Jak zdiagnozować kernel OOPS
Spis treści
Kernel linux'a, jak każdy inny program, podczas swojego działania może napotkać nieprzewidzianą przez programistów sytuację. W przypadku zwykłych aplikacji, pewne błędy krytyczne mogą doprowadzić do "naruszenia ochrony pamięci", co szerzej jest znane jako segfault. W przypadku wystąpienia tego błędu, proces zwykle jest unicestwiany. Co jednak w przypadku kernela? Odpowiedź jest prosta: kernel panic, czyli panika kernela, która pozostawia system w stanie braku jakichkolwiek oznak życia. Są jednak pewne błędy, z którymi kernel jest w stanie sobie poradzić i odzyskać sprawność w mniejszym lub większym stopniu. Te błędy są nazywane kernel OOPS. W tym wpisie postaramy się przeanalizować przykładowy OOPS i zobaczymy czy uda nam się ustalić przyczynę zaistniałego problemu.
Jak zalogować komunikaty OOPS kernela
By zabrać się za diagnostykę komunikatów kernela w celu ustalenia przyczyn problemu, musimy
odpowiednio skonfigurować sobie system. Na sam początek rzućmy okiem na parametry kernela, które
możemy ustawić za pomocą narzędzia sysctl . Z parametrami odpowiedzialnymi za kernel panic i
kernel OOPS, mieliśmy już
wcześniej do czynienia. Nas najbardziej interesuje parametr kernel.panic_on_oops , który musi być
ustawiony na 0 . Zapobiegnie to powieszeniu się kernela. Nie oszukujmy się jednak, bo w sporej
części przypadków trzeba będzie ponownie uruchomić system wkrótce po wystąpieniu tego OOPS'a.
Niemniej jednak, cały komunikat błędu powinien zostać z powodzeniem zalogowany do pliku. W taki
sposób będziemy w stanie wydobyć ten błąd z plik i poddać go analizie w późniejszym czasie.
W zasadzie to ustawienie nam powinno wystarczyć. Niemniej jednak, warto też powiadomić zespół kernela o fakcie wystąpienia błędu, a do tego mamy przeznaczone odpowiednie oprogramowanie.
Pakiet kerneloops ułatwi diagnostykę OOPS'ów
W debianie jest dostępny pakiet kerneloops , który monitoruje log i potrafi nam zgłosić informacje
o wystąpieniu ewentualnych błędów kernela. Nie jest to oczywiście żaden wyczyn ale bardzo przyjazna
rzecz w przypadku, gdy nie posiadamy konsoli na pulpicie i nie podglądamy logów systemowych w czasie
rzeczywistym. To oczywiście nie jedyna funkcjonalność, którą ten pakiet dostarcza. Umożliwia on
także zaprogramowanie systemu w taki sposób, by te wszystkie kernel OOPS były wysyłane
automatycznie do analizy przez deweloperów kernela.
Po zainstalowaniu w/w pakietu, w systemie zostanie odpalony demon kerneloops , który będzie
monitorował wskazany przez nas plik. Ścieżkę do pliku jak i szereg innych aspektów pracy tego demona
możemy skonfigurować w pliku /etc/kerneloops.conf , przykładowo:
allow-submit = ask
allow-pass-on = yes
submit-url = http://oops.kernel.org/submitoops.php
log-file = /var/log/kern.log
W pewnych sytuacjach, taki log błędu może zawierać pewne dodatkowe informacje, które zostaną
zalogowane przez system. Zwykle mogą to być komunikaty, które pojawiły się bezpośrednio przed
wystąpieniem kernel OOPS'a, lub też i chwilę po nim. Mi się jednak to nie przytrafiło i ten
mechanizm logował jedynie same komunikaty błędów kernela. Niemniej jednak, trzeba mieć na uwadze, że
nie zawsze tak może być i dobrze jest ustawić opcję allow-submit na ask . W ten sposób będziemy
pytani o zgodę przed wysłaniem komunikatów. Będzie nam też potrzebny pakiet kerneloops-applet ,
który nam wyświetli monit, gdzie min. będziemy mogli się zapoznać z treścią wiadomości, którą
zamierzamy przesłać na serwer kernela. Poniżej przykładowa notyfikacja zgłaszająca kernel OOPS'a:
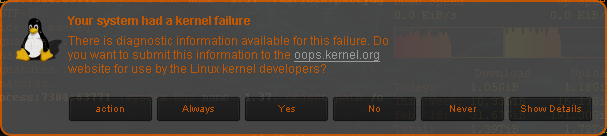
Inną ważną rzeczą jest ustawienie odpowiedniej ścieżki w log-file . Jeśli posiadamy systemd, to
mamy pewien problem. Systemd ma swój plik kontenera, którego demon kerneloops nie przeczyta.
Musimy zaprzęgnąć do pracy rsyslog i wydzielić przy jego pomocy wszystkie komunikaty kernela i
przekierować je do wskazanego wyżej pliku. Demon rsyslog jest w stanie logować te same komunikaty
co journal systemd i w zasadzie nie jest potrzebna żadna dodatkowa konfiguracja. Nam jednak zależy
jedynie na komunikatach kernela, dlatego też możemy wykomentować szereg rzeczy w pliku
/etc/rsyslog.conf . Uwagę należy natomiast zwrócić na te dwie poniższe linijki:
...
$ModLoad imklog
...
kern.* /var/log/kern.log;RSYSLOG_TraditionalFileFormat
...
Pierwsza z nich ładuje moduł
imklog, który będzie w
stanie podebrać logi zwracane przez kernel. Druga zaś przekieruje te komunikaty do pliku
/var/log/kern.log , na który będzie operował demon kerneloops . Ważne jest by przed ścieżką tego
pliku nie dodawać znaku - odpowiadającego za funkcję sync . W taki sposób komunikaty nie będą
trafiać do pliku zbiorczo co pewien interwał czasu, tylko za każdym razem, kernel wyśle nową linijkę
wiadomości.
Analiza logu kernel OOPS
Nie ma dla nas zabardzo znaczenia czy komunikat OOPS został zalogowany przez journal systemd, czy odbyło się to za sprawą rsyslog'a. Grunt, że mamy cały komunikat, który możemy poddać analizie. Nie jestem raczej żadnym specjalistą w tej dziedzinie i większość wiadomości jest dla mnie dość tajemnicza ale część komunikatu udało mi się rozkodować.
Każdy OPPS zaczyna się od typu błędu:
BUG: unable to handle kernel NULL pointer dereference at 0000000000000050
Linijka z IP (Instruction Pointer) pokazuje problematyczną instrukcję, która była wykonywana w
chwili wystąpienia błędu. Mamy tam informacje na temat bajtu offset'u, na którym był procesor
(+0x23) jak i długości samej funkcji /0x160 (wartości w HEX):
IP: [<ffffffff81296183>] apparmor_file_open+0x23/0x160
Niżej mamy Page Global Directory (PGD) ale na dobrą sprawę nigdzie nie mogłem znaleźć informacji na temat tego jak zinterpretować jej wartość:
PGD 0
Następnie mamy określony kod błędu w HEX (0000) oraz ilość jego wystąpień ([#1]). Ważne jest by
poddawać analizie tylko i wyłącznie pierwszy błąd, gdyż kolejne błędy mogą być wynikiem tego
pierwszego:
Oops: 0000 [#1] SMP
Niżej zaś mamy informację o załadowanych modułach kernela (przycięte dla czytelności):
Modules linked in: fuse nfnetlink_queue nfnetlink_log bluetooth [...]
Mamy też numer procesora ( 0 ), na którym doszło do zdarzenia. Jest też PID procesu (129320) ,
który wywołał OOPS'a. Dalej mamy flagi skażenia (Tainted). Może być ich
kilka
w zależności od konfiguracji kernela. Jest też informacja o numerku kernela, architekturze i
dystrybucji linux'a:
CPU: 0 PID: 129320 Comm: Xorg Tainted: G O 4.3.0-1-amd64 #1 Debian 4.3.5-1
Poniżej znajduje się krótki opis flag, które mogą się pojawić w powyższej linijce:
Gpojawi się w przypadku, gdy wszystkie załadowane moduły są na licencji GPL. Gdy któryś z załadowanych modułów jest własnościowy lub taki, którego licencja nie jest kompatybilna z GPL, to zostanie ustawiona flagaP.Fwskazuje czy jakiś moduł został załadowany siłowo.Swskazuje, że OOPS wystąpił w kernelu SMP na maszynach niekompatybilnych z SMP (2 i więcej procesorów).Rwskazuje, że jakiś moduł został siłowo wyładowany.Mwskazuje, że procesor zgłosił błąd Machine Check Exception, tj. problemy ze sprzętem.Bwskazuje, że funkcja page-release odnalazła odwołanie do złej strony lub też do pewnych nieoczekiwanych jej flag.Upojawia się w przypadku, gdy użytkownik (lub jakaś jego aplikacja) wyraźnie zgłosił, by ta flaga skażenia została ustawiona.Dwskazuje, że kernel zdechł niedawno, tj. pojawił się jakiś inny OOPS czy błąd.Awskazuje na nadpisanie tablicy ACPI.Wwskazuje, że kernel wysłał już wcześniej jakieś ostrzeżenie.Cwskazuje, że został załądowany jakieś sterownik, który nie jest jeszcze gotowy do włączenia go do głównego drzewa kernela (staging driver).Iwskazuje, że kernel działa w obliczu poważnych błędów związanych z firmware danej platformy, np. BIOS'u.Owskazuje, że został załadowany zewnętrzny moduł (out-of-tree).Ewskazuje, że niepodpisany moduł został załadowany w kernel supporting module signature.Lwskazuje, że softlocpup zdarzył się wcześniej w systemie.Kwskazuje, że kernel był łatany na żywca (live patching).
W logu mamy także informację na temat nazwy sprzętu jak i wersji i daty jego BIOS'u:
Hardware name: Hewlett-Packard HP G62 Notebook PC /1439, BIOS F.48 11/09/2011
Nie mam za bardzo pojęcia jak zinterpretować tę poniższą linijkę:
task: ffff8800766e8c80 ti: ffff8800735f0000 task.ti: ffff8800735f0000
Zrzut stanu rejestrów procesora w chwili pojawienia się OOPS'a:
RIP: 0010:[<ffffffff81296183>] [<ffffffff81296183>] apparmor_file_open+0x23/0x160
RSP: 0018:ffff8800735f3cb0 EFLAGS: 00010246
RAX: 0000000000000000 RBX: ffffffff81a8eae0 RCX: 0000000200000000
RDX: 0000000300000000 RSI: ffff880007338e80 RDI: ffff880002955a00
RBP: ffff880002955a00 R08: ffff88007239f018 R09: ffff88006d6f8b60
R10: ffff88007239f018 R11: 0000000000000000 R12: ffff880007338e80
R13: ffff880076f36570 R14: ffff8800735f3df0 R15: ffff880002955a10
FS: 00007fbdf323da00(0000) GS:ffff880075a00000(0000) knlGS:0000000000000000
CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
CR2: 0000000000000050 CR3: 00000000770f5000 CR4: 00000000000006f0
Jest też także zrzut stanu stosu kernela w chwili błędu:
Stack:
ffff8800735f3da0 0000000033401090 ffffffff81a8eae0 ffff880002955a00
ffffffff81262366 ffff880002955a00 ffff880007338e80 0000000000000000
ffffffff811cb0cc ffff8800722c0858 0000000000008000 0000000000000000
Dalej mamy "Call Trace" będący listą funkcji, które proces wykonywał w chwili wystąpienia błędu.
Zwykle tutaj będziemy mieć wartości numeryczne, które są kompletnie nieużyteczne dla celów
debug'owania. Wszystko przez fakt, że te wartości są unikatowe dla danego kernela. Jedyną drogą do
rozszyfrowania tych adresów jest Symbol Map , który w debianie znajduje się w katalogu
bootloader'a, przykładowo /boot/System.map-4.4.0-1-amd64 . To właśnie za jego sprawa można
zmapować adresy na faktyczne nazwy funkcji, co wygląda mniej więcej tak:
Call Trace:
[<ffffffff81262366>] ? security_file_open+0x36/0x90
[<ffffffff811cb0cc>] ? do_dentry_open+0x10c/0x2d0
[<ffffffff811dad5a>] ? path_openat+0x1da/0x1260
[<ffffffff811dcf71>] ? do_filp_open+0x91/0x100
[<ffffffff812e652e>] ? memzero_explicit+0xe/0x10
[<ffffffff813d705c>] ? extract_entropy_user+0x11c/0x190
[<ffffffff811cc669>] ? do_sys_open+0x139/0x220
[<ffffffff81586432>] ? system_call_fast_compare_end+0xc/0x67
Code: 0f 1f 84 00 00 00 00 00 66 66 66 66 90 55
53 48 83 ec 10 65 48 8b 04 25 28 00 00 00
48 89 44 24 08 31 c0 48 8b 47 18 48 8b 40
68 <48> f7 40 50 00 00 00 80 0f 85 14 01
00 00 65 48 8b 04 25 00 be
RIP [<ffffffff81296183>] apparmor_file_open+0x23/0x160
RSP <ffff8800735f3cb0>
CR2: 0000000000000050
---[ end trace 51041b81b9803d4c ]---
W linijce z Code: mamy szereg bajtów (zapis HEX). Część z tych bajtów poprzedza aktualny wskaźnik
instrukcji (IP), a cześć występuje po nim. Natomiast aktualny wskaźnik instrukcji jest ujęty zwykle
w < > lub ( ) . Dla lepszej czytelności ta linijka została podzielona na szereg krótszych.
W celu głębszej analizy kernel OOPS wykorzystuje się
GDB. Można także skorzystać z narzędzia crash . Są
one wykorzystywane w celu odnalezienia części kodu w źródłach kernela, który spowodował błąd. W tym
przypadku nie będziemy się zbytnio zagłębiać w te rzeczy, bo tak na dobrą sprawę jeszcze tego nie
potrafię. Natomiast jeśli chodzi o przybliżoną diagnostykę problemów, to widzimy wyraźnie, że coś
jest nie tak z AppArmor'em. Błędy są zgłaszane automatycznie, zatem deweloperzy kernela zostaną o
nich powiadomieni i miejmy nadzieję, że poprawią te niedogodności jak najszybciej.