Sparse files (rozrzedzone pliki)
Spis treści
Każdy system plików opiera się na blokach danych. Standardowo taki blok w systemie plików EXT4 ma 4 KiB (8 x 512 bajtów). Za każdym razem, gdy tworzymy jakiś plik na dysku, alokowana jest pewna część bloków, na których ten plik ma zostać zapisany. Te większe pliki rezerwują więcej bloków, choć nie zawsze są to bloki ciągłe. W taki sposób, plik o rozmiarze 10 GiB okupowałby dokładnie tyle miejsca na dysku ile sam waży. Niemniej jednak są pewne pliki, które może i ważą te 10 GiB ale system plików postrzega je tak jakby miały 100 MiB czy 200 MiB, w zależności od tego ile "faktycznie" taki plik zajmuje miejsca. Jak to możliwe? Pliki, o których mowa, to tzw. "rozrzedzone pliki" (Sparse files). Taki plik składa się z szeregu bloków pustych (mających same zera), których nie trzeba zapisywać na dysk. Zamiast tego, można jedynie zapisać metadane w strykturze systemu plików, które będą opisywać te puste bloki. Poniższy artykuł ma na celu pokazać do czego takie pliki sparse mogą nam się przydać i jak z nich korzystać.
Wady i zalety plików sparse
Pliki sparse dają nam możliwość bardzo szybkiego tworzenia plików o sporych rozmiarach. Stworzenie
10 GiB czy 100 GiB pliku odbywa się w ułamku sekundy. Dla porównania, korzystając z dd i zapisując
plik samymi zerami, utworzenie go zajęłoby kilka czy kilkanaście minut. Do tego doszłaby także 100%
utylizacja procesora na czas tworzenia tego pliku. W przypadku rozrzedzonych plików zapisujemy
jedynie kilka bajtów w strukturze systemu plików. W ten sposób możemy tworzyć pliki, które są
większe niż rozmiar całej partycji. Problem zaczyna się w momencie, gdy taki plik zaczniemy
wypełniać faktycznymi danymi. Spójrzmy sobie na ten obrazek poniżej
(źródło):
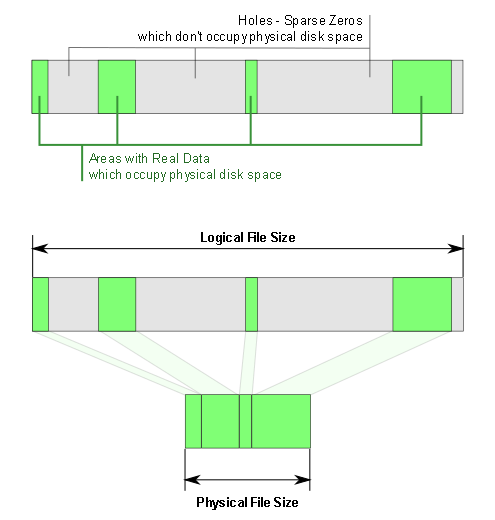
Zielonym kolorem oznaczono faktyczne dane w pliku. Szarym kolorem zaś zaznaczono puste bloki, które
nie są zapisane na dysku. Gdy teraz do takiego pliku będziemy chcieli dodać kolejną porcję danych, w
strukturze systemu plików zostaną opisane któreś z tych pozostałych pustych bloków widocznych
powyżej. Niemniej jednak, oznacza to alokację tych bloków i jest ogromne prawdopodobieństwo, że
bloki w tym pliki stracą ciągłość. W efekcie może dojść do poważnej fragmentacji takiego pliku z
biegiem czasu. Oczywiście, jeśli korzystamy z dysków SSD, to fragmentacja, nawet dość znaczna, nie
stanowi dla nas problemu. Trzeba jednak liczyć się z nią w przypadku talerzowych dysków twardych.
Zawsze też można co jakiś czas przeprowadzić defragmentację plików przy pomocy e4defrag .
Jak na linux'ie stworzyć plik sparse
Są co najmniej dwie metody, które umożliwiają tworzenie plików rozrzedzonych. Pierwszym z nich jest
skorzystanie z dd . W tym przypadku nie podajemy parametru if=/dev/zero oraz inaczej określamy
wartości w opcjach bs i count . Dodajemy także parametr seek i to w oparciu o niego w
połączeniu z bs będzie wyliczana wielkość wynikowego pliku. Poniżej jest przykładowe polecenie
tworzące plik sparse o rozmiarze 10 GiB:
# dd of=sparse-file bs=10M seek=1024 count=0
Drugą opcją na stworzenie pliku sparse jest skorzystanie z narzędzia truncate dostarczanego w
pakiecie coreutils . W tym przypadku składnia polecenia jest nieco inna i sporo prostsza:
# truncate -s 10G sparse-file
W obu tych powyższych przypadkach powinniśmy w mgnieniu oka uzyskać plik o rozmiarze 10 GiB. Poniżej
zostało to ukazane w ls oraz du :
# ls -al sparse-file
-rw-r--r-- 1 root root 10G 2016-06-02 14:05:25 sparse-file
# du -h --apparent-size sparse-file
10G sparse-file
Jak odróżnić pliki sparse od zwykłych plików
Jeśli popatrzymy na statystyki wolnego miejsca systemu plików, w którym ten rozrzedzony plik został
utworzony, to nie zanotujemy żadnej różnicy. Nasuwa się zatem pytanie, jak odróżnić pliki typu
sparse od normalnych plików? Jakby nie patrzeć, wszystkie menadżery plików jak i narzędzia będące w
stanie odczytać rozmiar plików zwrócą nam wyniki podobne do tego jaki otrzymaliśmy wyżej w przypadku
poleceń ls i du .
Część narzędzi potrafiących rozpoznawać pliki rozrzedzone ma dodatkowy przełącznik, który można
wykorzystać do wykrycia takich plików. Dla przykładu weźmy sobie ten ls . On dysponuje opcją
-s , która jest nam w stanie wskazać faktyczny rozmiar utworzonego powyżej pliku:
# ls -als sparse-file
0 -rw-r--r-- 1 root root 10G 2016-06-02 14:05:25 sparse-file
W du również jesteśmy w stanie podejrzeć faktyczny rozmiar tego pliku:
# du -h sparse-file
0 sparse-file
Widzimy zatem, że ten plik składa się z pustych bloków póki co, których nie trzeba zapisywać na dysk.
Tworzenie systemu plików dla plików sparse
Jednym z zastosowań, do których możemy wykorzystać taki plik rozrzedzony jest stworzenie na nim systemu plików. W ten sposób uzyskamy zwykły kontener na pliki, który będzie w stanie się rozrastać. Taki kontener może zostać wykorzystany do dowolnego celu. System plików tworzymy w poniższy sposób:
# mkfs.ext4 -m 0 -L obraz ./sparse-file
...
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632
...
Opcja -m ustawia procent zarezerwowanego miejsca dla użytkownika root. Natomiast -L to etykieta
systemu plików. Jako, że struktura systemu plików sama w sobie trochę waży, to zobaczmy ile w
obecnej chwili zajmuje nasz rozrzedzony plik:
# ls -als sparse-file
4.2M -rw-r--r-- 1 root root 10G 2016-06-02 14:05:25 sparse-file
Wcześniej było 0 bajtów, teraz już mamy nieco ponad 4 MiB. Podglądając strukturę tego pliku, to możemy zauważyć, że plik został pofragmentowany:
# filefrag -v /media/Grafi/sparse-file
Filesystem type is: ef53
File size of /media/Grafi/sparse-file is 10737418240 (2621440 blocks of 4096 bytes)
ext: logical_offset: physical_offset: length: expected: flags:
0: 0.. 1027: 1507328.. 1508355: 1028:
1: 1043.. 1043: 1508371.. 1508371: 1:
2: 1059.. 1059: 1508387.. 1508387: 1:
3: 9251.. 9256: 1510435.. 1510440: 6: 1516579:
4: 32768.. 32770: 1511424.. 1511426: 3: 1533952:
5: 98304.. 98306: 1513472.. 1513474: 3: 1576960:
6: 163840.. 163842: 1515520.. 1515522: 3: 1579008:
7: 229376.. 229378: 1517568.. 1517570: 3: 1581056:
8: 294912.. 294914: 1519616.. 1519618: 3: 1583104:
9: 524288.. 524288: 1521664.. 1521664: 1: 1748992:
10: 819200.. 819202: 1523712.. 1523714: 3: 1816576:
11: 884736.. 884738: 1525760.. 1525762: 3: 1589248:
12: 1048576.. 1048577: 1527808.. 1527809: 2: 1689600:
13: 1081344.. 1081344: 1529856.. 1529856: 1: 1560576:
14: 1572864.. 1572864: 1531904.. 1531904: 1: 2021376:
15: 1605632.. 1605634: 1533952.. 1533954: 3: 1564672:
16: 2097152.. 2097152: 1536000.. 1536000: 1: 2025472:
17: 2097167.. 2097167: 1536015.. 1536015: 1: last
/media/Grafi/sparse-file: 15 extents found
Zatem mamy niby plik o faktycznym rozmiarze 4,2 MiB ale ma on 15 części. Plik został pokrojony za
sprawą metadanych systemu plików. Jeśli się przyjrzymy uważnie, to w kolumnie logical_offset
możemy dostrzec numery zapasowych sektorów głównego bloku systemu plików
(te wpisane w mkfs.ext4 ). Im większy jest system plików, tym więcej jest kopi superbloka i
więcej metadanych potrzebnych do opisu jego zawartości.
Gdybyśmy mieli zamiast tego pliku sparse zwykły plik wypełniony zerami i chcieli utworzyć na nim
system plików, to on również by został tak pofragmentowany. Na dobrą sprawę będzie wyglądał tak samo
jak ten wyżej. Przynajmniej w standardowej konfiguracji tworzenia systemu plików, tj. gdy tworzy się
system plików bez opcji -E nodiscard . Jeśli się ją zastosuje, to wszystkie zera takiego pliku
będą widoczne po stworzeniu systemu plików i taki kontener nie będzie ulegał fragmentacji, gdy
będziemy go wypełniać jakąś zawartością. Natomiast problem z tymi plikami sparse jest taki, że
tutaj nie mamy do dyspozycji zer. Dlatego te pliki będą się tak fragmenteować i praktycznie każdy
nowy plik wgrany do kontenera sparse doda kolejny nieciągły zakres, czyli pofragmentuje kontener. W
przypadku zwykłego systemu plików na partycji, to nie stanowi problemu ale, gdy w grę wchodzi jeden
system plików opisany w innym systemie plików, to już tego typu mechanizm jest iście niewydolny
właśnie przez fragmentację, której moim zdaniem się nie da uniknąć w przypadku plików sparse.
Dlatego też zastanówmy się, czy aby na pewno potrzebujemy tych plików.
Tak czy inaczej, stworzony w ten sposób system plików możemy zamontować przy pomocy urządzeń loop i użytkować jak każdą inną partycję dysku twardego:
# mount -o loop sparse-file /mnt/
Zapiszmy teraz trochę danych w tym rozrzedzonym pliku (w katalogu /mnt/ ) i sprawdźmy co się
stanie:
# ls -als sparse-file
2.1G -rw-r--r-- 1 root root 10G 2016-06-02 14:21:38 sparse-file
# filefrag /media/Grafi/sparse-file
/media/Grafi/sparse-file: 108 extents found
Można było się tego spodziewać. Zapisaliśmy 2,1 GiB danych i plik ma ponad 100 nieciągłych zakresów. Powyższy plik został umieszczony na partycji, która była praktycznie pusta. Pomimo tego faktu, plik uległ sporej fragmentacji.
Obsługa plików sparse przez aplikacje
Rozrzedzone pliki wymagają specjalnego traktowania. Cześć aplikacji nie potrafi rozpoznać tego typu
plików i przy ich kopiowaniu czy pakowaniu przerabia te rozrzedzone pliki na zwykłe pliki. Niemniej
jednak, spora część programów w linux'ie posiada wsparcie dla plików sparse i dysponuje odpowiednimi
opcjami, które można podać przy wywoływaniu polecenia. Przykładem może być tworzenie paczki za
pomocą tar czy kopiowanie plików z użyciem cp . Nawet rsync posiada stosowny parametr.
Poniżej przykładowe polecenia:
# tar czpvfS file file.tar.gz
# rsync --sparse file another-file
# cp --sparse=always file another-file
Przerabianie zwykłych plików na sparse
W przypadku, gdy mamy do czynienia z plikami, które zawierają szereg pustych bloków, to nic nie stoi
na przeszkodzie, by przerobić te pliki na pliki sparse. Przykładem mogą być obrazy partycji dysku,
które robimy w formie cotygodniowego backupu. Trzeba tylko pamiętać, że wolne miejsce na takiej
partycji nie oznacza automatycznie, że tam znajdują się same zera. Zawsze możemy zapisać wolną
przestrzeń zerami przy pomocy dd . Jeśli mamy już utworzony obraz i chcielibyśmy go nieco
odchudzić, to możemy wykopać w nim kilka dziur przy pomocy fallocate z pakietu util-linux .
Poniżej jest plik 10 GiB, którego struktura zawiera całą masę bloków pustych. Statystyki w ls tego
pliku wyglądają następująco:
# ls -als file.img
9.7G -rw-r--r-- 1 root root 10G 2016-06-02 14:59:07 file.img
Widzimy, że ten plik faktycznie zajmuje 9,7 GiB. Sporą część tego miejsca możemy odzyskać wpisując w terminalu to poniższe polecenie:
# fallocate -v -d file.img
file.img: 3.2 GiB (3415543808 bytes) converted to sparse holes.
# ls -als file.img
6.5G -rw-r--r-- 1 root root 10G 2016-06-02 15:04:40 file.img
W taki oto sposób odzyskaliśmy 3,2 GiB przestrzeni na dysku. Oczywiście, nie zalecałbym tego typu operacji na wszystkich plikach zgromadzonych na dysku. Niemniej jednak, w przypadku obrazów partycji, które leżą odłogiem, możemy im taki zabieg fundnąć bez wahania.
Tworzenie rozrzedzonego backupu dysku
Jeśli dopiero zamierzamy tworzyć backup dysku czy partycji, to istnieje nieco prostsza metoda
oszczędzenia miejsca. Zamiast tworzyć backup przy pomocy dd i później kopać w nim dziury przez
fallocate , można od razu zrobić obraz rozrzedzony. Do tego celu jednak będzie nam potrzebne
narzędzie ddrescue dostępne w pakiecie gddrescue . Kopię partycji zaś wykonujemy w poniższy
sposób:
# ddrescue -S -b 8Mi /dev/sda2 /mnt/2016-06-02-sda2
# ls -als 2016-06-02-sda2
241M -rw-r--r-- 1 root root 1.0G 2016-06-02 15:40:13 2016-06-02-sda2