Konfiguracja interfejsów IFB w linux'ie
Spis treści
Ten wpis również będzie poświęcony tematyce kontroli i kształtowania ruchu sieciowego w linux'ie, z tym, że ograniczymy się tutaj do konfiguracji interfejsów IFB. Działają one na podobnej zasadzie co interfejsy IMQ. Niewątpliwą zaletą interfejsów IFB jest fakt, że są one natywnie wspierane przez kernel linux'a, przez co ich obsługa jest dziecinnie prosta. Wadą jest z kolei to, że nie do końca damy radę kształtować ruch przychodzący do naszej maszyny. Tak czy inaczej, postaramy się skonfigurować te interfejsy i zobaczymy co z nich idzie wycisnąć.
Konfiguracja modułu ifb
Interfejsy IFB powstały w zamierzeniu jako alternatywa dla istniejących wcześniej interfejsów IMQ. Różnica między tymi dwoma mechanizmami jest taka, że IFB ma problemy z kształtowaniem ruchu docierającego do naszego komputera. Właściwie to nie jest w stanie tego zrobić. Możemy, co prawda, nadać określone limity zostawiając część łącza do dyspozycji innym procesom ale nie jesteśmy póki co w stanie tak kształtować ruchu przychodzącego, jak to się odbywa w przypadku tego wychodzącego. Nie jest jednak aż tak źle jak mogłoby się wydawać, zatem przejdźmy do konfiguracji odpowiednich modułów.
By móc operować na interfejsach IFB i przy ich pomocy rozgraniczyć pakiety wychodzące od
przychodzących, musimy załadować kilka modułów. Najlepiej to zrobić w pliku /etc/modules , skąd
te moduły będą ładowane automatycznie przy każdym rozruchu komputera. Na nasze potrzeby musimy tam
dopisać te poniższe linijki:
ifb
xt_connmark
sch_fq_codel
act_mirred
Ewentualną konfigurację dla tych modułów dodajemy do pliku /etc/modprobe.d/modules.conf . W tym
przypadku jest to:
options ifb numifbs=2
Jeśli chcemy załadować jakiś moduł w systemie ręcznie, musimy użyć do tego celu modprobe .
Rozdzielanie ruchu
Mając załadowane potrzebne moduły, możemy przejść do tworzenia kolejek z wykorzystaniem narzędzia
tc . Ruch, który przetacza się przez interfejs karty sieciowej w naszym komputerze jest
wymieszany. Musimy zatem rozdzielić dwa kanały download i upload oraz przekierować je na osobne
wirtualne interfejsy sieciowe ifb0 oraz ifb1 . Robimy to w poniższy sposób:
tc qdisc add dev eth0 parent root handle 1:0 htb
tc filter add dev eth0 parent 1:0 protocol ip prio 10 u32 match ip dst 0.0.0.0/0 flowid 1:1 action mirred egress redirect dev ifb0
tc qdisc add dev eth0 handle ffff: ingress
tc filter add dev eth0 parent ffff: protocol ip prio 10 u32 match ip src 0.0.0.0/0 flowid 2:1 action mirred egress redirect dev ifb1
Zarządzanie ruchem wychodzącym (egress)
Mając rozdzielony ruch, możemy teraz założyć kolejki. Najpierw zajmijmy się ruchem wychodzącym:
tc qdisc add dev ifb0 root handle 1: htb default 400 r2q 10
tc class add dev ifb0 parent 1:0 classid 1:1 htb rate 1000mbit ceil 1000mbit quantum 60000
tc class add dev ifb0 parent 1:1 classid 1:10 htb rate 980kbit ceil 980kbit
tc class add dev ifb0 parent 1:10 classid 1:200 htb rate 480kbit ceil 980kbit prio 0
tc class add dev ifb0 parent 1:10 classid 1:300 htb rate 200kbit ceil 980kbit prio 2
tc class add dev ifb0 parent 1:10 classid 1:400 htb rate 150kbit ceil 980kbit prio 4
tc class add dev ifb0 parent 1:10 classid 1:500 htb rate 150kbit ceil 980kbit prio 5
tc class add dev ifb0 parent 1:1 classid 1:20 htb rate 999mbit ceil 999mbit quantum 60000
tc class add dev ifb0 parent 1:20 classid 1:1000 htb rate 99mbit ceil 999mbit prio 1 quantum 60000
Pakietami wyjściowymi możemy sterować przez iptables z celami -j MARK i -j CLASSIFY oraz przy
pomocy cgroups. My tutaj
będziemy dla przykładu markować pakiety w iptables . Do tego celu musimy utworzyć kilka regułek w
tablicy mangle , przykładowo:
iptables -t mangle -N qos_egress
iptables -t mangle -N qos_ingress
iptables -t mangle -A PREROUTING -j CONNMARK --restore-mark
iptables -t mangle -A PREROUTING -m mark ! --mark 0 -j ACCEPT
iptables -t mangle -A PREROUTING -i bond0 -j qos_ingress
iptables -t mangle -A PREROUTING -j CONNMARK --save-mark
iptables -t mangle -A POSTROUTING -j CONNMARK --restore-mark
iptables -t mangle -A POSTROUTING -m mark ! --mark 0 -j ACCEPT
iptables -t mangle -A POSTROUTING -o bond0 -j qos_egress
iptables -t mangle -A POSTROUTING -j CONNMARK --save-mark
Te powyższe reguły zlikwidują niepotrzebną pracę przy oznaczaniu pakietów, bo marki będą aplikowane
na poszczególne połączenia, a nie na pojedyncze pakiety. Musimy jednak dodać kilka dodatkowych
reguł, które będą oznaczać pakiety mające mark=0 . Zwykle są to pakiety od nowych połączeń.
Poniżej kilka przykładów:
iptables -t mangle -A qos_egress -s 192.168.0.0/16 -d 192.168.0.0/16 -j MARK --set-mark 10
iptables -t mangle -A qos_egress -s 192.168.0.0/16 -d 192.168.0.0/16 -j RETURN
iptables -t mangle -A qos_egress -m owner --gid-owner p2p -j MARK --set-mark 5
iptables -t mangle -A qos_egress -m owner --gid-owner p2p -j RETURN
iptables -t mangle -A qos_egress -m owner --gid-owner morfik -j MARK --set-mark 2
iptables -t mangle -A qos_egress -m owner --gid-owner morfik -j RETURN
iptables -t mangle -A qos_egress -m owner --gid-owner root -j MARK --set-mark 3
iptables -t mangle -A qos_egress -m owner --gid-owner root -j RETURN
iptables -t mangle -A qos_egress -s 192.168.10.0/24 -j MARK --set-mark 4
iptables -t mangle -A qos_egress -s 192.168.10.0/24 -j RETURN
Oznaczanie pakietów robimy w osobnych łańcuchach. W przypadku ruchu wychodzącego jest to łańcuch
qos_egress . Chodzi generalnie o to, że po tym jak pakiet trafi w regułę, która nada mu
oznaczenie, to nie kończy on przemierzać następnych reguł w danym łańcuchu. Dlatego do markowania
wykorzystujemy osobne łańcuchy, które są wywoływane z głównych łańcuchów iptables . Reguły z -j RETURN zwracają pakiety do łańcucha nadrzędnego i tam pakiet sobie leci już dalej. Skracają one w
ten sposób drogę pakietu przez filtr, co przekłada się na szybsze jego przetworzenie.
Musimy jeszcze powiązać reguły iptables z filtrem tc . Do tego celu potrzebujemy te poniższe
reguły:
tc filter add dev ifb0 protocol ip parent 1:0 prio 5 handle 2 fw classid 1:200
tc filter add dev ifb0 protocol ip parent 1:0 prio 90 handle 3 fw classid 1:300
tc filter add dev ifb0 protocol ip parent 1:0 prio 20 handle 4 fw classid 1:400
tc filter add dev ifb0 protocol ip parent 1:0 prio 10 handle 5 fw classid 1:500
tc filter add dev ifb0 protocol ip parent 1:0 prio 100 handle 10 fw classid 1:1000
I to w zasadzie tyle, przynajmniej jeśli chodzi o ruch wychodzący. Pamiętajmy, by pilnować oznaczeń,
tak by 5 fw pasował do -j MARK --set-mark 5 w iptables . Podobnie z classid 1:500 .
Zarządzanie ruchem przychodzącym (ingress)
W przypadku interfejsów IFB mamy nieco ograniczone pole manewru i nie wszystkie mechanizmy oznaczeń
pakietów jak i ich kolejkowania działają w przypadku ruchu docierającego do danego hosta w sieci.
Podobnie jak w przypadku ruchu wychodzącego, musimy stworzyć kilka kolejek dla pakietów
przychodzących, które będą kierowane do wirtualnego interfejsu ifb1 :
tc qdisc add dev ifb1 root handle 2: htb default 400 r2q 100
tc class add dev ifb1 parent 2:0 classid 2:1 htb rate 1000mbit ceil 1000mbit quantum 60000
tc class add dev ifb1 parent 2:1 classid 2:10 htb rate 14500kbit ceil 14500kbit
tc class add dev ifb1 parent 2:10 classid 2:200 htb rate 4500kbit ceil 14500kbit prio 0
tc class add dev ifb1 parent 2:10 classid 2:300 htb rate 3000kbit ceil 14500kbit prio 2
tc class add dev ifb1 parent 2:10 classid 2:400 htb rate 4500kbit ceil 14500kbit prio 4
tc class add dev ifb1 parent 2:10 classid 2:500 htb rate 2500kbit ceil 14500kbit prio 5
tc class add dev ifb1 parent 2:1 classid 2:20 htb rate 985mbit ceil 985mbit quantum 60000
tc class add dev ifb1 parent 2:20 classid 2:1000 htb rate 85mbit ceil 985mbit prio 1 quantum 60000
Teraz zaczynają się problemy, bo musimy napisać odpowiednie regułki dla tc filter , który
przekieruje część ruchu do odpowiednich kolejek. Operowanie na filtrze tc nie należy do prostych
rzeczy. W zrozumieniu składni selektora u32 mogą przydatne okazać się te linki: man
tc-ematch oraz man
tc-u32. Tak czy inaczej załóżmy, że chcemy dać
na osobną kolejkę ruch http (port 80) i https (port 443). Piszemy zatem regułki uwzględniające porty
źródłowe 80 i 443:
tc filter add dev ifb1 parent 2:0 protocol ip prio 10 u32 match ip sport 80 0xffff classid 2:300
tc filter add dev ifb1 parent 2:0 protocol ip prio 10 u32 match ip sport 443 0xffff classid 2:300
Pamiętajmy też, by odpowiednio ustawić priorytet ( prio ) dla tego filtra. Im niższy numer, tym
wyżej zlokalizowany będzie ten filtr w tablicy filtrów tc . Na kilka słów wyjaśnienia zasługuje
jeszcze maska 0xffff dla portów. Jest ona podobna do tej dla adresów IP. W przypadku ustawienia
ffff, oznacza to tylko jeden port. Można oczywiście ustawić zakres portów przez zmianę tej maski.
Jak widać jest to trochę skomplikowane ale dla naszych potrzeb spokojnie wystarczą te cztery
parametry: src , dst , sport , dport i protocol . By sprecyzować adres IP zamiast portu,
wstawiamy dst 222.28.1.40/32 w miejsce sport 80 0xffff. Reguła będzie odnosić się do adresu
docelowego 222.28.1.40. Bu ustawić zakres adresów, wystarczy zmienić maskę, podobnie jak w przypadku
portów. Z kolei przy protocol możemy wydzielić cały protokół w oparciu o ich
numerki.
Teraz odpalmy jakąś przeglądarkę internetową, np. Firefox'a, w celach testowych. Pakiety powinny wędrować do kolejek 1:200 oraz 2:300. Poniżej przykład:
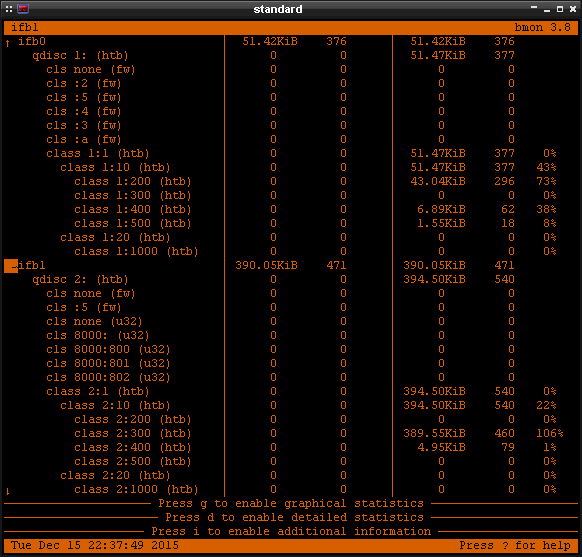
Statystyki ruchu
Wyżej wykorzystaliśmy narzędzie bmon do pokazania w czasie rzeczywistym do jakich kolejek trafiają
pakiety. Czasami przy pisaniu reguł mogą pojawić się błędy i pakiety nie będą trafiać tam gdzie
byśmy sobie tego życzyli. Dlatego też warto zaznajomić się się nieco ze statystykami, które
potrafią pokazać min. to ile trafień ma dana reguła. Poniżej kilka poleceń, które pokazują rozpiskę
aktualnej konfiguracji.
Inforamcje o qdisc:
# tc -d -s qdisc show dev ifb1
Informacje o filtrach:
# tc -s -d -p filter show dev ifb1
Informacje na temat klas:
# tc -s -d class show dev ifb1
Jeśli komuś niezbyt odpowiada zapis tekstowy i wolałby zobaczyć rozpiskę w postaci jakiegoś wykresu, to istnieje narzędzie tcviz, które na podstawie tych wszystkich literek i cyferek zrobi nam miły dla oka obrazek.