Jak odzyskać usunięte z dysku pliki
Spis treści
Całkowite usuwanie plików (shred) jak i
zerowanie całych nośników ma na celu
nieodwracalne zniszczenie danych. W tych podlinkowanych artykułach próbowaliśmy zatrzeć ślady po
skasowanych plikach. W tym wpisie zaś prześledzimy sobie co tak naprawdę się dzieje po utworzeniu i
skasowaniu pliku, a także spróbujemy odzyskać te z nich, które już nie istnieją w naszym systemie.
Ten artykuł będzie dotyczył jedynie systemu plików z rodziny ext , głównie ext4 .
Czy usunięcie pliku niszczy dane?
By być w stanie zapisywać informacje na jakimkolwiek nośniku danych, potrzebny jest odpowiedni system plików, a tych jest oczywiście cała masa. System plików, to metadane opisujące zbiory binarnych jedynek i zer, które my rozumiemy pod nazwą pliku lub katalogu (katalog to też plik). W przypadku gdy system nie ma informacji o pewnym interesującym nas pliku, znaczy to tylko tyle, że ten plik zwyczajnie nie jest opisany w strukturze systemu plików. Oczywiście w takim przypadku nie możemy zwyczajnie uzyskać do niego dostępu, no bo niby w jaki sposób mielibyśmy to zrobić? Pod tym linkiem znajduje się ciekawe doświadczenie, które postanowiłem odtworzyć na mojej maszynie. Chodzi generalnie o zademonstrowanie, że usunięcie pliku z dysku nie niszczy danych oraz, że jesteśmy w stanie takie pliki bez problemu przywrócić. Stwórzmy sobie przykładowy plik tekstowy i dodajmy do niego jakąś treść:
# echo "Przykladowy plik tekstowy" > plik-tekstowy
Spróbujmy dowiedzieć się czego więcej o tym pliku. Potrzebujemy zatem ustalić najpierw numer
i-węzła (i-node) odpowiedzialnego za ten plik.
Możemy to zrobić za pomocą ls . Mając numer i-węzła, informacje o nim możemy uzyskać z istat
oraz z fsstat , przykładowo:
# ls -li plik-tekstowy
262882 -rw-r--r-- 1 root root 26 2015-11-25 14:30:10 plik-tekstowy
# istat /dev/mapper/debian_laptop-root 262882
inode: 262882
Allocated
Group: 32
Generation Id: 582150946
uid / gid: 0 / 0
mode: rrw-r--r--
Flags: Extents,
size: 26
num of links: 1
Inode Times:
Accessed: 2015-11-25 14:30:10.762195266 (CET)
File Modified: 2015-11-25 14:30:10.762195266 (CET)
Inode Modified: 2015-11-25 14:30:10.762195266 (CET)
File Created: 2015-11-25 14:30:10.762195266 (CET)
Direct Blocks:
1094714
# fsstat /dev/mapper/debian_laptop-root
...
Group: 32:
Block Group Flags: [INODE_ZEROED]
Inode Range: 262145 - 270336
Block Range: 1048576 - 1081343
Layout:
Data bitmap: 1048576 - 1048576
Inode bitmap: 1048592 - 1048592
Inode Table: 1048608 - 1049119
Data Blocks: 1056800 - 1081343
Free Inodes: 7 (0%)
Free Blocks: 3821 (11%)
Total Directories: 1193
Stored Checksum: 0x632F
...
W systemie plików ext4 , i-węzły mają rozmiar 256 bajtów, co daje 16 i-węzłów na jeden 4KiB blok.
Zatem, w którym dokładnie bloku znajduje się szukany przez nas i-węzeł? Zakres i-węzłów tej grupy
zaczyna się na 262145 , zaś w ls został podany numerek 262882 . Odejmujemy pierwszą wartość od
drugiej: 262882-262145=737. Dzielimy teraz tę wartość przez 16 i otrzymujemy 46.0625. Zatem, ten
i-węzeł znajduje się gdzieś w bloku 46 w tablicy i-węzłów. Jeśli pierwszy i-węzeł w tej tablicy ma
numer 1048608, to szukany i-węzeł znajduje się gdzieś w między 256-512 bajtami bloku 1048654. Chodzi
o to, że blok może mieć 16 części po 256 bajtów. Jako, że dzielenie 737/16 nie dało nam liczby
całkowitej, oznacza to, że szukany i-węzeł jest gdzieś w środku tego bloku. Gdzie dokładnie, to
można ustalić dzieląc 1/16. Każda z tych szesnastu części odpowiada 0.0625, zatem wiemy, że są to
bajty 256-512.
Zróbmy sobie zatem kopię całego bloku 1048654:
# blkcat /dev/mapper/debian_laptop-root 1048654 > blk-1048654
# ls -al | grep blk
-rw-r--r-- 1 root root 4.0K 2015-11-25 15:12:17 blk-1048654
Musimy poddać ten plik analizie w edytorze hexalnym, np. w
wxhexeditor, który jest standardowo dostępny w repozytoriach debiana.
Każdy i-węzeł rozpoczyna się od A4 81 . Wiemy także, że rozmiar takiego i-węzła to 256 bajtów,
zatem ładujemy plik i oszukujemy tę wspomnianą wartość. Pamiętajmy, że interesuje nas drugi i-węzeł,
a nie pierwszy. Zaznaczony niżej fragment odpowiada rozmiarowi pliku:
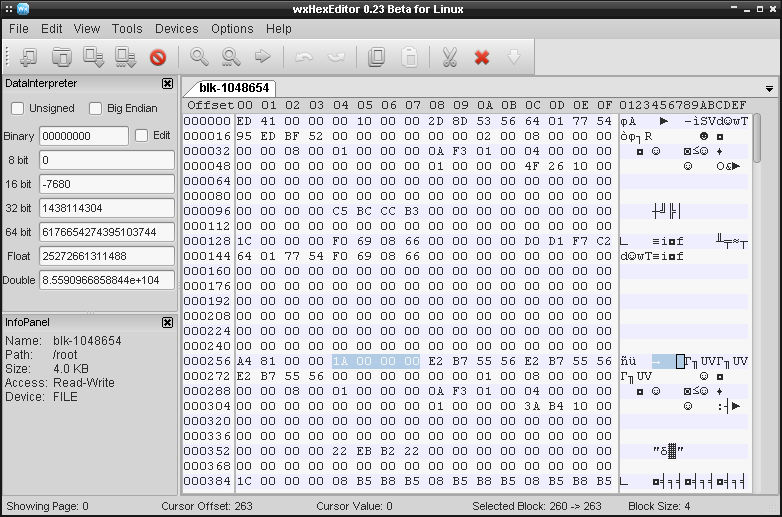
W tym przypadku jest to 1A co oznacza liczbę 26 i jeśli wrócimy wyżej do logu ls , to faktycznie
nasz plik tekstowy ma 26 bajtów.
Jako, że system plików ext4 używa extent'ów, to 60 bajtów na
pozycji od 40-99 włącznie (licząc w stosunku do konkretnego i-węzła) przechowuje informacje o
zakresach bloków:
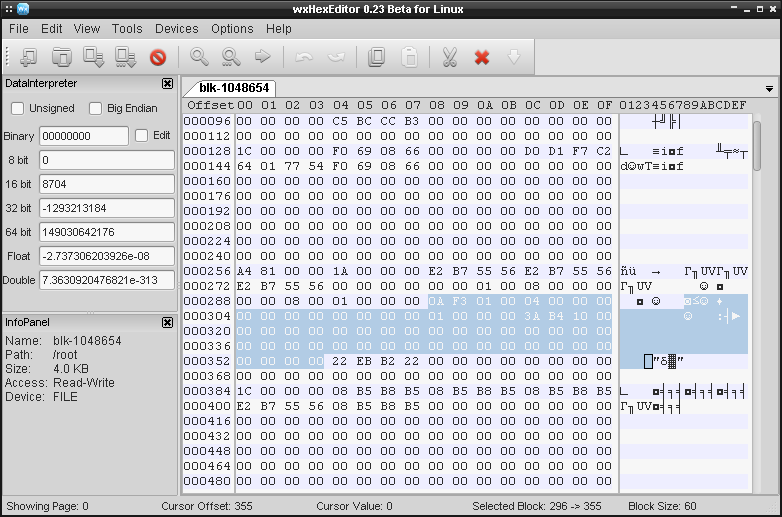
W sumie jest to pięć wpisów, każdy po 12 bajtów. Z tym, że pierwsze 12 bajtów to nagłówek, pozostałe bajty są w stanie opisać maksymalnie 4 zakresy bloków. Rzućmy zatem okiem na sam nagłówek. Mamy tam następujące bajty:
- 296-297: magiczna liczba (Magic number),
0xF30A= 62218 - 298-299: liczba zakresów
0x0001= 1 - 300-301: maksymalna liczba zakresów
0x0004= 4 - 302-303: głębokość drzewa (Depth of tree)
0x0000= 0 - 304-307: ID
0x00000000= 0
Gdy do systemu plików są dodawane nowe rzeczy lub zmianie ulegają stare, magiczna liczba może ulec
zmianie i w ten sposób wiemy, że mamy do czynienia z dwiema różnymi implementacjami zakresów. Liczba
zakresów odpowiada tej aktualnie zarezerwowanej przez plik i w tym przypadku, jako że plik nie jest
duży, to system plików jest w stanie go opisać za pomocą jednego zakresu. Maksymalna liczba zakresów
w ext4 wynosi póki co 4.
Wiemy zatem, że nasz plik ma jeden zakres, wobec czego musimy przebadać dodatkowo kolejne 12 bajtów, bo to one opisują ten zakres. Poniżej opis poszczególnych bajtów:
- 308-311: numer bloku logicznego (Logical block number),
0x00000000 - 312-313: liczba bloków w zakresie
0x0001 - 314-315: górne 16 bitów adresu fizycznego bloku
0x0000 - 316-319: dolne 32 bity adresu fizycznego bloku
0x0010B43A
Numer bloku logicznego informuje nas o tym gdzie ten zakres się zaczyna względem początku pliku. Ta
pozycja staje się o wiele bardziej ważna, gdy w grę wchodzi wiele zakresów. W tym przypadku mamy do
czynienia z jednym i ten numer zawsze będzie wskazywał na początek pliku. Liczba bloków w zakresie
określa ile bloków zajmuje dany plik. Tutaj mamy mały plik tekstowy i nie przekracza on 4096 bajtów,
zatem zajmuje tylko jeden blok. Ostatnie 6 bajtów mówi nam gdzie ten zakres się dokładnie zaczyna
podając nam adres pierwszego fizycznego bloku. Jako, że obecne systemy chcą równać wartości do 16,
32 i 64 bitów, to 48 bitowy adres bloku jest zapisywany w postaci dwóch wartości. Pierwsze 2 bajty
dają górne 16 bitów adresu bloku, a kolejne 4 bajty zawierają 32 bity niższego rzędu. W taki sposób
uzyskujemy adres bloku 0x00000010B43A, który odpowiada blokowi numer 1094714 .
Spróbujmy teraz usunąć z dysku ten plik cośmy go utworzyli zaraz na początku tego wpisu. Zróbmy to
standardowo przy pomocy polecenia rm :
# rm plik-tekstowy
W tej chwili może się wydawać, że plik jest usunięty ale nadal jesteśmy w stanie odczytać jego zawartość udowadniając tym samym, że usunęliśmy jedynie odnośnik do tego pliku nie zmieniając praktycznie jego zawartości. By odczytać taki usunięty plik, wpisujemy w terminal to poniższe polecenie:
# blkcat /dev/mapper/debian_laptop-root 1094714
Przykladowy plik tekstowy
Jak pokazuje ten ciekawy przykład, usuwanie plików praktycznie nic nie usuwa z dysku, zatem jesteśmy w stanie te pliki odzyskać. Wystarczy by przestrzeń, na której rezyduje dany plik, nie była ponownie nadpisana. Jeśli podłączyliśmy dysk do komputera i okazało się, że jakieś pliki zwyczajnie nam z niego zniknęły, to jak najszybciej przemontumy ten dysk w tryb tylko do odczytu (lub też go całkowicie odmontujemy) przy pomocy tego poniższego polecenia:
# mount -o remount,ro /dev/sdb
Jeżeli nie jesteśmy w stanie odmontować danej partycji, być może jest to za sprawą jakiegoś procesu, który w dalszym ciągu z niej korzysta. Wtedy powinniśmy taki proces zabić i spróbować ponownie. By ustalić, które procesy korzystają z tego systemu plików, wpisujemy w terminalu to poniższe polecenie:
# fuser -vukm /dev/mapper/kabi
Powyżej mamy określoną także flagę -k , która automatycznie zabije wszystkie wypisane procesy.
Czy trudno jest odzyskać usunięte pliki?
Jak mogliśmy zobaczyć na powyższym przykładzie, skasowane pliki w systemie plików ext4 w dalszym
ciągu są obecne na dysku. Co jednak w przypadku, gdy usuniemy plik i nie mamy do niego łatwego
odwołania, tak jak to było pokazane wyżej? W takiej sytuacji możemy posłużyć się paroma technikami.
Pierwsza z nich nazywa jest File Carving , gdzie
przeszukujemy ciąg bitów w poszukiwaniu dopasowań do wzorców pliku. Każdy plik zawiera nagłówek (i
bardzo często też stopkę), na podstawie którego to jesteśmy w stanie określić typ pliku analizując
jedynie same zera i jedynki. Ta metoda znajduje głównie zastosowanie w przypadku plików ciągłych,
gdzie dane następują po sobie i nie są w żaden sposób pofragmentowane. Jeśli mamy do czynienia z
pofragmentowanym plikiem, wtedy mogą się pojawić problemy z jego odczytem, lub też odczytanie
takiego pliku może w ogóle nie być możliwe. Inna metodą odzyskiwania danych jest analiza dziennika,
o ile dany system plików go udostępnia, a tak jest w przypadku ext4 . W tym przypadku, ciągłość
pliku nie ma większego znaczenia.
Odzyskiwanie plików metodą File Carving
By móc się bawić w odzyskiwanie plików, potrzebujemy odpowiednich narzędzi. W debianie musimy sobie
zainstalować pakiet sleuthkit oraz
foremost. W pakiecie sleuthkit mamy szereg narzędzi, w tym też
te, które zostały wykorzystane w doświadczeniu powyżej.
Zatem do dzieła. Weźmy sobie dla przykładu jakieś plik graficzny i umieśćmy go w przykładowym katalogu na nieużywanym systemie plików, po czym go skasujmy, tak by nie pozostał po nim żaden widoczny ślad, przykładowo:
# rm plik.pdf
Tutaj już nie znamy lokalizacji pliku, tak jak to miało miejsce w doświadczeniu, które
przeprowadziliśmy na samym początku. Jako, że jest to symulacja przypadkowego usunięcia ważnego
pliku, to musimy postępować tak jak to robilibyśmy gdyby faktycznie coś ważnego nam uległo
skasowaniu. Dlatego też pamiętajmy, by przemontować system plików w tryb tylko do odczytu.
Pamiętajmy też, by nigdy nie operować na faktycznych danych, a jedynie na backup'ie. W przypadku
partycji czy całych dysków musimy zrobić sobie kopię binarną takiego nośnika za pomocą dd ,
poniżej przykład:
# dd if=/dev/mapper/grafi of=/media/sdb/grafi.img
Mając zrobiony obraz, możemy na nim przeprowadzić poniższe czynności. Na początek przy pomocy fls
skanujemy system plików obrazu pod kątem usuniętych plików:
# fls -dr grafi.img | grep pdf
r/r * 12: plik.pdf
Liczba 12 to numer i-węzła, który musimy poddać analizie przy pomocy istat :
# istat grafi.img 12
inode: 12
Not Allocated
Group: 0
Generation Id: 3317407099
uid / gid: 0 / 0
mode: rrw-r--r--
Flags: Extents,
size: 0
num of links: 0
Inode Times:
Accessed: 2015-11-28 15:55:38.612100126 (CET)
File Modified: 2015-11-28 15:56:41.131424193 (CET)
Inode Modified: 2015-11-28 15:56:41.131424193 (CET)
File Created: 2015-11-28 15:55:38.612100126 (CET)
Deleted: 2015-11-28 15:56:41 (CET)
Direct Blocks:
Wyżej widzimy szereg informacji opisujących plik, gdzie mamy również pozycję Deleted , która nam
mówi, że ten plik został skasowany o określonej godzinie. Lista Direct Blocks jest pusta, zatem
nie mamy możliwości określenia, które bloki ten plik zajmował. Nas jednak bardziej interesuje grupa
bloków, którą w tym przypadku ma numer 0 . Odszukujemy jej opis przy pomocy fsstat :
# fsstat grafi.img
....
Group: 0:
Block Group Flags: [INODE_ZEROED]
Inode Range: 1 - 8192
Block Range: 0 - 32767
Layout:
Super Block: 0 - 0
Group Descriptor Table: 1 - 1
Group Descriptor Growth Blocks: 2 - 64
Data bitmap: 65 - 65
Inode bitmap: 73 - 73
Inode Table: 81 - 592
Uninit Data Bitmaps: 73 - 80
Uninit Inode Bitmaps: 81 - 88
Uninit Inode Table: 4177 - 8272
Data Blocks: 8289 - 32767
Free Inodes: 8029 (98%)
Free Blocks: 26535 (80%)
Total Directories: 6
Stored Checksum: 0xB0D7
...
Mamy tam podaną informację, że bloki danych znajdują się na pozycji 8289 - 32767 . Generalnie
można by przebadać cały ten obszar ale nas interesują jedynie te bloki, które nie są aktualnie
przydzielone, bo to w nich znajduje się nasz skasowany plik. By wyciągnąć te nieprzydzielone bloki,
posługujemy się blkls :
# blkls -A grafi.img 8289-32767 > free.img
# ls -al free.img
-rw-r--r-- 1 root root 89M 2015-11-28 16:58:06 free.img
Teraz już zostało nam jedynie przeszukać te 89 MiB danych przy pomocy foremost . Pamiętajmy, że
szukamy pliku .pdf :
# foremost -d -i free.img -o /media/sdb/odzysk -t pdf
Processing: free.img
Po chwili proces powinien się zakończyć, a w katalogu /media/sdb/odzysk/ powinny znajdować się
jakieś pliki:
# tree /media/sdb/odzysk/
/media/sdb/odzysk
├── audit.txt
└── pdf
└── 00017960.pdf
1 directory, 2 files
Plik wprawdzie nie ma starej nazwy ale za to został w pełni odzyskany i nadaje się do odczytu. Mamy
też plik audit.txt , który zawiera log z operacji. W tym powyższym przykładzie chcieliśmy odzyskać
tylko jeden plik. W przypadku, gdy plików byłoby więcej i obszar do przeszukania również byłby
znacznie większy, wtedy najlepiej przebadać cały obraz i w opcji -t dać all . W taki sposób
będziemy próbować odzyskać wszystkie skasowane pliki z całego obrazu.
Odzyskiwanie plików przy pomocy dziennika
System plików ext4 ma również dziennik, który loguje przeprowadzane operacje. Dzięki temu, system
jest w stanie podnieść się po awarii i odzyskać uszkodzone za jej sprawą pliki. Skoro system potrafi
odzyskać pliki na podstawie dziennika, to my też powinniśmy być w stanie to zrobić. Trzeba tylko
pamiętać, że wielkość dziennika zależy od rozmiaru partycji. Na tych większych partycjach rozmiar
dziennika przy standardowym formatowaniu sięga 128MiB. Nie jest to zatem dużo. Oczywiście, "dużo" to
pojęcie względne, bo to jakie dane będą logowane do dziennika zależy od konfiguracji umieszczonej w
pliku /etc/fstab . Zakładając, że mamy domyślne ustawienia, to wszystkie partycje są
skonfigurowane z opcją data=ordered , która ma na celu logowanie jedynie
metadanych z operacji bez załączania
faktycznych danych. W ten sposób 128MiB wydaje się być sporym zapasem.
Warto zaznaczyć, że większość kroków, które przeprowadzaliśmy w poprzednim rozdziale jest dokładnie
taka sama i nie będę ich tutaj opisywał ponownie. Generalnie rzecz biorąc, musimy utworzyć sobie
jakiś plik, następnie go skasować, po czym stworzyć obraz zawierający kopię partycji przy pomocy
dd . Tam dszukujemy oczywiście i-węzeł i patrzmy w fsstat na opis grupy zawierającej ten
i-węzeł:
# fls -rd grafi.img
r/r * 167: plik.mp3
# istat grafi.img 167
inode: 167
Not Allocated
Group: 0
...
# fsstat grafi.img
...
Group: 0:
Block Group Flags: [INODE_ZEROED]
Inode Range: 1 - 8192
Block Range: 0 - 32767
Layout:
Super Block: 0 - 0
Group Descriptor Table: 1 - 1
Group Descriptor Growth Blocks: 2 - 128
Data bitmap: 129 - 129
Inode bitmap: 145 - 145
Inode Table: 161 - 672
Uninit Data Bitmaps: 129 - 144
Uninit Inode Bitmaps: 145 - 160
Uninit Inode Table: 161 - 8352
Data Blocks: 8353 - 32767
Free Inodes: 7839 (95%)
Free Blocks: 24381 (74%)
Total Directories: 14
Stored Checksum: 0x26EF
Musimy ustalić pozycję i-węzeła. Każdy blok ma 4096 bajtów, każdy i-węzeł ma 256 bajtów i w sumie na
jeden blok składa się 16 i-węzłów. Tutaj mamy numerek 167 , zatem interesuje nas dziesiąty blok w
tablicy i-węzłów, który ma numer 171 (161+10). Tu właśnie do gry wchodzą logi z dziennika, które
musimy prześledzić w poszukiwaniu tego numeru 171 . By przejrzeć dziennik, w terminalu wpisujemy
jls podając w argumencie plik wcześniej utworzonego obrazu, przykładowo:
# jls grafi.img | grep -i " 171"
181: Allocated FS Block 171
191: Allocated FS Block 171
364: Allocated FS Block 171
368: Allocated FS Block 171
375: Allocated FS Block 171
Jest kilka wpisów dotyczących tego bloku. Im wcześniejsze tym większe prawdopodobieństwo, że plik ma
pierwotną formę, bo kolejne wpisy oznaczają, że został on w jakiś sposób zmieniony. Weźmy zatem wpis
numer 181 . Musimy podejrzeć cały ten blok w edytorze hexalnym. Możemy zwyczajnie wyświetlić ten
plik i wyjście przesłąć do xxd albo też możemy zapisać cały blok do pliku i wczytać go w
wxHexEditor . Ja sobie zapisałem wszystkie te powyższe wpisy do osobnych plików przy pomocy tego
poniższego polecenia:
# jcat grafi.img 8 181 > blok-171-1
Cyfra 8 jest zwykle numerem i-węzła dziennika systemu plików. Jest to standardowa wartość ale zawsze można ją ustalić w poniższy sposób:
# fsstat grafi.img | grep -i journal
...
Journal Inode: 8
Jako, że i-węzeł miał numer 167, to odszukujemy 7 (7/16) i-węzeł w edytorze. Pamiętajmy, że są one numerowane od zera, zatem jest to 1536 bajt. Dla pewności można też sprawdzić rozmiar pliku (offset od 4-7 bajta włącznie, przykładowo:
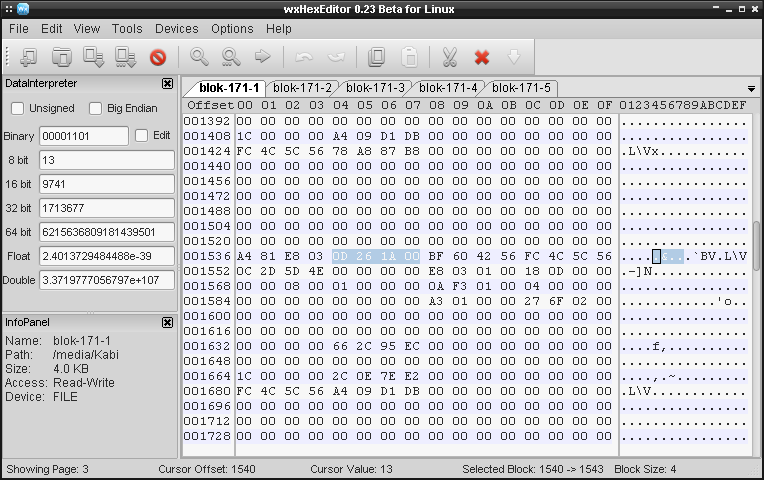
Powyższy zapis 0x001A260D odpowiada za 1713677 bajtów i faktycznie tyle miał ten plik .mp3 .
Zatem udało się odnaleźć odpowiedni blok. Teraz musimy jeszcze ten plik odzyskać.
Na początek patrzymy w adresy bloków. W tym przypadku mamy poniższy zapis:
0A F3 01 00 04 00 00 00 00 00 00 00
00 00 00 00 A3 01 00 00 27 6F 02 00
00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00
Pierwsza linijka odpowiada za nagłówek. Druga za pierwszy zakres bloków. Jako, że pozostałe mają same zera, to oznacza to, że plik jest opisany jednym zakresem bloków. Ustalmy teraz początek zakresu. Drugą linijkę dzielimy na kilka części:
00 00 00 00
A3 01
00 00
27 6F 02 00
Adres pierwszego bloku to te dwie ostatnie pozycje, zatem w zapisie hexalnym będzie to liczba
0x000000026f27 , czyli 159527 w zapisie dziesiętnym. Natomiast 0x01A3 to ilość kolejnych
bloków, które plik zajmuje, w tym przypadku jest to 419 . Możemy przemnożyć tę liczbę przez 4096
i uzyskamy wtedy rozmiar pliku, oczywiście w zaokrągleniu do pełnego bloku.
Znając początkowy blok oraz ilość następnych bloków, możemy ten plik teraz wykroić z dysku przy
pomocy blkls , podając zakres bloków:
# blkls -e grafi.img 159527-159946 > utracona.mp3
Jako, że kopiowaliśmy całe bloki, to plik wynikowy będzie troszeczkę większy niż ten oryginalny.
Możemy go oczywiście przyciąć przy pomocy dd . Rozmiar pliku uzyskaliśmy wcześniej z dziennika i
znamy go. Jest to 1713677 bajtów . Plik który uzyskaliśmy ma 1720320 . By teraz przyciąć ten
plik, wklepujemy w terminal to poniższe polecenie:
# dd if=./utracona.mp3 of=./utracona-przycieta.mp3 bs=1 count=1713677