pakietów, bo przecie w dalszym ciągu nie będą mieć żadnego oznaczenia.
Test łącza dwóch ISP
No to przyszła pora teraz przetestować, czy aby na pewno pakiety są rozsyłane do obu ISP. To co się nam powinno rzucić od razu w oczy, to oczywiście poprawa transferu. Można dla sprawdzenia odpalić klienta torrent i nim zapuścić kilka obrazów z linux'ami. Poniżej jest przykładowy wykres:

Przepustowość łącza jednego z moich ISP to 15/1 mbit/s. Drugie łącze to LTE i pod względem
przepustowości, to waha się znacznie w zależności od pory dnia. Widzimy wyżej na wykresie, że ogólny
transfer przekroczył te 15 mbit/s. Zatem oba łącza są w wykorzystaniu. Jeśli nadal nie wierzymy, że
pakiety idą przez obu ISP, to wystarczy zobaczyć statystyki interfejsów sieciowych w bmon :
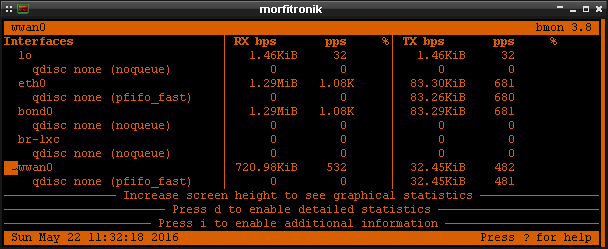
Tu już widzimy, że tej konkretnej chwili na interfejsie bond0 mamy transfer 1.29 MiB/s oraz, że na
interfejsie wwan0 mamy nieco ponad 720 KiB/s. Interfejs eth0 jest w tym przypadku bez znaczenia,
bo wchodzi on w skład bondingu. Efektywność podziału łącza możemy oszacować po podejrzeniu połączeń
w tablicy conntracka w pliku /proc/net/nf_conntrack :
# cat /proc/net/nf_conntrack | grep mark=5 |wc -l
788
# cat /proc/net/nf_conntrack | grep mark=2 |wc -l
654