Kodowanie nazw plików i jego zmiana
Spis treści
Chciałem dziś wypakować sobie kilka plików, które były zebrane w paczkę .zip . Problem w tym, że
ta osoba, co te pliki pakowała, najwyraźniej robiła to na widnowsie no i nie użyła standardowego
kodowania, które jest wykorzystywane na każdym innym systemie, tj. UTF-8. Wobec tego, wszystkie
pliki mają w swoich nazwach znaczek � w miejscu polskich liter. Jako, że tych plików jest dość
dużo, to odpada ręczna edycja nazw i trzeba pomyśleć nad jakimś innym rozwiązaniem. Zmiana
kodowania nazw plików, to nie jest to samo co zmiana kodowania zawartości tych
plików. Na szczęście w
linux'ie mamy do dyspozycji narzędzie convmv , które jest w stanie, jak sama nazwa mówi, przepisać
nazwy plików ustawiając przy tym odpowiednie kodowanie.
Odpowiednie kodowanie nazw plików
Mając na swoim dysku pliki z krzaczkami, oznacza to oczywiście tyle, że kodowanie nazw tych plików nie pasuje do tego ustawionego w systemie. Jako, że linux'y wykorzystują kodowanie UTF-8, to logiczne jest, że te nazwy zostały zakodowane innym systemem. Jakim? To jest dobre pytanie. Niestety ciężko jest na nie odpowiedzieć i raczej nie ma narzędzia, który by nam to powiedziało. Przynajmniej ja na takie jeszcze nie natrafiłem. Jako, że osoba, która pakowała pliki, również posługuje się językiem polskim, oznacza to, że ilość możliwych kodowań możemy dość znacznie ograniczyć. W Polsce wykorzystywane są zwykle trzy z nich: ISO-8859-2, Windows-1250 oraz UTF-8. Zostają nam zatem te dwa pierwsze i jest wielkie prawdopodobieństwo, że którymś z nich zakodowane są nazwy tych plików.
Zmiana kodowania nazw plików
W linux'ie jest kilka narzędzi, które są w stanie zmienić kodowanie nazw plików. Jednym z bardziej
użytecznych i prostych w obsłudze jest convmv . To narzędzie jest standardowo dostępne w debianie
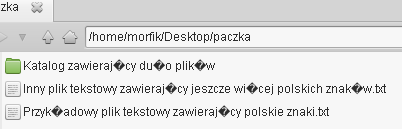
w pakiecie o tej samej nazwie, zatem nie powinno być problemów z jego instalacją. Rzućmy teraz okiem
na ten wypakowany katalog, który zawiera nieprawidłowe kodowanie nazw plików. Wygląda on mniej
więcej tak:
Odpalamy teraz terminal i przechodzimy do tego katalogu. Narzędzie convmv wymaga podania dwóch
parametrów. Chodzi oczywiście o kodowanie wejściowe ( -f ) i kodowanie wyjściowe ( -t ).
Kodowanie wyjściowe ustawiamy na UTF-8 , natomiast w przypadku wejściowego musimy robić to metodą
prób i błędów. Standardowo convmv nie dokona żadnych zmian w nazwach plików, no chyba, że podamy
dodatkowo parametr --notest . Zatem możemy sprawdzić dowolne kodowanie i jeśli natrafimy na to,
które poprawnie wyświetli nazwy plików, to wtedy możemy tę opcję dodać i tym samym przepisać nazwy
plików. W tym przypadku spróbowałem kodowania ISO-8859-2 i okazało się, że to nim właśnie zostały
zadokowane nazwy tych plików:
$ convmv -f iso-8859-2 -t UTF-8 ./*
Starting a dry run without changes...
mv "./Inny plik tekstowy zawieraj±cy jeszcze wiej polskich znak.txt" "./Inny plik tekstowy zawierający jeszcze więcej polskich znaków.txt"
mv "./Katalog zawieraj±cy du¿o plik" "./Katalog zawierający dużo plików"
mv "./Przyk³adowy plik tekstowy zawieraj±cy polskie znaki.txt" "./Przykładowy plik tekstowy zawierający polskie znaki.txt"
No changes to your files done. Would have converted 3 files in 0 seconds.
Use --notest to finally rename the files.
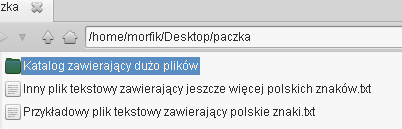
Widzimy wyraźnie, że nazwy wynikowe nie zawierają krzaków. Zatem jest to odpowiednie kodowanie i
możemy teraz dodać do polecenia parametr --notest i masowo zmienić nazwy plików w tym katalogu.
Efekt jest mniej więcej taki jak na fotce poniżej: