Tworzenie kopii zapasowej linux'a z BorgBackup
Spis treści
Gdy chodzi o bezpieczeństwo danych przechowywanych na nośnikach pamięci masowych, takich jak dyski
twarde, to użytkownicy linux'a często piszą sobie skrypty shell'owe mające na celu przeprowadzić
backup całego nośnika lub też jego konkretnych plików/katalogów. Zwykle zaprzęgany jest do pracy
rsync , który bez problemu jest w stanie zsynchronizować zawartość dwóch folderów (źródłowego i
docelowego) i po tym procesie wołany jest także tar mający na celu skompresować pliki backup'u,
tak by zajmowały mniej miejsca. Nie mam nic do tego rozwiązania, bo sam też przez lata z niego
korzystałem ale ma ono całą masę wad. Przede wszystkim, ten mechanizm nie bierze pod uwagę zmian w
samych plikach, czyli tworzy kopię tego co mu się poda i w taki sposób mamy wiele paczek .tar.gz ,
które zajmują sporo miejsca. Kolejną sprawą jest brak zabezpieczenia przed nieuprawnionym dostępem
do plików kopii zapasowej, np. przy pomocy szyfrowania. W ten sposób trzeba posiłkować się
zewnętrznymi rozwiązaniami, np. pełne szyfrowanie dysku za sprawą LUKS/dm-crypt, co nie zawsze jest
możliwe i też bardzo komplikuje cały proces tworzenia kopii zapasowej, zwłaszcza na zewnętrznych
nośnikach czy zdalnych hostach w sieci. Ostatnio jednak trafiłem na narzędzie BorgBackup, które
to dość znacznie upraszcza cały proces tworzenia backup'u plików na linux, a takie cechy jak
szyfrowanie, kompresja i deduplikacja danych są w borg zaimplementowane standardowo. Postanowiłem
zatem zmigrować z mojego skryptowego systemu tworzenia kopii zapasowych na rzecz borg'a i spisać
przy okazji te użyteczniejsze informacje dotyczące posługiwania się tym narzędziem
Szyfrowanie, kompresja i deduplikacja danych
Każdy z nas prędzej czy później będzie musiał się zmierzyć z zadaniem tworzenia kopii zapasowych na swoim linux'ie. Gdy już ten czas nadejdzie, to dobrze jest podejść do kwestii backup'u danych w sposób przemyślany. Chodzi generalnie o to, by dane, które będą trafiać do kopii zapasowej, należycie zabezpieczyć oraz by nie zajmowały one nam niepotrzebnie zbyt dużo miejsca.
W przypadku lokalnych kopii zapasowych, tj. tworzonych na nośnikach, które podpinamy do swojego komputera (lub też są one w nim zamontowane na stałe), szyfrowanie danych można albo pozostawić oprogramowaniu od backup'u, albo też można zaszyfrować cały nośnik/partycję dysku. Jeśli nie wykorzystujemy pełnego szyfrowania dysku via LUKS/dm-crypt, to oprogramowanie tworzące kopię zapasową powinno szyfrowanie danych oferować. W przypadku, gdy szyfrujemy dysk twardy komputera, to możemy obejść się bez dodatkowego szyfrowania plików kopii zapasowych (brak korzyści przy narzucie związanym z obsługą dodatkowej warstwy szyfrowania). Oczywiście jeśli backup mamy zamiar przechowywać/tworzyć zdalnie i nie mamy całkowitej kontroli nad tą zdalną maszyną, to wtedy również potrzebna nam jest aplikacja, która ten szyfrowany backup potrafi zaoferować. Jeśli nasza appka nie oferuje szyfrowania danych kopii zapasowej, to trzeba ją wymienić na taką, która ten ficzer posiada.
Jeśli zaś chodzi o ograniczenie miejsca, które te kopie zapasowe będą zużywać, to standardowo kompresja danych może nam w tym zadaniu pomóc. Problem z kompresją jest jednak taki, że potrzebna jest spora moc obliczeniowa procesora, by te dane kompresować w procesie tworzenia backup'u, no i też trzeba będzie te pliki backup'u dekompresować, gdy tylko będziemy chcieli uzyskać dostęp do danych przechowywanych w kopii zapasowej. Może i wynikowy plik będzie zajmował 2 GiB zamiast 5 GiB ale często narzut związany z obsługą kompresji może nie być warty świeczki i tu do gry wchodzi deduplikacja danych.
Deduplikacja danych to taki bardzo efektywny mechanizm mający za zadanie wyeliminować powtarzające się dane. Jeśli teraz rozpatrzymy kwestię plików backup'u, to z pewnością dostrzeżemy, że każda taka kopia zapasowa w mniejszym lub większym stopniu zawiera całą masę plików, które nie zmieniły się w żaden sposób od momentu przeprowadzania ostatniego (czy też któregoś z poprzednich) procesu backupu. W ten sposób cały proces tworzenia kopii zapasowej się znacznie wydłuża, no i do tego jeszcze bardzo dużo miejsca jest marnowane na zapis tych samych informacji. Dlatego też oprogramowanie, które ma nam służyć do tworzenia kopii zapasowych, powinno być w stanie wykorzystywać mechanizm deduplikacji, by dość efektywnie ograniczyć miejsce zajmowane przez pliki backup'u.
Reasumując, potrzebne jest nam oprogramowanie, które działa bez problemu pod linux (i jest OpenSource), wspiera opcjonalne szyfrowanie z wykorzystaniem otwartych standardów (AES), posiada wsparcie dla kompresji danych (w tym ZSTD), oferuje mechanizm deduplikacji oraz zezwala na tworzenie zdalnych kopii zapasowych (via SSH). Te wszystkie cechy ma BorgBackup i dlatego właśnie postanowiłem napisać o nim ten krótki artykuł.
BorgBackup z opcją szyfrowania czy bez
Aplikacja BorgBackup jest standardowo dostępna w repozytorium Debiana w pakiecie borgbackup .
Nie powinno być zatem problemu z instalacją tego narzędzia, przynajmniej na tej dystrybucji linux'a.
Po ukończonym procesie instalacji musimy przygotować sobie jakiś katalog, w którym będą
przechowywane pliki backup'u -- takie repozytorium. Trzeba jednak zastanowić się czy potrzebne jest
nam szyfrowanie, czy możemy się bez niego obejść. Chodzi generalnie o to, że jak zdecydujemy się na
szyfrowanie zawartości kopi zapasowych, to w późniejszym czasie nie będziemy mogli tej opcji
zmienić i podobnie w drugą stronę, czyli jeśli nie wdrożymy szyfrowania przy inicjacji repozytorium,
to nie będziemy mogli go włączyć w późniejszym czasie.
W przypadku, gdy zdecydujemy się na opcję z szyfrowaniem, to podczas tworzenia repozytorium
pod kopie zapasowe trzeba będzie określić parametr --encryption . Jest kilka trybów szyfrowania,
z których możemy skorzystać. W zasadzie to ogromne znaczenie przy wyborze trybu szyfrowania ma
obecny w naszym komputerze procesor, a właściwie jego sprzętowe wsparcie dla określonych algorytmów
wykorzystywanych w procesie szyfrowania/uwierzytelniania danych. Dlatego trzeba zerknąć do
dokumentacji technicznej CPU i w oparciu o nią wybrać odpowiedni tryb szyfrowania. Do wyboru mamy
te poniższe:
none-- ten tryb nie zapewnia ani szyfrowania, ani uwierzytelniania danych. Korzystanie z niego nie jest też zalecane. W przypadku, gdy nie chcemy szyfrować danych backup'u, to lepiej jest wybrać opcję z samym tylko uwierzytelnieniem.authenticated-- ten tryb nie zapewnia szyfrowania ale oferuje za to uwierzytelnianie danych przy wykorzystaniu algorytmu HMAC-SHA256.repokeyorazkeyfile-- te dwa tryby zapewniają zarówno szyfrowanie, jak i uwierzytelnianie danych. Do szyfrowania będzie wykorzystywany algorytm AES-CTR-256, zaś do poświadczania autentyczności danych będzie użyty HMAC-SHA256 (konstrukcja EtM). Trybkeyfilekorzysta z pliku klucza, zaśrepokeyz hasła przy szyfrowaniu klucza głównego wykorzystywanego do szyfrowania danych w backup'ie.authenticated-blake2-- ten tryb jest dokładnie taki sam, co w przypadkuauthenticated. Różni się on jedynie zastosowaniem innego algorytmu do uwierzytelniania danych, tj. BLAKE2b-256.repokey-blake2orazkeyfile-blake2-- te same tryby, co w przypadkurepokeyikeyfileale wykorzystują one algorytm BLAKE2b-256 zamiast HMAC-SHA256 do ochrony integralności i autentyczności danych.
Wszystkie tryby szyfrowania wykorzystują algorytm AES do szyfrowania danych. Dlatego też dobrze jest posiadać procesor, który zapewnia sprzętowe wsparcie dla tych instrukcji. Algorytm BLAKE2b jest szybszy w stosunku do SHA256, no chyba, że procesor naszego komputera posiada wsparcie dla rozszerzeń SHA (często spotykane w nowszych maszynach).
Przygotowanie repozytorium backup'u
Jeśli nie chcemy szyfrować plików kopii zapasowych, np. nasz procesor nie ma odpowiednich rozszerzeń lub korzystamy z pełnego szyfrowania dysku, to repozytorium backup'u możemy zainicjować w poniższy sposób:
$ borg init --encryption=authenticated /media/Arti/backup-home
Enter new passphrase:
Jeśli zaś chcemy szyfrować zawartość backup'u, to korzystamy z poniższego polecenia:
$ borg init --encryption=repokey /media/Arti/backup-home
Enter new passphrase:
Przy inicjacji repozytorium backup'u zostaniemy poproszeni o ustawienie hasła (chyba, że podaliśmy
--encryption=none ). Hasło możemy określić jako puste, tj. nie zostanie zaszyfrowany materiał
klucza wykorzystywany m.in. do szyfrowania i uwierzytelniania danych backup'u. Ten materiał klucza
jest standardowo przechowywany w katalogu repozytorium w pliku config :
[repository]
version = 1
segments_per_dir = 1000
max_segment_size = 524288000
append_only = 0
storage_quota = 0
additional_free_space = 0
id = 96e20079d61d1604859bbd45fd6b67125a5c4a4c360f2a38b2cfb3f13e1d779c
key = hqlhbGdvcml0aG2mc2hhMjU2pGRhdGHaAN5sYZPUIOGRLTW0PUJa9AG0JgHt4+lFd7etY9
pM3jedOqQmst2BVb5U3zC1ubKIaJgRv0axgH1PJy55C58CMhCt9UR8rOwpJbnOscKtxd/7
B5G8/Ej2AiJ28mMqYfFCh9d/SQNsGCf+GDGlJIN2NI/1sDEJKs6vz7EuxQFwYV78fjcQKz
lHWjaXP9jyhJsFVmA4dPscxE6aoMIMddmNgStNzKFkvM+FpnK7wG/TANEUqQOAEINfBM+e
QRA1creMptiqyGpDb9UGijj45T5AD6InVCWaEHg6zb+Hj+Uhc1SkaGFzaNoAIKHcDx5l8h
kmjncVHDVfUeDmszVJvDP9uJ4WDpYa/IHHqml0ZXJhdGlvbnPOAAGGoKRzYWx02gAgRdVq
XgvHEiG1h5oKEnwfKd5asDsi5WsyMMnFBhIGPlWndmVyc2lvbgE=
Ten widoczny wyżej klucz można również wyeksportować do pliku przy pomocy borg key export w
formie takiej jak widać powyżej lub w formie bardziej czytelnej dla człowieka podając parametr
--paper
# borg key export /media/Arti/backup-home --paper
To restore key use borg key import --paper /path/to/repo
BORG PAPER KEY v1
id: 20 / 96e200 79d61d 160485 / 20ba3c 42513a - 2a
1: 86a961 6c676f 726974 686da6 736861 323536 - 14
2: a46461 7461da 00de6c 6193d4 20e191 2d35b4 - ff
3: 3d425a f401b4 2601ed e3e945 77b7ad 63da4c - 2f
4: de379d 3aa426 b2dd81 55be54 df30b5 b9b288 - fa
5: 689811 bf46b1 807d4f 272e79 0b9f02 3210ad - 7f
6: f5447c acec29 25b9ce b1c2ad c5dffb 0791bc - 98
7: fc48f6 022276 f2632a 61f142 87d77f 49036c - 94
8: 1827fe 1831a5 248376 348ff5 b03109 2aceaf - b6
9: cfb12e c50170 615efc 7e3710 2b3947 5a3697 - ed
10: 3fd8f2 849b05 566038 74fb1c c44e9a a0c20c - a9
11: 75d98d 812b4d cca164 bccf85 a672bb c06fd3 - 15
12: 00d114 a90380 10835f 04cf9e 411035 72b78c - 4b
13: a6d8aa c86a43 6fd506 8a38f8 e53e40 0fa227 - 36
14: 54259a 10783a cdbf87 8fe521 7354a4 686173 - 25
15: 68da00 20a1dc 0f1e65 f21926 8e7715 1c355f - f8
16: 51e0e6 b33549 bc33fd b89e16 0e961a fc81c7 - 35
17: aa6974 657261 74696f 6e73ce 000186 a0a473 - 15
18: 616c74 da0020 45d56a 5e0bc7 1221b5 879a0a - 02
19: 127c1f 29de5a b03b22 e56b32 30c9c5 061206 - 9e
20: 3e55a7 766572 73696f 6e01 - e5
Zarówno materiał klucza i hasło, które określimy przy tworzeniu repozytorium backup'u, będą
wymagane ilekroć będziemy chcieli wejść w interakcję z plikami backup'u (np. stworzyć nową kopię
zapasową czy podejrzeć pliki, które już w niej figurują). Ta wyeksportowana wyżej reprezentacja
klucza jest w formie zaszyfrowanej. Niemniej jednak, w pliku config figuruje odszyfrowana wersja
klucza. Jeśli ktoś by przechwycił plik config , to może i wejdzie on w posiadanie klucza ale w
dalszym ciągu będzie ten ktoś potrzebował hasła, by być w stanie zdeszyfrować dane backup'u. Hasło
zaś możemy zmienić w dowolnej chwili. Wystarczy skorzystać z poniższego polecenia:
$ borg key change-passphrase /media/Arti/backup-home
Enter passphrase for key /media/Arti/backup-home:
Enter new passphrase:
Enter same passphrase again:
W przypadku utraty materiału klucza lub gdy zapomnimy hasło, to nie będziemy w stanie odszyfrować
danych backup'u. Jeśli nie chcemy trzymać materiału klucza w pliku konfiguracyjnym repozytorium
borg'a, to możemy skorzystać z --encryption keyfile zamiast --encryption repokey . W takim
przypadku plik klucza zostanie zapisany w katalogu ~/.config/borg/keys/ .
Tworzenie kopii zapasowej pojedynczego katalogu
Mając przygotowane repozytorium kopii zapasowych, możemy przejść do utworzenia pierwszego pełnego
backup'u danych. Ten proces można przeprowadzić na kilka sposobów ale najprościej jest po prostu
skorzystać z listy zawierającej wzory dopasowań. Dlatego też na początku stwórzmy sobie taki plik
listy. W tym przykładzie będziemy chcieli utworzyć backup katalogu /home/ regularnego użytkownika
w systemie. Zatem tworzymy plik backup-home-file-list i dodajemy do niego poniższą treść:
R /home/morfik/
- /home/morfik/**/*Cache*/**
- /home/morfik/**/*cache*/**
- /home/morfik/Desktop/
- /home/morfik/Downloads/
+ /home/morfik/**
Linijka z R ma na celu ustawić punkt startowy backup'u, tj. ścieżkę która ma być brana pod uwagę
przy robieniu kopii zapasowej. Takich wpisów z R może być więcej ale, że my chcemy dokonać
backup'u katalogu /home/morfik/ , to określiliśmy właśnie tę ścieżkę. Następnie mamy szereg
wpisów poprzedzonych znakiem - . Mają one za zadanie wyłączyć z pliku backup'u zbędne z naszej
perspektywy pliki. Zapis /**/ oznacza co najmniej jeden katalog, zaś /** odpowiada za wszystkie
pliki w głębi struktury drzewa katalogów od tego konkretnego miejsca. Zatem te powyższe wpisy są w
stanie efektywnie pominąć ścieżki mające w nazwach Cache oraz cache , co dość znacznie
może zmniejszyć wagę wynikowego pliku backup'u. Dodatkowo, zarówno katalog Desktop/ jak i
Downloads/ (wraz z podkatalogami) nie będą brane pod uwagę przy tworzeniu kopii, bo zwykle
zawierają one niepotrzebne śmieci. Ostatnia linijka jest poprzedzona znakiem + , co oznacza, że
wszystkie pozostałe pliki znajdujące się w katalogu /home/morfik/ trzeba dodać do pliku backup'u.
Ten mechanizm działa na zasadzie pierwszego dopasowania, tj. gdybyśmy tę ostatnią regułę dali jako
pierwszą (zaraz po zapisie z R ), to wszystkie pliki z katalogu /home/morfik/ by zostały
uwzględnione w pliku backup'u, przez co pozostałe reguły byłyby bezużyteczne.
Gdy proces backup'u będziemy przeprowadzać po raz pierwszy, to będzie on dość wolny. Poniżej
przykład tworzenia kopii zapasowej katalogu /home/morfik/ , w którym to jest zgromadzonych około
11 GiB danych. Spora część danych to cache różnych aplikacji, zatem wynikowy plik backup'u powinien
być sporo mniejszy. Do stworzenia pliku backup'u korzystamy z borg create :
# borg create \
--compression zstd,15 \
--one-file-system \
--stats \
/media/Arti/backup-home::{now} \
--patterns-from /media/Arti/backup-home-file-list \
--progress
------------------------------------------------------------------------------
Archive name: 2020-10-06T18:02:46
Archive fingerprint: b075d2b4cc08b6e5946ac6b30b662a7045980f9bf9be5f0761a3e8f520681d10
Time (start): Tue, 2020-10-06 18:02:46
Time (end): Tue, 2020-10-06 18:11:18
Duration: 8 minutes 31.85 seconds
Number of files: 46144
Utilization of max. archive size: 0%
------------------------------------------------------------------------------
Original size Compressed size Deduplicated size
This archive: 4.47 GB 2.71 GB 2.66 GB
All archives: 4.47 GB 2.71 GB 2.66 GB
Unique chunks Total chunks
Chunk index: 45087 46838
------------------------------------------------------------------------------
Zanim przejdziemy do samych statystyk, dobrze jest powiedzieć parę słów na temat samego polecenia
użytego do stworzenia kopii zapasowej. Parametr --compression ma za zadanie ustawić rodzaj
kompresji. W tym przypadku korzystamy z ZSTD, którego stopień kompresji waha się od -5 do +20.
Im wyższa wartość, tym naturalnie bardziej te pliki będą skompresowane ale też bardziej będzie
obciążony procesor, przez co sam proces tworzenia kopii zapasowej będzie trwał sporo dłużej.
Wartość 15 wydaje się być w miarę rozsądna. By mieć pewność, że będziemy tworzyć kopię zapasową
jedynie katalogu /home/morfik/ , a nie innych podmontowanych w nim zasobów, to podajemy także
parametr --one-file-system . Określiliśmy też parametr --stats , by system nam wydrukował
statystyki po zakończeniu procesu (te widoczne wyżej). Następnie wskazaliśmy lokalizację
repozytorium kopii zapasowych (tego cośmy go utworzyli wcześniej), a po :: podana jest zaś nazwa
pliku backup'u. Ta nazwa może być dowolna ale jeśli nie chce nam się jej ciągle wpisywać to możemy
ustawić {now} i ta nazwa zostanie automatycznie dobrana na podstawie aktualnego czasu. Dalej mamy
parametr --patterns-from , który wskazuje na listę plików zawierającą wzory dopasowań. Jeśli
interesuje nas postęp prac, to możemy także podać --progress .
Jeśli zaś chodzi o statystyki, to jak mogliśmy zauważyć, cały proces trwał blisko 8,5 minuty.
Całkowita objętość plików, które zostały wzięte pod uwagę przy tworzeniu backup'u wyniosła 4.47 GB,
zaś po skompresowaniu 2.71 GB. Wartość w kolumnie Deduplicated size nas w zasadzie nie interesuje
w tej chwili, bo póki co mamy tylko jeden plik backup, więc zajmuje on w zasadzie tyle miejsca co
wszystkie pliki, które wchodzą w skład kopii zapasowej, choć jak widać wyżej, wartość w tej kolumnie
jest nieco mniejsza w stosunku do tej skompresowanej. Taka sytuacja może się zdarzyć, bo wyliczone
hash'e cząstkowe nawet tego samego pliku mogą mieć dokładnie tę samą wartość. Jeśli taka sytuacja
wystąpi, to wtedy borg taki kawałek pliku również podda deduplikacji i dlatego mamy 2.66 GB zamiast
2.71 GB.
Przeprowadzając w późniejszym czasie proces backup'u ponownie, otrzymamy nieco inne statystyki:
# borg create \
--compression zstd,15 \
--one-file-system \
--stats \
/media/Arti/backup-home::{now} \
--patterns-from /media/Arti/backup-home-file-list \
--progress
------------------------------------------------------------------------------
Archive name: 2020-10-06T18:25:46
Archive fingerprint: 8994dd6c9bf37f4361463f825cde5026adf4559277f3a729bfb04d074592acf8
Time (start): Tue, 2020-10-06 18:25:46
Time (end): Tue, 2020-10-06 18:26:12
Duration: 26.39 seconds
Number of files: 46144
Utilization of max. archive size: 0%
------------------------------------------------------------------------------
Original size Compressed size Deduplicated size
This archive: 4.47 GB 2.71 GB 22.33 MB
All archives: 8.94 GB 5.41 GB 2.69 GB
Unique chunks Total chunks
Chunk index: 45195 93676
------------------------------------------------------------------------------
Jak widzimy, czas utworzenia kopii zapasowej znacząco się obniżył do 26 sekund w stosunku do prawie 9 minut przy tworzeniu backup'u po raz pierwszy. Zatem już w tej chwili możemy odczuć jak działa deduplikacja danych -- bez niej znów musielibyśmy czekać prawie 9 minut na zakończenie się procesu tworzenia kopii zapasowej. Jeśli rzucimy okiem na rozmiar pliku tego backup'u, to ponownie mamy 4.47 GB, czyli objętość backup'owanych danych nie zmieniła się (łącznie oba archiwa mają 8.94 GB). Podobnie sprawa wygląda w przypadku wartości skompresowanych. Natomiast rozmiar po deduplikacji wynosi jedynie 22.33 MB. Zatem poprzedni plik backup'u zajmuje na dysku 2.66 GB, a ten nowy plik backupu tylko 22.33 MB. Łącznie daje to wartość 2.69 GB i dokładnie tyle danych jest zajmowanych na dysku, co jest dość sporą optymalizacją w stosunku zarówno do wartości bazowej (8.94 GB), czy nawet tej skompresowanej (5.41 GB). Te wartości będą jeszcze lepiej wyglądać, gdy tych kopii zapasowych będziemy mieć więcej.
Za każdym razem jak tylko będziemy tworzyć nową kopię zapasową katalogu /home/morfik/ , to tylko
te zmienione dane będą uwzględniane w pliku backup'u. Aktualną listę archiwów można podejrzeć przy
pomocy borg list :
# borg list /media/Arti/backup-home/
2020-10-06T18:02:46 Tue, 2020-10-06 18:02:46 [b075d2b4cc08b6e5946ac6b30b662a7045980f9bf9be5f0761a3e8f520681d10]
2020-10-06T18:25:46 Tue, 2020-10-06 18:25:46 [8994dd6c9bf37f4361463f825cde5026adf4559277f3a729bfb04d074592acf8]
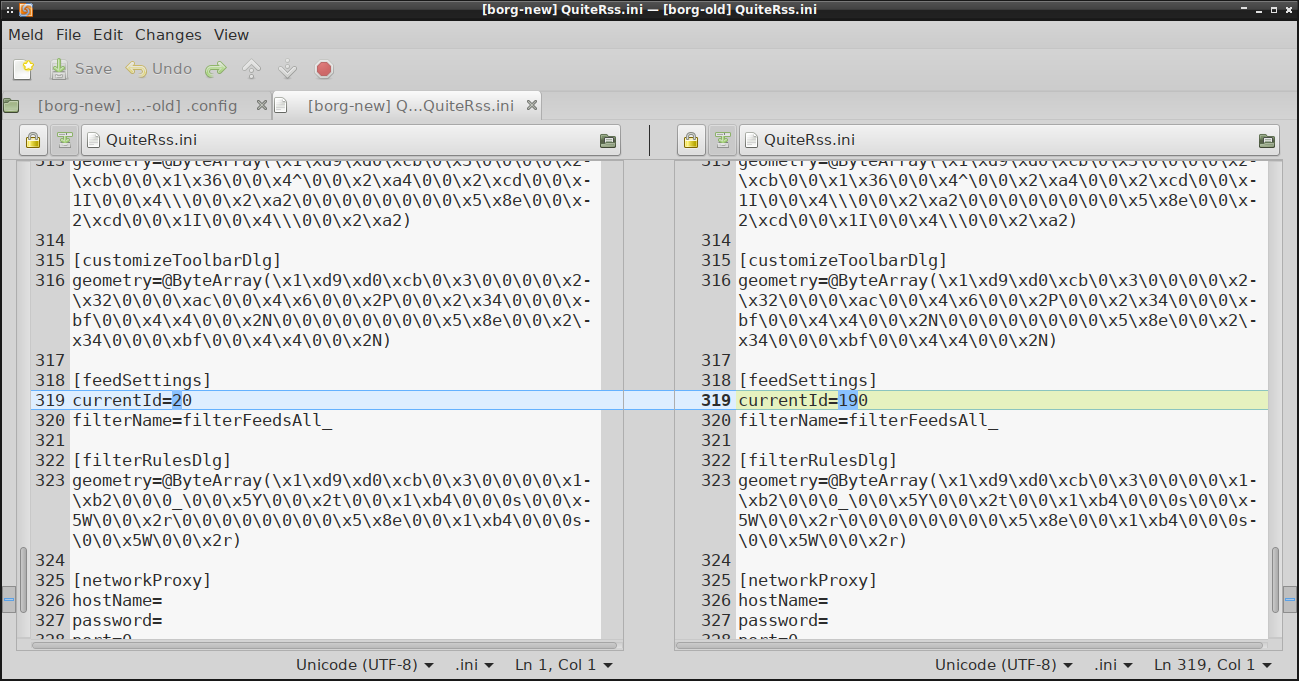
Różnice między tymi wersjami można podejrzeć korzystając z borg diff :
# borg diff /media/Arti/backup-home::2020-10-06T18:02:46 2020-10-06T18:25:46
+11.7 kB -11.7 kB home/morfik/.config/QuiteRss/QuiteRss.ini
+55.4 kB -55.4 kB home/morfik/.config/psi+/profiles/default/options.xml
...
To powyższe wyjście nie zwraca jednak informacji na temat różnicy w samych plikach, tj. nie damy
rady zobaczyć co dokładnie zostało zmienione. W przypadku plików binarnych i tak byśmy zbytnio nic
nie zrozumieli ale w katalogu domowym spora część plików to pliki tekstowe, które dla człowieka są
czytelne. Jeśli chcielibyśmy podejrzeć te zmiany, to możemy każdy z tych plików backup'u zamontować
jak zwykły nośnik (np. pendrive) przy pomocy borg mount :
# borg mount /media/Arti/backup-home::2020-10-06T18:02:46 /media/borg-old
# borg mount /media/Arti/backup-home::2020-10-06T18:25:46 /media/borg-new
# mount | grep -i borg
borgfs on /media/borg-old type fuse (ro,nosuid,nodev,relatime,user_id=0,group_id=0,default_permissions)
borgfs on /media/borg-new type fuse (ro,nosuid,nodev,relatime,user_id=0,group_id=0,default_permissions)
Po zamontowaniu plików backup'u, katalogi /media/borg-* można bez problemu przeglądać, choć nie
da rady w nich nic zapisywać (są zamontowane w trybie tylko do odczytu). Mając dwa katalogi możemy
np. przy pomocy meld podejrzeć różnice między nimi. Z racji, że katalog /home/ może być dość
rozbudowany, to zawsze możemy zawęzić diff do konkretnego podkatalogu czy pliku:
# meld /media/borg-*/home/morfik/.config/
I w ten sposób już powinniśmy bez problemu dociec co dokładnie zostało zmienione między tymi dwoma diff'owanymi backup'ami:
Jak skończymy sprawdzać zmiany, to nie zapomnijmy odmontować tych plików backup'u. Jeśli któryś z
tych plików będzie zamontowany, to borg odmówi przeprowadzania kolejnych kopii zapasowych i zwróci
poniższy błąd:
# borg create \
--compression zstd,15 \
--one-file-system \
--stats /media/Arti/backup-home::{now} \
--patterns-from /media/Kabi/backup-home-file-list \
--progress
Failed to create/acquire the lock /media/Arti/backup-home/lock (timeout).
By ten komunikat się nie pojawił, to w terminalu wpisujemy:
# borg umount /media/borg-*
Tworzenie kopii zapasowej wielu katalogów
Ten powyżej opisany przykład jest bardzo prosty, bo dotyczy w zasadzie jednego katalogu. Co jednak
w przypadku, gdy chcemy tych katalogów w pojedynczym pliku backup'u uwzględnić więcej. Przykładowo
mamy listę pojedynczych plików z katalogów /etc/ oraz /home/ . W takiej sytuacji postępujemy
bardzo podobnie do opisanego wcześniej przykładu, tj. tworzymy plik listy z wzorami dopasowań o
poniższej zawartości:
R /etc/
- /etc/**/*Cache*/**
- /etc/**/*cache*/**
+ /etc/apparmor.d/
+ /etc/apt/listchanges.conf
- /etc/**
R /home/morfik/
- /home/morfik/**/*Cache*/**
- /home/morfik/**/*cache*/**
+ /home/morfik/.bash_history
+ /home/morfik/.bashrc
+ /home/morfik/.config/autostart/
+ /home/morfik/.config/compton.conf
- /home/morfik/**
Przy pomocy R wskazujemy tym razem dwie ścieżki zamiast jednej. Pliki i katalogi, które
zamierzamy dołączyć do kopii zapasowej poprzedzamy znakiem + , zaś te które chcemy pominąć
znakiem - . Reguły ze znakiem - dajemy na początek. Wyjątkiem jest ostatnia reguła w każdej z
tych dwóch zwrotek. Jej zadaniem jest pominięcie pozostałych plików w tych katalogach. Zatem tylko
te pliki, które mają znak + będą figurować w pliku backup'u.
Cykliczny backup przy wykorzystaniu cron'a
Z racji, że przestrzeń pod kopie zapasowe tworzone przez borg'a nie kurczy się w tak szybkim tempie
jak by to miało miejsce w przypadku rsync/tar , to możemy tych kopii tworzyć więcej. Oczywiście
takie manualne tworzenie backup'u można zautomatyzować przy pomocy cron . W tym celu wystarczy
dodać tę poniższą linijkę do tablicy cron'a (via crontab -e ):
30 17 * * 6 borg create --compression zstd,15 --one-file-system --stats /media/Arti/backup-home::{now} --patterns-from /media/Arti/backup-home-file-list
W ten sposób w soboty o 17:30 ten backup będzie przeprowadzany automatycznie. Możemy także
nadać najniższy priorytet temu zadaniu przy pomocy nice -n 19 i ionice -c 3 , tak by zbytnio
nie odczuwać spowolnienia pracy systemu podczas procesu tworzenia kopii zapasowych.
Maksymalna ilość plików backup'u
W przypadku automatyzacji procesu tworzenia kopii zapasowych trzeba liczyć się z faktem, że ani się
nie obejrzymy, a będziemy mieli tych kopii bardzo dużo. Przydałoby się usuwać stare backup'y
automatycznie i do tego celu służy polecenie borg prune. Pamiętajmy jednak, że korzystanie z
tego polecenia może nieść ze sobą poważne konsekwencje, bo pliki kopii zapasowych mogą zostać
trwale usunięte. Dlatego też do poniższych przykładów dobrze jest dodać parametry --list oraz
--dry-run , by podejrzeć ewentualne zmiany i mieć pewność, że zostaną usunięte tylko te pliki
backup'u, które faktycznie chcemy usunąć.
Usuwanie kopii zapasowych starszych niż 30 dni
Możemy np. ustawić limit czasu, tak by starsze kopie zapasowe były usuwane, gdy tylko ten czas
zostanie przekroczony. Dla przykładu, jeśli podamy w parametrze --keep-within wartość 30d , to
tylko te backup'y utworzone w okresie ostatnich 30 dni nie zostaną usunięte. Jeśli backup'y będą
starsze niż ten okres czasu, to wtedy system się ich pozbędzie. Zatem potrzebne nam będzie to
poniższe polecenie:
# borg prune --list --stats --keep-within 30d /media/Arti/backup-home
Ustawienie limitu jednej kopii na dzień
Czasami kopie zapasowe mogą być tworzone w liczbie kilku-kilkunastu na dzień. W ten sposób to powyższe rozwiązanie niekoniecznie może okazać się optymalnym. Tych kopii zapasowych przez jeden miesiąc mogłoby nam się uzbierać bardzo dużo, co z kolei przełożyłoby się na sporą ilość zajmowanego przez pliki backup'u miejsca. Możemy za to oczyścić kopie zapasowe w oparciu o ostatni backup danego dnia, przykładowo:
# borg prune --list --stats --keep-daily 30 /media/Arti/backup-home
Widoczny wyżej --keep-daily sprawia, że maksymalnie 30 backup'ów będzie mogło zostać zachowanych
(po jednym na każdy dzień). Jeśli tych kopii zapasowych w konkretnym dniu zrobimy więcej, to te
starsze pliki z danego dnia zostaną usunięte. Możemy także skorzystać z --keep-minutely ,
--keep-hourly , --keep-weekly , --keep-monthly czy --keep-yearly , by nieco lepiej sobie
stuningować, które pliki powinny zostać zachowane, a które usunięte.
Usuwanie kopii zapasowych po przekroczeniu określonej ich liczby
W przypadku, gdy rzadko przeprowadzamy proces tworzenia kopii zapasowych, lepszym rozwiązaniem przy
czyszczeniu repozytorium może okazać się określenie konkretnej liczby plików backup'u, które
powinny zostać zachowane, np. 20 ostatnich. Możemy taki stan rzeczy osiągnąć korzystając z
--keep-last , przykładowo:
# borg prune --list --stats --keep-last 20 /media/Arti/backup-home
Ustawienia mieszane
Sporą część parametrów konfigurujących czyszczenia plików backup'u można łączyć. W ten sposób możemy dość dokładnie wyprofilować proces czyszczenia kopii zapasowych, przykładowo:
# borg prune --list --stats --keep-daily 7 --keep-weekly=4 /media/Arti/backup-home
To powyższe polecenie wyczyści pliki backup'u zostawiając w zasadzie 11 kopii zapasowych, czyli
--keep-daily 7 zostawi po jednej kopii z ostatnich 7 dni, a --keep-weekly=4 zostawi po jednej
kopii z ostatnich 4 tygodni. W rezultacie będziemy mieć 11 kopii zapasowych. Warto tutaj jeszcze
zaznaczyć, że jeśli w danym dniu brakuje backup'u, to zostanie zachowany w jego miejscu starszy
backup, tak by liczba plików kopii zapasowych się zgadzała. Dodatkowo kolejność reguł ma znaczenie.
Jeśli backup z danego dnia zostanie dopasowany do pierwszej reguły, to automatycznie ten plik
backup'u wypada z drugiej reguły (i kolejnych jeśli są określone). Dlatego tych plików jest 11, a
nie 10.
Odzyskiwanie miejsca na dysku po skasowaniu starych backup'ów
Warto tutaj zaznaczyć, że wywołanie polecenia borg prune nie odzyska nam miejsca na dysku. O ile
przy wyświetlaniu listy backup'ów będziemy mieli mniej pozycji, to ilość zajmowanego przez nie
miejsca będzie dokładnie taka sama co przed czyszczeniem repozytorium. By odzyskać to miejsce,
trzeba posłużyć się poleceniem borg compact , które wykonujemy na katalogu z konkretnym
repozytorium, przykładowo:
# borg compact --progress --verbose /media/Arti/backup-home
compaction freed about 34.86 GB repository space.
Wyżej mamy informację, że odzyskano prawie 35GiB miejsca na dysku i faktycznie po wydaniu tego
polecenia system jest w stanie te dodatkowe gigabajty w końcu ujrzeć. Dlatego też raz na jakiś czas
przyda się skorzystać z borg compact .
Zdalny backup via SSH
W tym artykule skupiliśmy się głównie na tworzeniu lokalnych kopii zapasowych ale borg jest w stanie również działać w konfiguracji klient-server. Niestety nie mam jak obecnie przetestować tej konfiguracji, bo na zdalnej maszynie trzeba również by zainstalować borg'a i odpowiednio skonfigurować połączenie SSH. Być może w późniejszym czasie uda mi się to zadanie zrealizować. Tak czy inaczej dobrze wiedzieć, że borg taką opcję tworzenia zdalnych kopii zapasowych via SSH oferuje.
Warto też tutaj wspomnieć, że szyfrowanie zawsze przeprowadzane jest lokalnie, tj. wszystkie pliki backup'u przechowywane zdalnie są chronione przed ewentualną kompromitacją serwera. Oczywiście w dalszym ciągu ktoś te pliki z serwera będzie w stanie skasować ale grunt, że nigdy nie pozna nich zawartości.
Podsumowanie
BorgBuckup jest bardzo prostym narzędziem do tworzenia kopii zapasowych w środowisku linux'owym.
Pewnie spora część użytkowników tego systemu będzie obstawać przy zdaniu, że rsync i tar
powinny w zupełności wystarczyć ale jak można było zobaczyć na żywym przykładzie, deduplikacja
danych znacząco redukuje ilość potrzebnej przestrzeni dyskowej na pliki backup'u. Bez szyfrowania
można się obejść, zwłaszcza w przypadku lokalnych kopii zapasowych, przy założeniu, że
wykorzystujemy pełne szyfrowanie dysku. Proces tworzenia kopii zapasowych możemy w pełni
zautomatyzować przy pomocy cron , a biorąc pod uwagę korzyści płynące z deduplikacji danych, te
backup'y możemy robić częściej minimalizując przy tym ryzyko utraty danych, jednocześnie
upraszczając znacznie zarządzanie plikami backup'u. Niewątpliwą zaletą jest możliwość montowania
pliku backup'u niczym zwykły nośnik cd/dvd/pendrive, przez co nie musimy takiej paczki pierw
wypakowywać, co nam zaoszczędza czas, no i też miejsce na dysku. Gdyby jednak ktoś się upierał przy
formacie .tar.gz , to warto w tym miejscu jeszcze dodać, że taki pojedynczy plik backup'u można
wyeksportować z repozytorium borg'a do paczki .tar.gz , także gdy zajdzie taka potrzeba, to
naturalnie paczki tar.gz również można sobie będzie bez problemu zrobić.